I was playing Tetris99 one evening on my Nintendo Switch and started wondering whether I could build a version where I play against an LLM. Not in the sense of proving that a model could “beat” the game, but simply to see what it would feel like to play something familiar against a system that reasons very differently from a human.
At the time, I wasn’t trying to create a benchmark. I didn’t have a leaderboard to climb, or a claim to make. I was mostly curious about the experience itself since Tetris is deceptively simple. At its core, it’s an optimization problem: every move is a tradeoff between what helps now and what keeps you alive later. The entire board can be described cleanly, which means each turn can be represented as structured data rather than pixels. That makes it an unusually good fit for reasoning-first systems, where the challenge isn’t perception, but deciding what to optimize and when.
When LLMs don’t work, always reframe the problem to coding
My first attempt took that idea very literally.
I started by sending the full board state to the model at every turn, encoded as JSON, and simply asked it what move to make next. I began with a set of frontier models: Opus 4.5, GPT 5.2, Grok 4.1 fast reasoning, Sonnet 4, Gemini 3 Flash since they should be strong at structured reasoning and code, and I wanted to see whether raw reasoning ability alone would be enough.
To make the experiment more interesting, I set up two simple arenas: one where a human and a model played side-by-side under the same rules, and another where models played each other repeatedly to surface behavioral differences at scale. In the project there’s a “headless mode” where I can have models compete on Tetris using the same engine in batch.
In theory, everything the model needed was there: the board, the current piece, and the legal placements.
In practice, it was terrible:
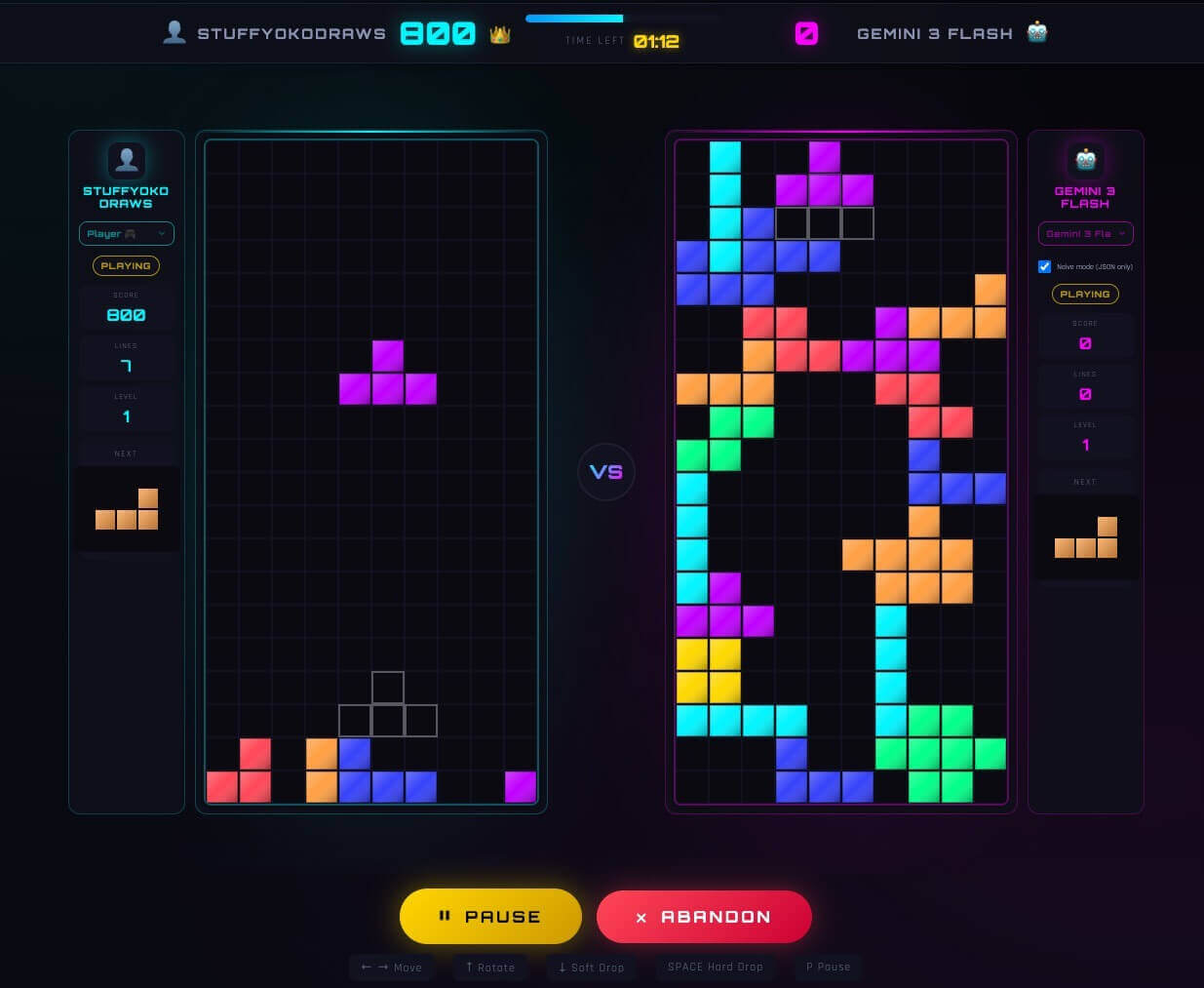
Left: human, right: Gemini 3 Flash – it had trouble clearing any line when being asked to reason on the board visually
Moves were inconsistent, often nonsensical, and frequently self-destructive. Even strong models struggled to maintain any coherent strategy across turns. The game would fall apart quickly. Plus, the latency really killed the fun of the game as the models took too long to think at every turn.
This wasn’t that surprising in hindsight. Language models aren’t trained to reason over large, evolving state spaces in a step-by-step way. They don’t have an internal notion of spatial continuity or a persistent game plan unless you build one explicitly. Asking an LLM to look at a board and pick a move each turn is effectively asking it to solve a planning problem it was never trained for.
What they are very good at, though, is writing code.
Instead of asking the model to choose a move, I asked it to write the logic that decides what a good move looks like.
Once I reframed Tetris as a coding problem, everything changed. The model’s task became: given the current board state, generate a scoring function that evaluates possible placements. That function runs deterministically, scores all legal moves, and selects the best one. The model decides if / when it wants to update the function based on the board state.
With that shift, Tetris became a stable optimization loop. The model wasn’t reacting to the board anymore, it was defining the objective function and letting the system execute it:
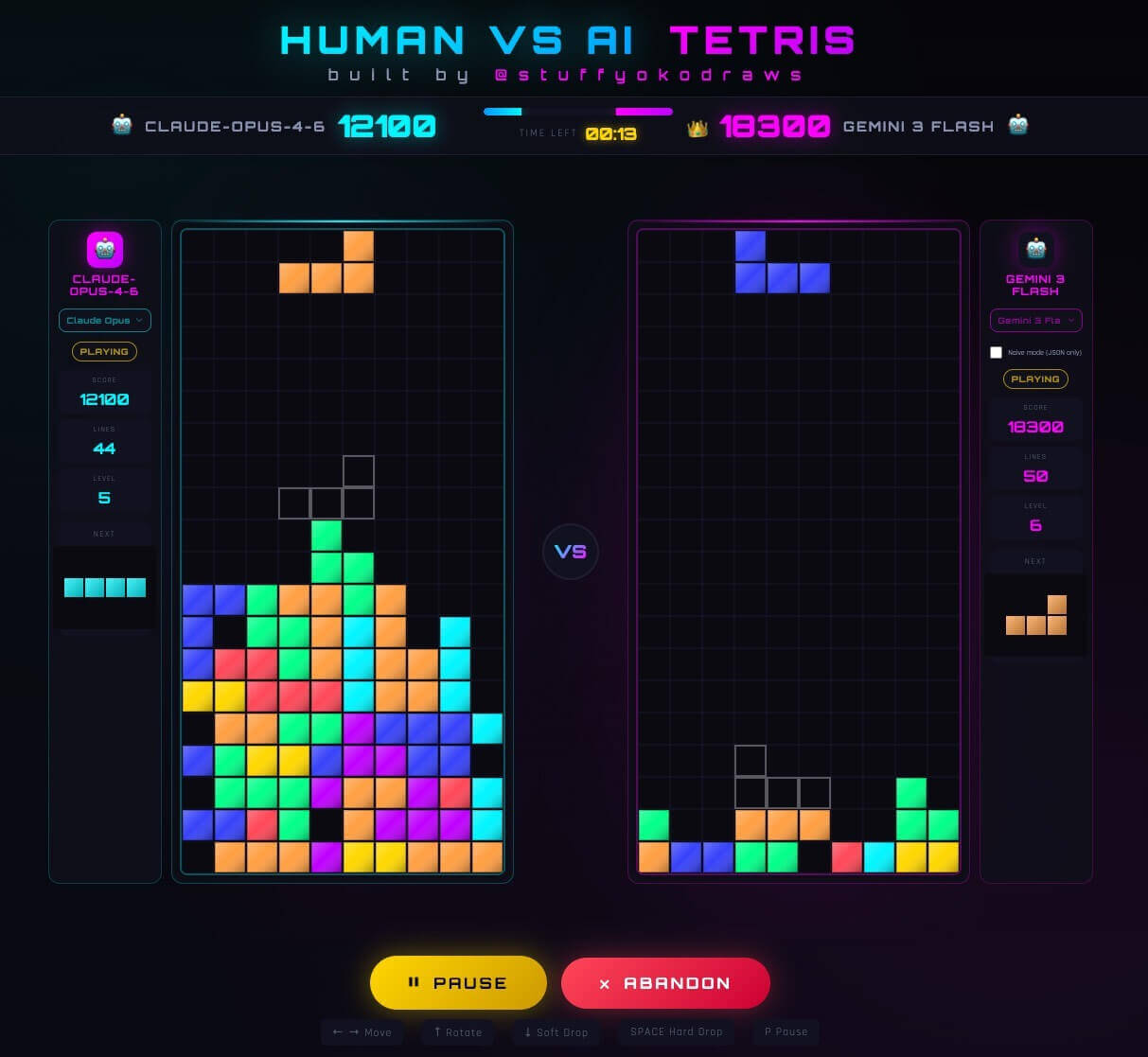
From Optimization Loop to Benchmark
Once it worked reliably, I wanted to know if the models’ different playing style was one-off or consistent. So I started running matches at scale.
So I started running model-vs-model matches at scale. Same piece sequence. Same constraints. Same execution loop. The only variable was the model. I ran hundreds of games per pairing and logged everything.
The first thing I looked at was win rate:
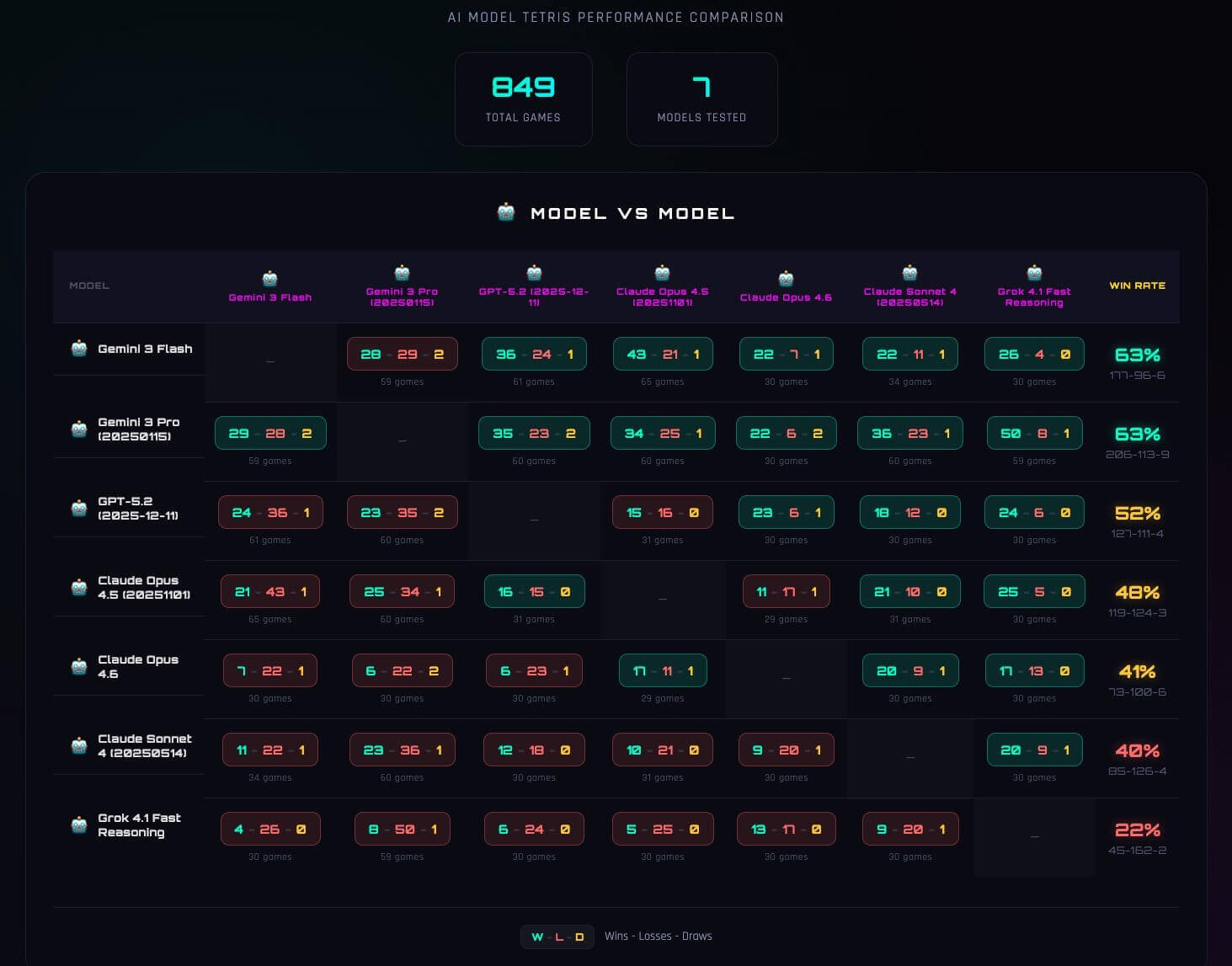
At a glance, the table looks straightforward: some models win more than others. But once you watch the games behind those numbers, it becomes clear that the win rate isn’t just measuring “skill.” It’s capturing something deeper about how each model approaches long-horizon optimization.
Two models could have similar average scores but very different win profiles. One might dominate early and collapse late. Another might survive longer with steadier boards. The table hid stylistic divergence inside a single metric.
And once you start looking at the games instead of just the percentages, those differences become impossible to ignore.
Models are not created equal for long-term strategy
What stood out immediately wasn’t just differences in score, but differences in style.
Some models played aggressively. They optimized hard for early line clears, accepted tall stacks, and looked strong in the opening phase of the game. Others were noticeably more conservative, prioritizing flatter boards and survivability even when it meant leaving points on the table.
What surprised me was that none of this was explicitly prompted. No model was told to think long-term or short-term. And yet, each behaved as if it had an implicit optimization horizon.
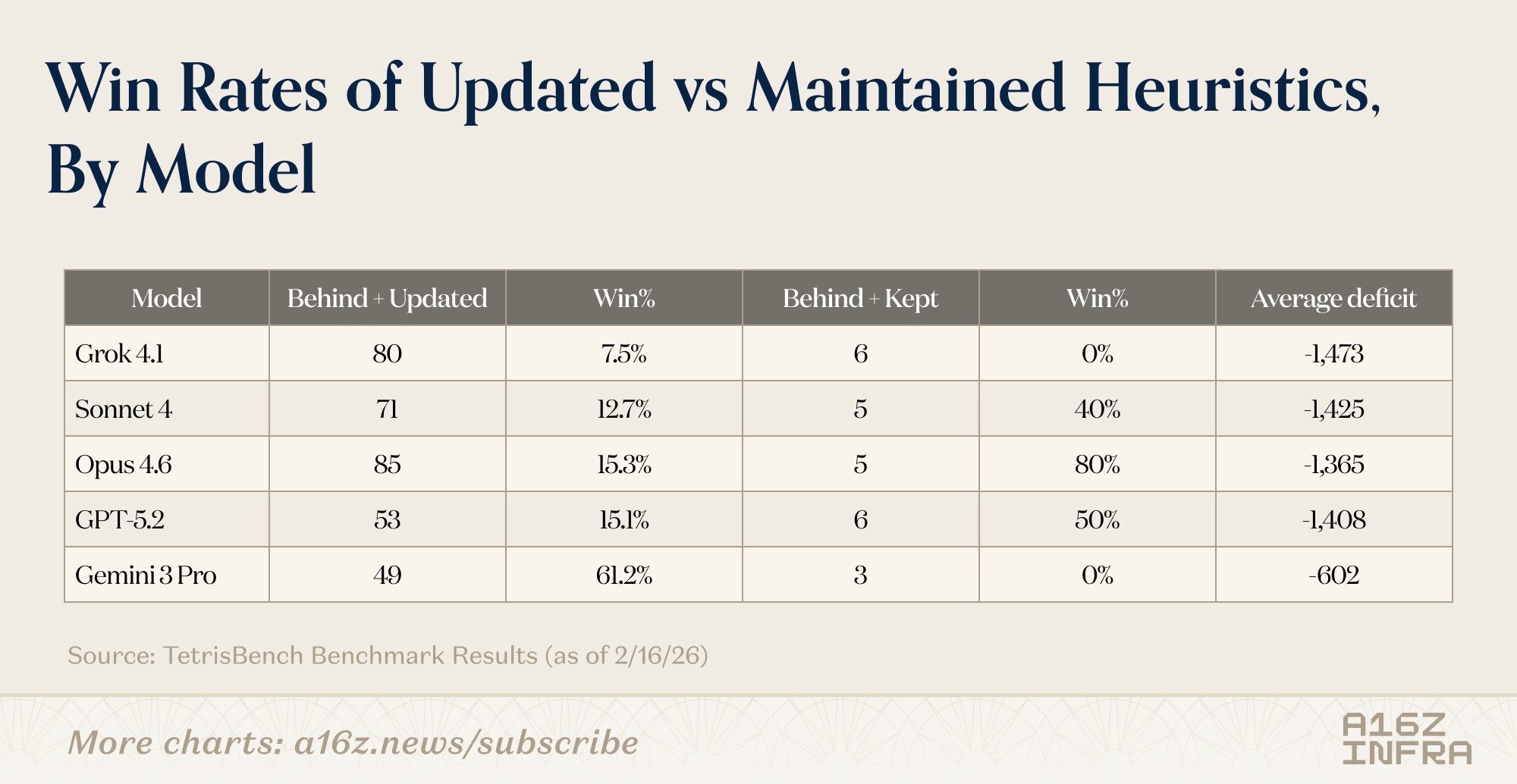
One way this showed up was in how often models chose to intervene and update their strategy. Some rewrote their evaluation logic frequently as the board evolved. Others stuck with an initial set of heuristics for a long time, even as the game drifted into riskier territory.
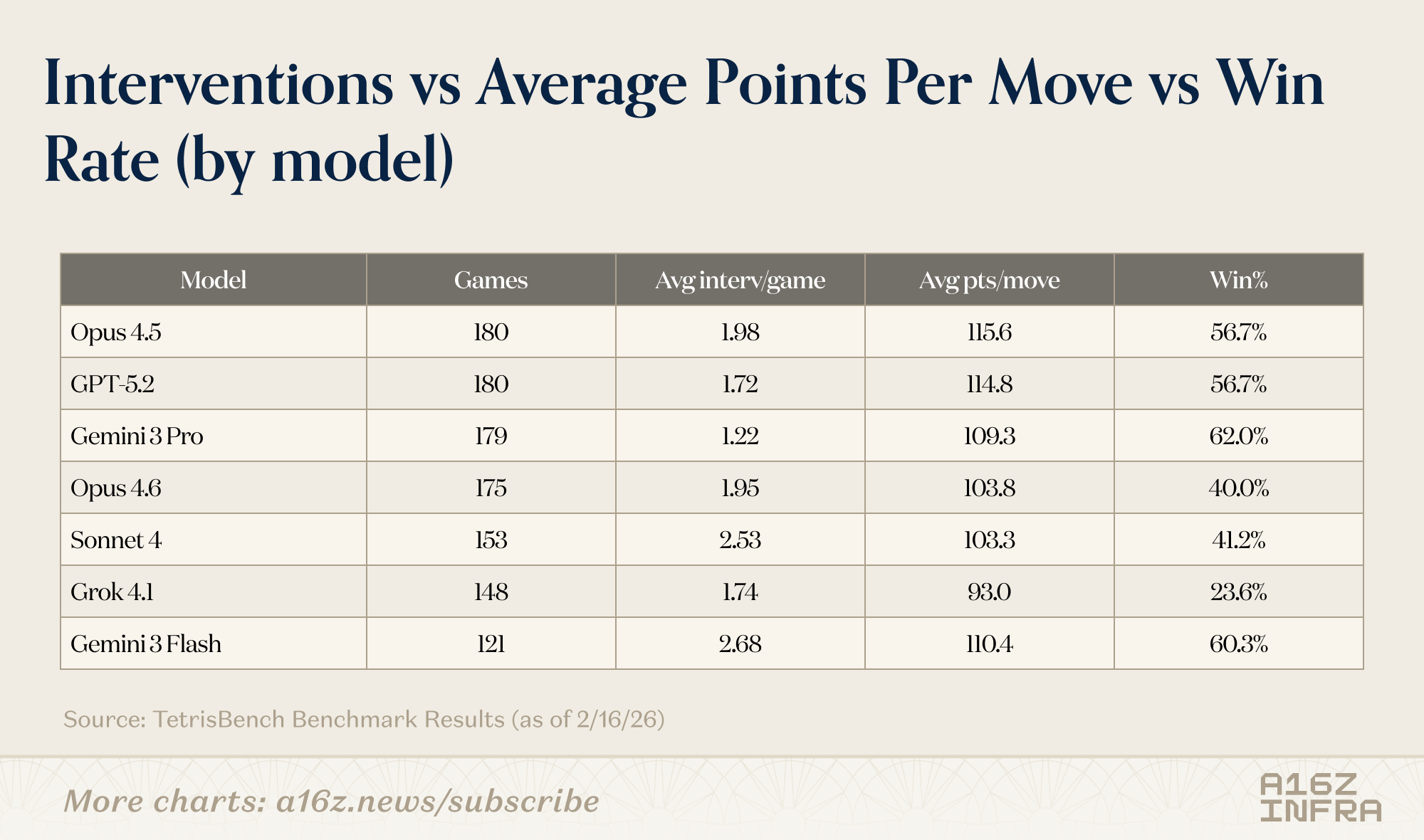
Interestingly, Gemini 3 Pro has the highest win rate (62.0%) while intervening the least (1.22 updates/game). It scores a solid 109.3 pts/move — efficient and decisive. Gemini 3 Flash intervenes the most (2.68/game) and still wins 60.3% with strong 110.4 pts/move — frequent revisions seem to work, too.
This raised an interesting question: could metrics like average points per move, plotted against the number of strategy interventions, help distinguish models that optimize locally from those that implicitly reason over longer horizons?
A few additional patterns suggest the answer might be yes:
- Interventions had diminishing returns for some models: Frequent strategy updates didn’t always translate to better outcomes. In some cases, models that intervened the most oscillated between heuristics without converging on a stable long-term plan.
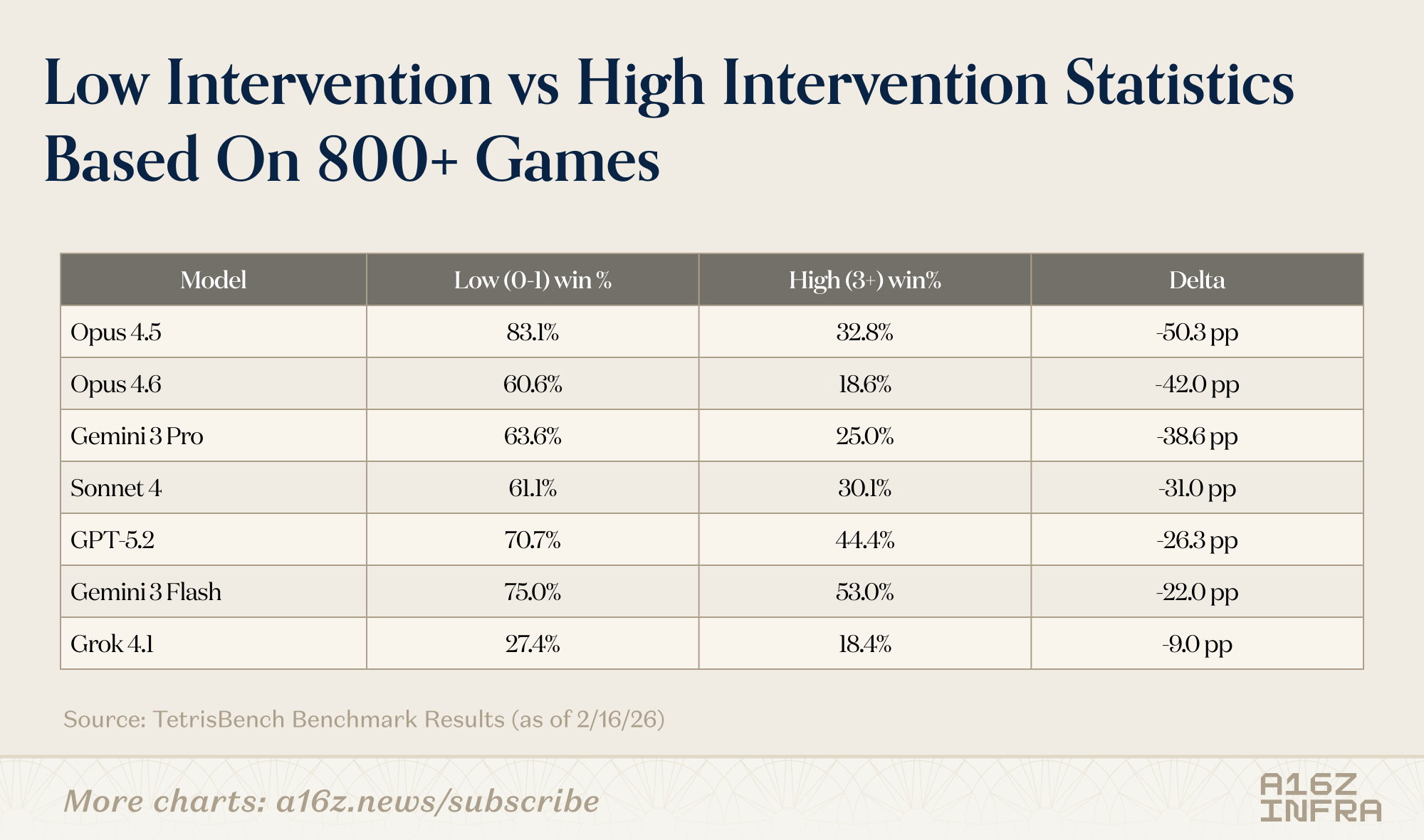
Low intervention vs high intervention statistics based on 800+ games
- Late-game behavior diverged sharply: As the board filled up, some models became increasingly reactive, making larger heuristic swings under pressure. Others failed quietly, continuing to apply a strategy that no longer fit the state.
Humans vs LLMs on Tetris
Pitting humans againstmodels highlighted a contrast that wasn’t just about performance, but about how mistakes happen.
Humans tend to play Tetris through intuition and pattern recognition. We don’t evaluate every possible move. Instead, we tolerate messy boards, make locally “bad” moves, and rely on the belief that we can recover later.
Models are much more explicit. Every move reflects a scoring function. When a model changes strategy, you can see it in the logic it generates. When it fails, the failure is often traceable to an earlier optimization choice that made sense at the time but turned out to be brittle.
In head-to-head games, below are some interesting patterns:
- Models tended to play very clean early boards, but struggled once the board entered a state they hadn’t optimized for.
- Humans were better at playing “off-distribution.” We make ugly moves on purpose and abandon plans mid-game without explicitly re-deriving a strategy
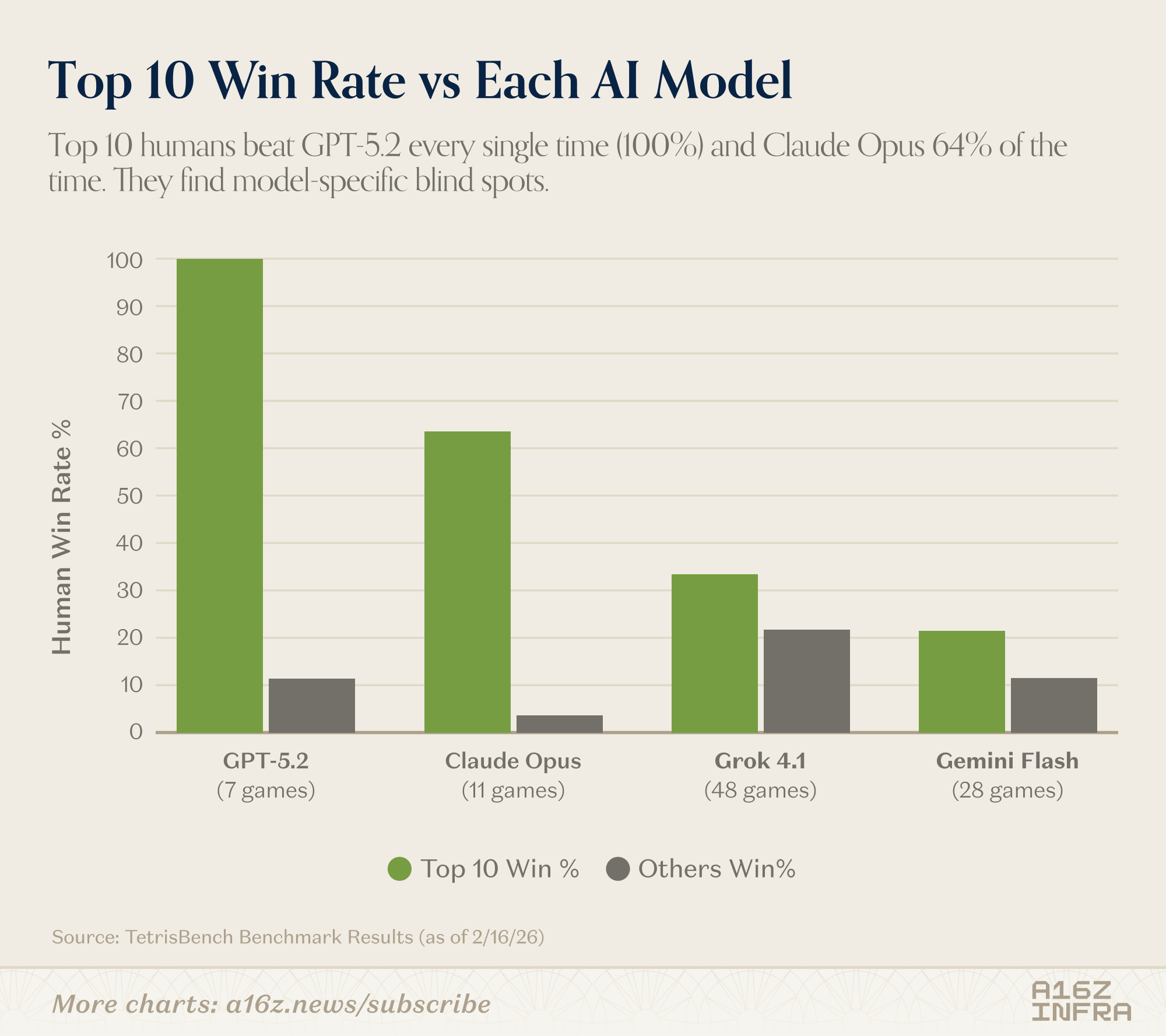
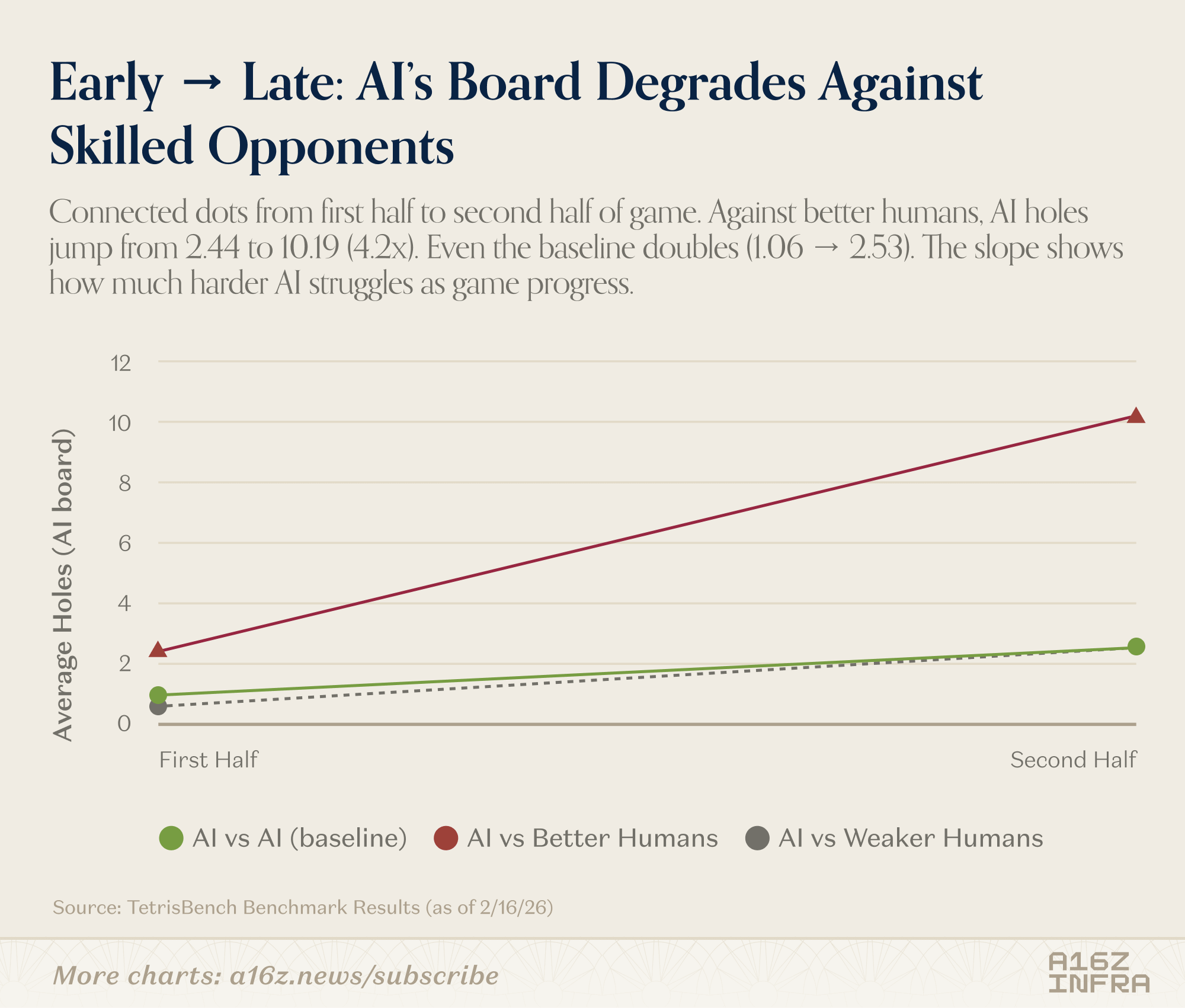
Looking at the win rate table, the headline is straightforward: models are already strong. Across large numbers of games, they outperform most human players. Against average or intermediate players, the gap is structural.
But the interesting part isn’t that models win. It’s where they lose.
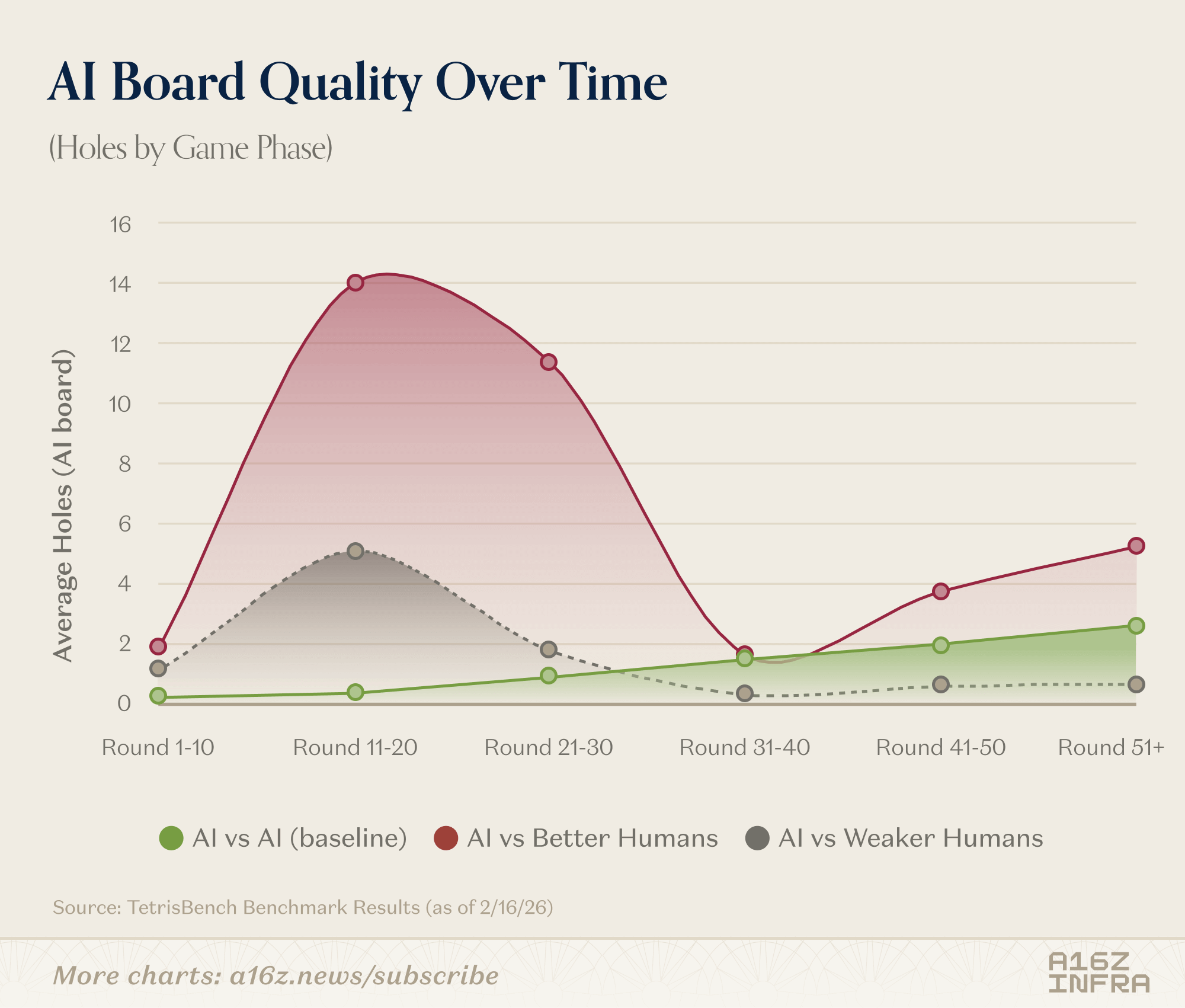
The top human players still beat certain frontier models consistently. And the gap isn’t about reaction time or mechanical precision — the environment is fully turn-based. The difference seems to emerge in edge cases: unusual board states, awkward piece sequences, moments where the “correct” move isn’t locally optimal but preserves long-term flexibility.
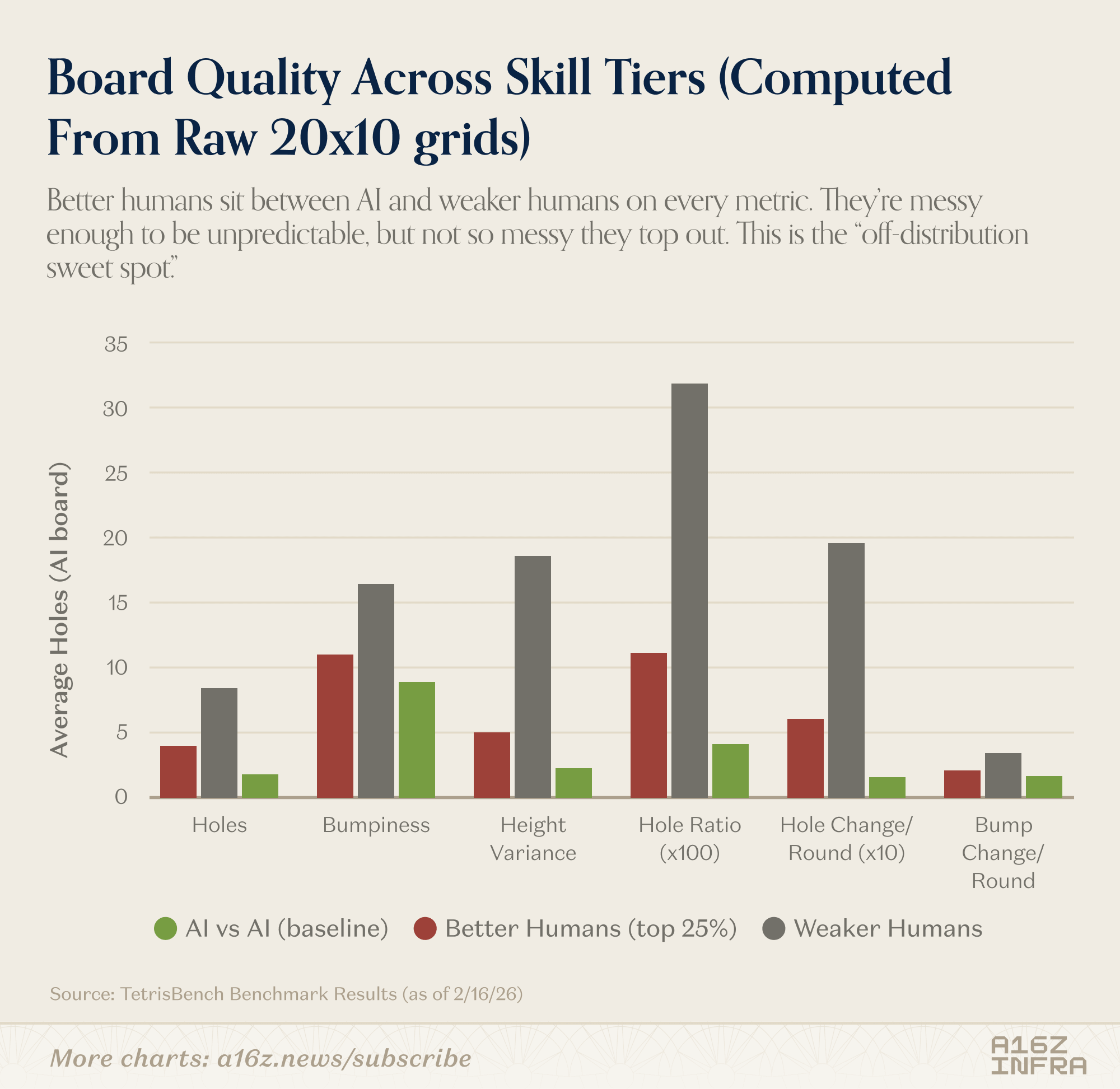
The board quality metrics reinforce this. Humans who are weaker on Tetris produce chaotic boards. Models produce very clean boards. But the strongest humans sit in between: not perfectly clean, not reckless either. They introduce controlled irregularity. That “off-distribution sweet spot” seems to be where models struggle the most.
In other words, models are highly competent within the distribution induced by their own heuristics. The best humans, however, occasionally force the game into regimes those heuristics weren’t built for.
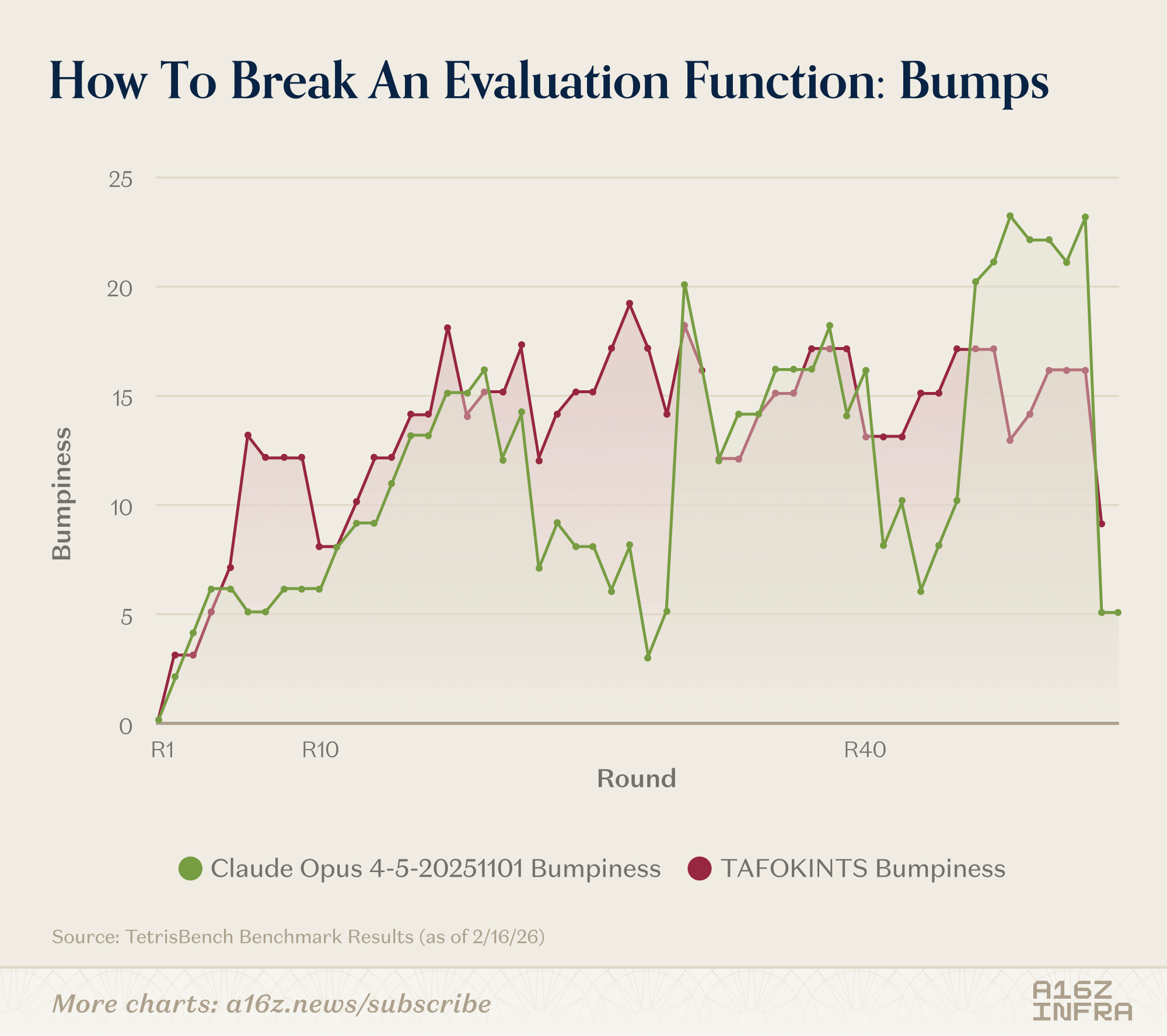
One such example is a game where TAFOKINTS (a user who used to compete in Tetris competitively) played against Claude Opus 4.5. TAFOKINTS eventually scored 22,300, beating Opus’ 15,700. What’s interesting is Opus played perfectly for 21 rounds, then TAFOKINTS caught up quickly:
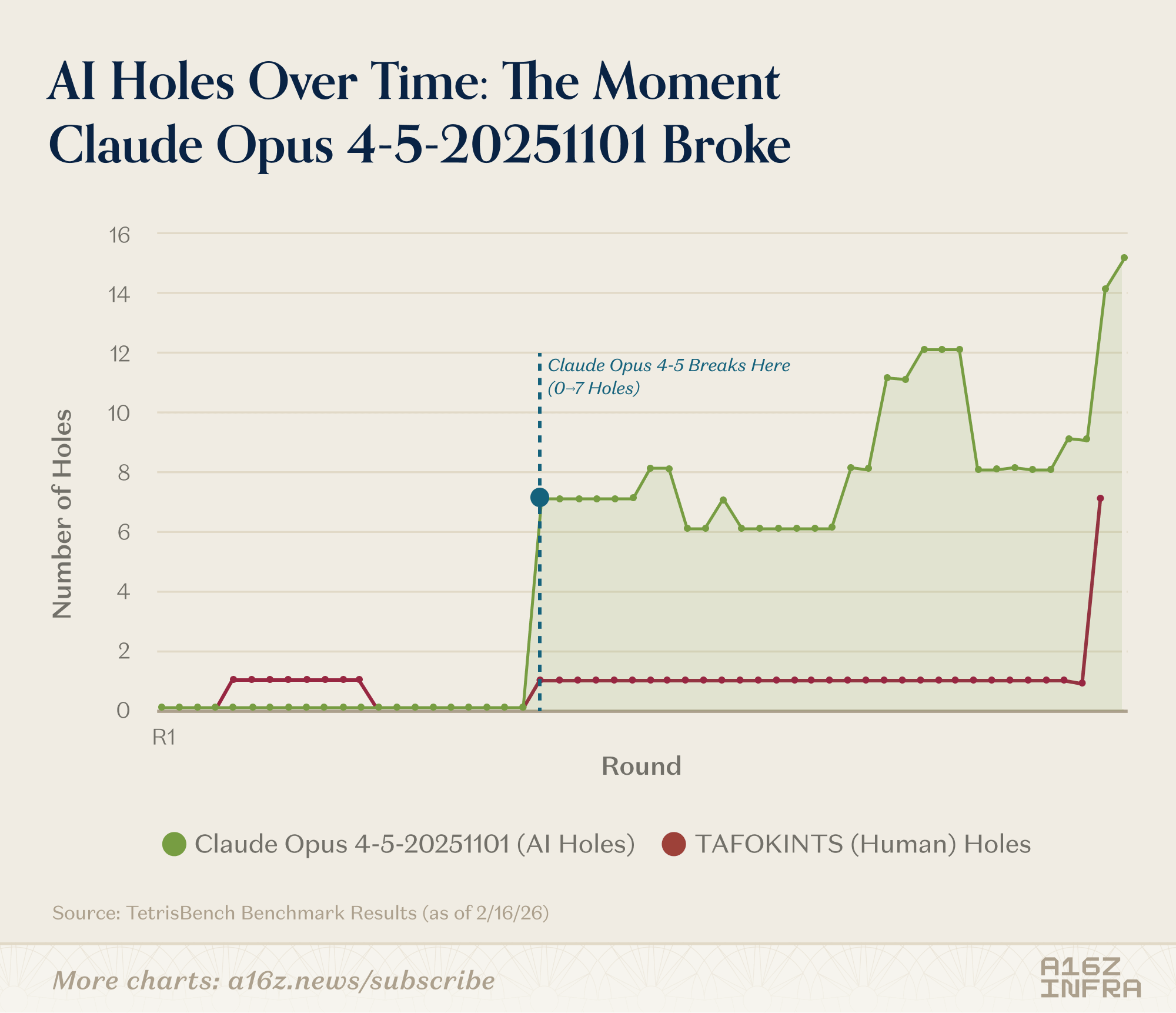
TAFOKINTS also built boards with bumpiness 12–19 while maintaining 0–1 holes. This “controlled chaos” is the off-distribution sweet spot that breaks AI evaluation functions:
What This Experiment Changed My Mind About
Building something I could actually play against changed how I think about evaluating models.
One thing this made clear is how strongly representation shapes what you end up measuring. By stripping away vision and working with structured state, the task shifted from perception to planning. The differences that emerged had little to do with what models could “see,” and much more to do with what they chose to optimize over time.
Another insight is that optimization horizon is something you observe in behavior, not something you reliably elicit with prompts. In a sequential setting like Tetris, long- vs short-term bias becomes visible. You can watch models trade future flexibility for immediate reward or deliberately avoid doing so—even when no one tells them to think ahead.
Finally, intervention is itself a meaningful decision from LLMs. Knowing how to act is different from knowing when to stop and reconsider your strategy. That distinction feels increasingly important as we build agents that operate over longer time horizons and face states their designers didn’t explicitly anticipate.
What surprised me the most is that a very old, very simple game was enough to surface these differences. You don’t always need complex environments to learn something meaningful about how systems reason over time.
If you’re thinking about benchmarks for planning, coding agents, or long-horizon model behavior, I’d love to chat. You can find the TetrisBench project here. If you’re interested in the full data and trajectories generated from this benchmark or want to explore related analyses, feel free to reach out at yli@a16z.com.
