
Generated using Quiver (svg for fonts, graphics) + Cursor (animation)
Since the early days of digital design, one requirement has always remained constant: good design needs to work across every context in which it’s used. Different screens, sizes, formats and surfaces all demand the same thing: underlying structure and composability, not just visual polish.
Vector graphics (SVGs) are how that structure is encoded. They show up everywhere: the logo on your neighborhood café, diagrams in textbooks and research papers, icons in product interfaces, lightweight animations on the web, and the media kits brands reuse across campaigns. In each case, what matters isn’t just how the graphic looks once, but how reliably it can be reused, edited, and scaled.
The market has made something clear: structure in visual generation is no longer a niche concern, it’s a frontier capability most models are not yet great at. The launch of Gemini 3.1 Pro shows the world that developers and designers don’t just want pixels. They want editable, animatable, production-ready graphics. SVG generation has moved from research curiosity to product expectation now.
AI has made remarkable progress in producing pixels, but structure is a different problem. A popular read in the AI community is Simon Willison’s “pelican riding a bicycle” test. It started as a joke benchmark, but captures something true. Even when models produce images that look plausible, they often fail to preserve relationships between elements. Limbs merge, objects collapse, and compositional intent gets lost.
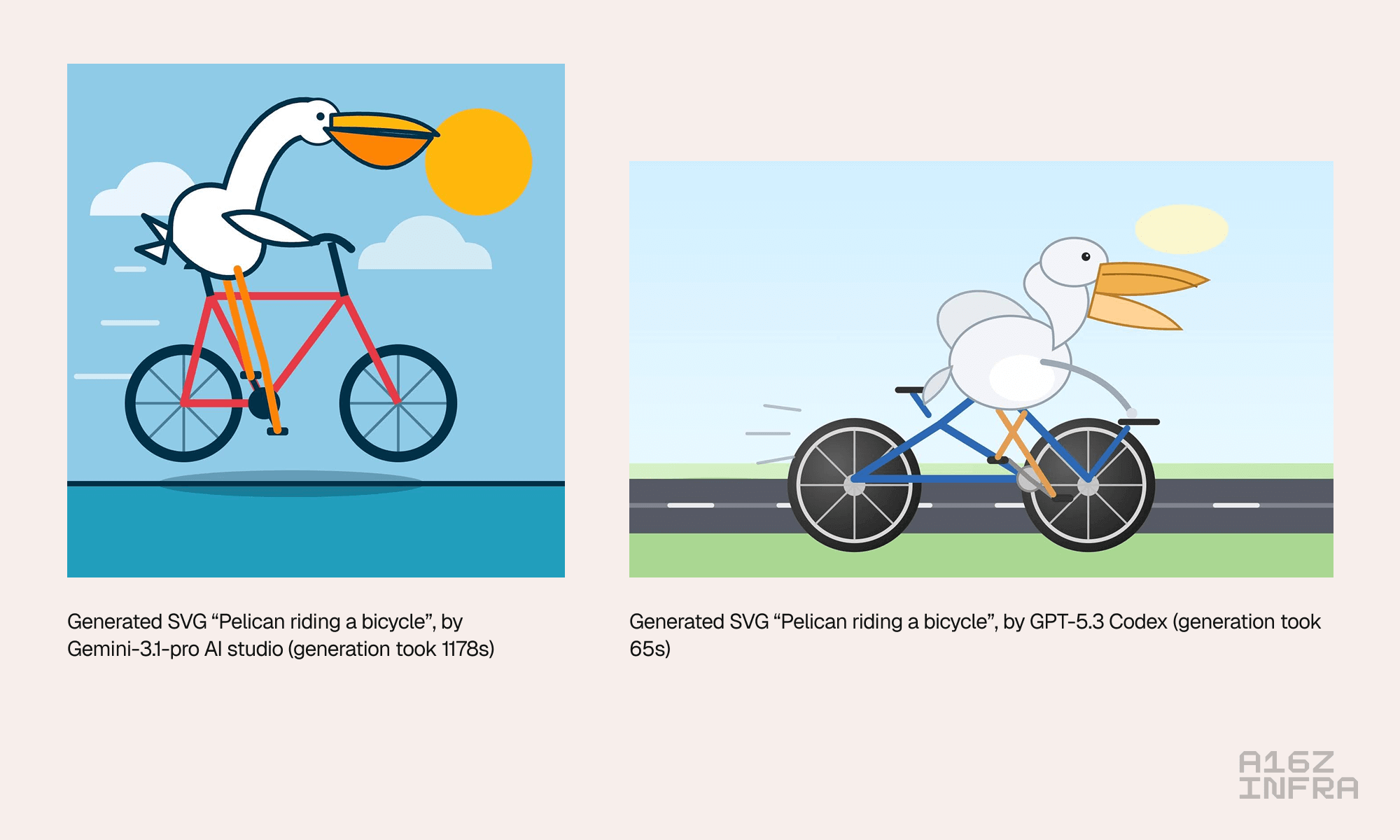
An SVG has to be explicit. It must encode hierarchy, grouping, reuse, and spatial relationships. A model may be able to render a mess of flattened pixels, but until it understands structure and composition, its output can’t be meaningfully edited, animated, or reused. What’s amusing in a pixel image is a hard blocker in real design workflows. Try changing a color system. Try isolating a layer. Try extending an animation. That’s when the structure either holds or collapses.
This is the gap Quiver is building to close.

Quiver is building a leading model for vector graphics, enabling high-fidelity, symbolic SVG generation across images, icons, illustrations, and even fonts. Their core insight is simple but powerful: While SVGs are traditionally thought of as an image format, they’re also visual code. Generating them well requires models that reason about both aesthetics and structure.
That perspective naturally extends beyond icons and illustrations. Fonts, for example, are vector systems. Each glyph is a structured composition of paths that must share geometry, rhythm, and style. When a model generates a typeface, it isn’t just drawing letters — it’s defining a coherent visual language that can be reused, extended, and animated.

Quiver generated fonts based on a16z’s existing design
The same principle applies to animation. In the era of coding agents, any agent can emit SVG markup. Quiver can be called by those agents inside environments like Cursor or Gemini AI Studio, to generate animation-ready, structurally coherent SVG that behaves like a real component:
At the center of Quiver is Joan Rodríguez, one of the top researchers globally working on SVG generation. Joan led the creation of StarVector, one of the first models to generate structured, editable SVGs rather than raster approximations. He later introduced Reinforcement Learning from Rendering Feedback (RLRF), a novel training approach that closes the loop between symbolic SVG code and how it actually renders visually.
Joan’s boots-on-the-ground experience shipping real products impressed us. StarVector was released with open weights, adopted by technical users, and quickly found traction in areas like scientific figures, diagrams, and vector art. It’s already accumulated thousands of GitHub stars and interest from enterprise users. Now, the team has released a flagship SVG model focused on producing cleaner structure, more faithful geometry, and outputs that are designed to be edited, animated, and reused long after the initial render.
We believe Quiver’s work represents foundational infrastructure for how visual assets will be created in the future. Just as code generation required models that understood syntax and semantics, design generation will require models that treat visuals as structured systems. When vector graphics are treated as code, they become something models can reason about and modify directly. This makes generated visuals easier to refine, restyle, and reuse, opening the door to workflows that go far beyond one-off generation.
We’re excited to partner with Joan and the team as they build Quiver, and we’re thrilled to be leading their seed round. The opportunity to reinvent how vector graphics are generated, edited, and scaled is just beginning. If you’re interested in shaping the future of visual code, you can sign up to try Quiver here.

- Monopolies vs Oligopolies in AI Martin Casado
- Investing in Deeptune Marco Mascorro and Martin Casado
- What’s Missing Between LLMs and AGI – Vishal Misra & Martin Casado Martin Casado and Vishal Misra
- Investing in Nexthop AI Raghu Raghuram, Shangda Xu, and Guido Appenzeller
- I Built TetrisBench, Where LLMs Compete at Playing Tetris. Here’s What I Found. Yoko Li

- Monopolies vs Oligopolies in AI Martin Casado
- Investing in Deeptune Marco Mascorro and Martin Casado
- What’s Missing Between LLMs and AGI – Vishal Misra & Martin Casado Martin Casado and Vishal Misra
- Investing in Nexthop AI Raghu Raghuram, Shangda Xu, and Guido Appenzeller
- I Built TetrisBench, Where LLMs Compete at Playing Tetris. Here’s What I Found. Yoko Li

- Monopolies vs Oligopolies in AI Martin Casado
- Investing in Deeptune Marco Mascorro and Martin Casado
- What’s Missing Between LLMs and AGI – Vishal Misra & Martin Casado Martin Casado and Vishal Misra
- Investing in Nexthop AI Raghu Raghuram, Shangda Xu, and Guido Appenzeller
- I Built TetrisBench, Where LLMs Compete at Playing Tetris. Here’s What I Found. Yoko Li