Imagine being asked to find new office space for your company – a task you’d rather avoid. Now imagine delegating the entire process to an AI: identifying requirements, researching locations, scheduling tours, negotiating leases, even handling insurance and unexpected issues all without your involvement or explicit instructions. This vision of autonomous, task-oriented “AI agents” capable of working independently has long been the field’s north star.
Yet despite considerable attention and effort, today’s agents fall short of this vision. Current agent offerings more closely resemble advanced robotic process automation (RPA) tools than true autonomous systems. While LLMs have made advances here, they typically rely on intricate prompt engineering, carefully orchestrated models, and predefined workflows, such as scripted CRM record updates.
Recently, however, we’ve seen progress toward realizing true AI agents, particularly those operating within browser and desktop environments. Projects such as OpenAI’s ChatGPT Agent, Anthropic’s Claude, Google’s Project Mariner, and startups like Manus and Context offer a glimpse into what human-level AI agents, trained specifically for computer tasks, might achieve.
Unlike single-purpose AI tools, these agents, which can access a wider range of tools either explicitly through MCPs or implicitly with a computer-using model, can tackle complete, end-to-end digital workflows. For example, they can locate a document in a database, extract key details from it, update Salesforce, notify colleagues on Slack, and generate a compliance report, all without human involvement. They handle the behind-the-scenes “glue work” that usually ties up human workers. In addition to using APIs like computers, these agents can also operate software like humans do when programmatic access isn’t possible — clicking through user interfaces, logging in, sending files, working with legacy software — so they can slot into existing workflows without needing major IT overhauls or custom integration. And because such agents “plug in” at the worker level, they can be retrained or scaled as needed, just like human teams.
Together, these advances point to a broadly useful application: AI agents capable of handling a wide range of digital work without human input.
Why computer use matters
Computer use is the key enabler of true agents. Their effectiveness depends on two things: the number of tools they have access to, and the ability to reason across them. Computer use dramatically expands both – giving agents the breadth to work with any software and the intelligence to chain actions into full workflows.
- Tool Accessibility: Computer use gives agents access to any software humans interact with, bypassing the traditional need for APIs or manually programmed tools.
- Reasoning Capability: Computer-using models are trained end-to-end on action sequences or via reinforcement learning. They output computer actions directly at the model level. The specialized nature of these systems leads to greater accuracy than prior approaches, which involved cobbling together more general purpose vision and reasoning models.
The potential of computer-using AI agents emerges through the multiplicative interplay between tool accessibility and reasoning capability. As agents gain broader toolsets and simultaneously become better at using them, the range and complexity of workflows they can handle grows exponentially. When we factor in the potential of emergent capabilities (i.e., these agents may solve context retrieval by autonomously exploring, retrieving, and synthesizing context over bespoke sequences of actions), the possibilities grow more promising still.
For startups, the primary opportunity around AI has been automating work and capturing labor spend. Computer use represents the most significant advancement to date in replicating human labor capabilities. Previously, a major limitation was the long tail of software tools that lacked API access or had restricted APIs, which required humans to manually oversee it. This challenge was particularly prevalent with the legacy software at the core of many enterprises, such as Epic, SAP, and Oracle. Computer-using agents with reasoning abilities and the capability to navigate graphical user interfaces effectively fill these gaps, enabling the end-to-end automation of work.
Where we see opportunity
While computer-using agents hold great promise, deploying them widely across enterprises won’t be easy. We believe that properly verticalizing computer use and assisting companies in adopting it will be a major area of exploration for startups.
It is unlikely that a computer-using agent trained solely on general software, like ChatGPT agent or Claude, will be able to navigate complex enterprise software environments out-of-the-box. Enterprise software is often highly specialized and unintuitive, and different companies often use the same software differently, implementing customized views, workflows, and data models. Consider how much training humans typically require when joining a company or learning new software.
Because of this, computer-using models will require meaningful context, similar to the enterprise chatbots and assistants that preceded them. It’s unlikely ChatGPT agent will know how to navigate something like this SAP instance without additional context or training:
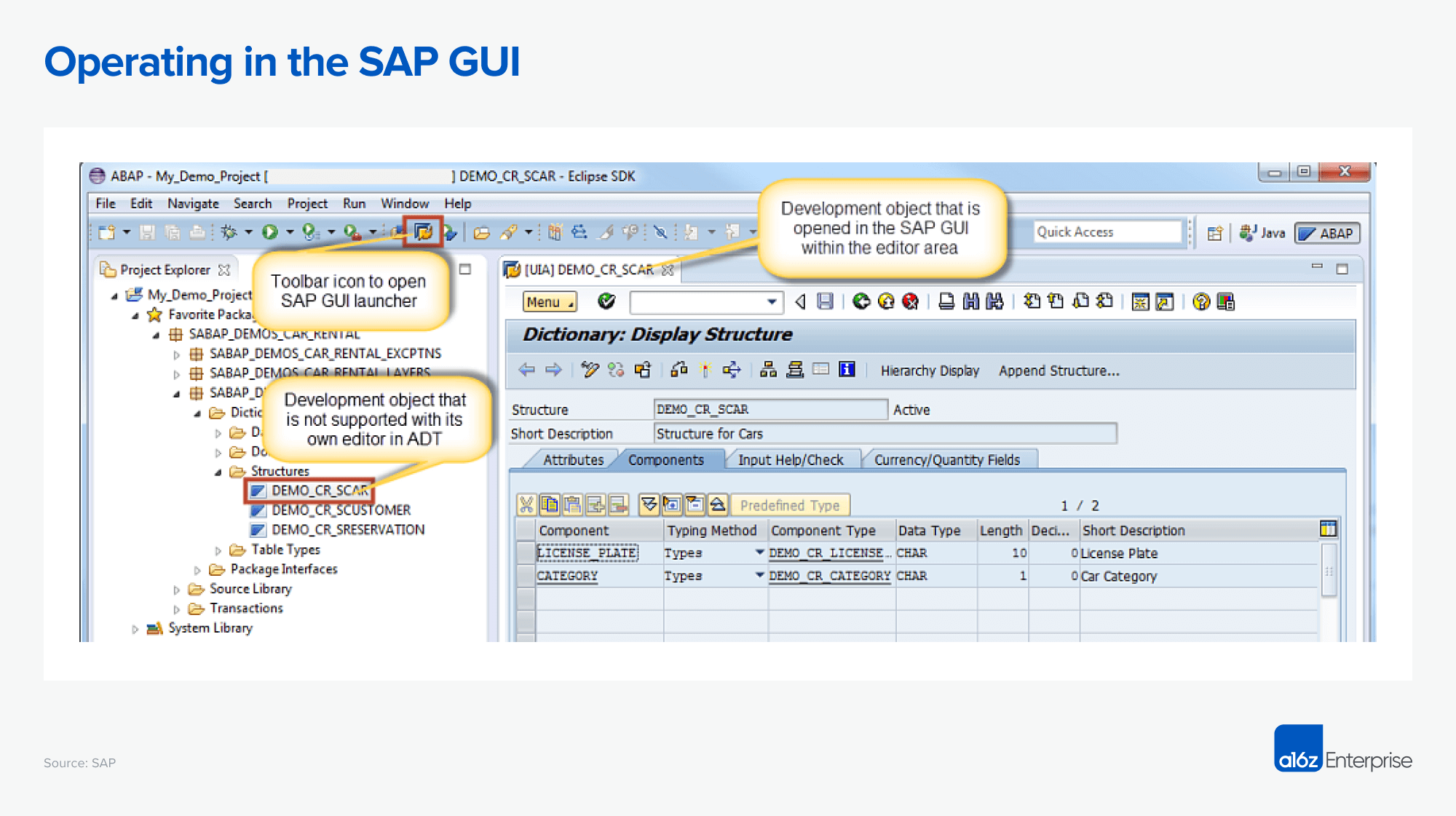
But providing context to a model for scenarios like this is complicated. For one, what exactly is the relevant context? There may be written instructions, onboarding videos, browser action recordings, or in some cases, no documentation at all. Next, what’s the best way to provide context to the model? It may not be as straightforward as adding text to the beginning of a prompt, as there’s a graphical and temporal dimension to account for. What does the analog to retrieval and RAG look like here? And finally: should old processes dictate new ones? Agents should consider how humans work, but humans may have suboptimal ways of doing things — to what extent should agents ignore context and reinvent workflows from the ground up?
Startups that master these contextualization strategies will have a distinct advantage in delivering capable and customized agents to enterprises. While best practices for how to do this are still being developed, it is likely that highly focused startups, rather than model providers, will be best positioned to address these vertical- and company-specific challenges.
With these considerations in view, we now turn from why computer use matters to how it is realised in practice. The technical stack that follows shows where tuning, contextualisation, and reliability measures plug in, and therefore where startups can differentiate.
The stack: building a computer-using agent
Computer‑using‑agent architectures remain an active area of research; developers are still converging on where to divide responsibility between increasingly capable models and auxiliary tooling. Most current approaches organize agents into layers that translate high-level goals into reliable UI actions. It remains an open question whether some of these layers – such as interaction frameworks – will eventually disappear as multimodal models become more capable. Both vision-based (pixel) and structure‑based (DOM/code) pipelines are being explored, and best practices for blending them are still taking shape. Even so, the layers described below offer practical boundaries for injecting domain knowledge, tuning behaviour, and enforcing reliability—the challenges outlined above.
At a high level, the stack below captures how computer use agents translate reasoning into reliable action. Interaction frameworks shape how models are instructed to perceive and act on interfaces. Models interpret pixels or DOM structures to produce commands. Durable orchestration ensures long-running multi-step computer use workflows don’t break. Browser control layers expose automation hooks, while the browsers themselves render the interfaces where agents operate. And at the base, execution environments scale the entire system into production-grade infrastructure.
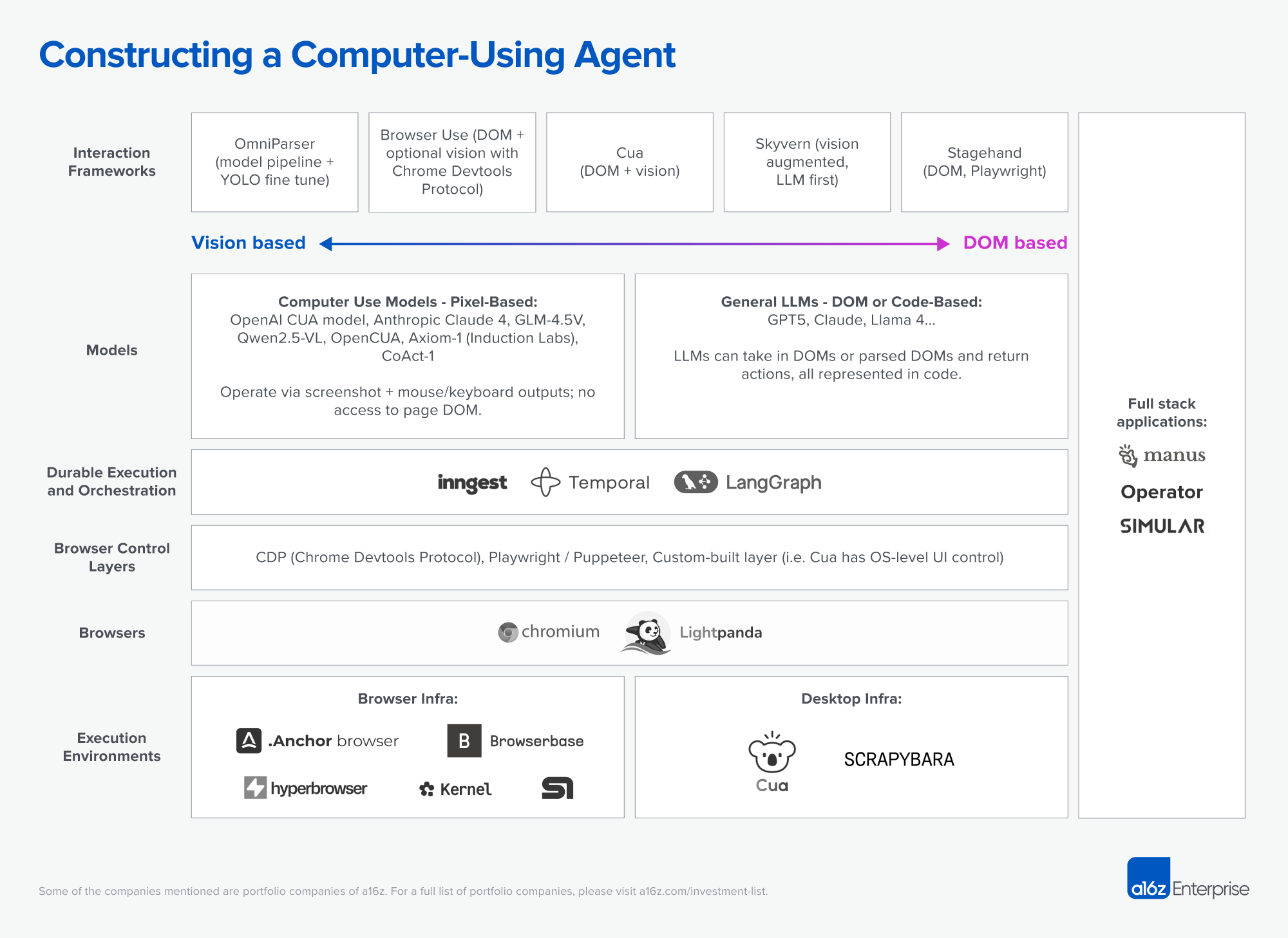
Going deeper on each layer:
- Interaction Frameworks: Tooling that gives models a structured way to interact with user interfaces or DOM. They differ in where they anchor control: OmniParser converts pixel input into element graphs; Stagehand exposes act() and extract() APIs over a DOM‑filtered accessibility view; Browser‑Use, Cua and Skyvern combine visual grounding with structured control to stay robust against layout drift.
- Models: The decision‑making core that interprets inputs and emits commands.
- Pixel‑based models: Operate on screenshots and generate mouse or keyboard actions. Recently, we’ve seen Chinese vision agents (e.g., UI-TARS, Qwen-VL) climb the OSWorld leaderboard, open-source models like OpenCUA close the gap with proprietary CUAs, hybrid architectures like CoAct-1 soar past pure vision agents, and notably, Anthropic’s Claude 4 Sonnet emerge as a top-tier pixel-first model, outperforming prior Sonnet versions and offering a powerful, efficient option for general agentic workflows.
- DOM/Code‑based LLMs: Process structured HTML, accessibility trees, or program text to produce selector‑level commands and reasoning traces. In many circumstances, what we’ve heard from the market is that this approach alone is good enough for most tasks, in many cases having higher accuracy and much lower latency than the pixel-based approach.
- Durable Execution & Orchestration: Workflow engines that persist event histories, enforce retries, and resume computation after faults. Inngest stores step outputs and replays only failed segments; Temporal reconstructs in‑memory state by replaying an append‑only log on replacement workers. Azure Durable Functions and AWS Step Functions offer analogous guarantees in serverless contexts.
- Browser Control Layers: Abstractions for issuing commands to browsers. CDP (Chrome DevTools Protocol) gives direct, low-latency control now favored by Browser Use and others; Playwright and Puppeteer are still widely used, but their added latency makes them less practical for agent workloads, leading to declining adoption in computer use. Custom layers like CUA (developed by Francesco Bonacci and team) build hybrids tailored for GUI automation.
- Browsers: Execution substrates where interfaces render and agents act. Lightpanda is a lightweight LLM-aware browser. Most browsers systems we have come across are Chromium-based because it provides the most mature developer tooling, stable automation APIs, and compatibility with modern web standards. This makes it easier to integrate agent control, though it also introduces heavier resource requirements compared to lighter custom runtimes.
- Execution Environments: Cloud and desktop infra for scaling agent sessions. Anchor Browser, Browserbase, Steel, Hyperbrowser, and Kernel deploy fleets of browser instances with observability and replay; Scrapybara provisions full Ubuntu or Windows desktops via API, mixing GUI operations with shell commands; Cua-style sandboxes emulate end-user devices for training and evaluation.
Parallel to the infrastructure stack, commercial full‑stack agents applications integrate these layers into cohesive products. ChatGPT Agent couples CUA with a managed browser sandbox for end‑to‑end web automation; Manus orchestrates multiple language models inside persistent Linux environments to automate enterprise processes; Simular S2 recently achieved leading autonomy scores on OSWorld. The recently announced Claude for Chrome embeds Claude into your browser via an extension so the agent can take actions on your behalf. These solutions abstract the entire stack behind goal‑oriented interfaces while embedding guardrails and oversight.
The future: enabling agentic coworkers
Despite rapid progress, current agents still exhibit significant limitations in capability (struggling with complex or unfamiliar interfaces) and efficiency (operating too slowly and expensively to compete effectively with human operators). Nonetheless, we anticipate substantial improvements in both areas over the next 6 to 18 months:
- Capability: Enhancing capability primarily involves increasing agent effectiveness on novel or intricate interfaces. At the application level, this can be achieved by constraining the agent’s operational domain and providing task-specific contexts or examples at inference time. From a model-development perspective, this entails scaling up training datasets and training runs – mainly by utilizing supervised fine‑tuning and reinforcement learning from synthetic interaction traces in safe replicas/sandboxes, and broadening training distributions through simulation‑driven curricula and expanded, more representative benchmarks.
- Efficiency: Boosting efficiency entails reducing both cost and latency associated with each inference cycle. Promising strategies include compressing or distilling vision-language models, applying quantization, caching interface element graphs to reprocess only changed regions, delegating routine inputs like straightforward keystrokes or clicks to simpler, rule-based controllers, and using explicit tool invocations (i.e. MCP server calls) whenever possible.
Effectively addressing these issues will pave the way for genuine agentic coworkers. Initially, we anticipate these agents will excel in specialized business functions, and may even be tuned via implementation work to the needs of specific companies. These agents will be able to work across existing software stacks and optimize higher-level strategic objectives (e.g., acquiring a specific number of users within budget or creating forecasts under certain constraints), rather than staying siloed within teams, individuals, and workflows. They will be particularly useful when working with legacy software or where APIs don’t exist or are limited. As new tools and APIs emerge or existing ones evolve, agents will be able to incorporate them without substantial implementation work.
For example, consider agentic coworkers focused on marketing, product management, finance, sales, and HR/recruiting:
- Marketing: a growth and marketing-focused agent tuned on design tools, ads platforms, and marketing automation software could autonomously design and optimize entire marketing campaigns. Such an agent might handle audience segmentation, creative ad generation, A/B testing, budget optimization, campaign monitoring, and insightful reporting.
- Finance: an agent tuned on accounting software, financial management systems, payment processing platforms, spreadsheet applications, and expense management tools might autonomously handle tasks like financial reconciliation, fraud detection, budgeting, invoice processing, and generation of regulatory-compliant financial reports. This would reduce human errors and improve financial accuracy and timeliness.
- Sales: an agent tuned on CRM systems, sales intelligence platforms, communication and outreach tools, and sales analytics software could autonomously identify high-potential prospects, perform personalized outreach, schedule meetings, analyze sales call transcripts for actionable insights, and update CRM data in real-time, amplifying sales productivity and pipeline velocity.
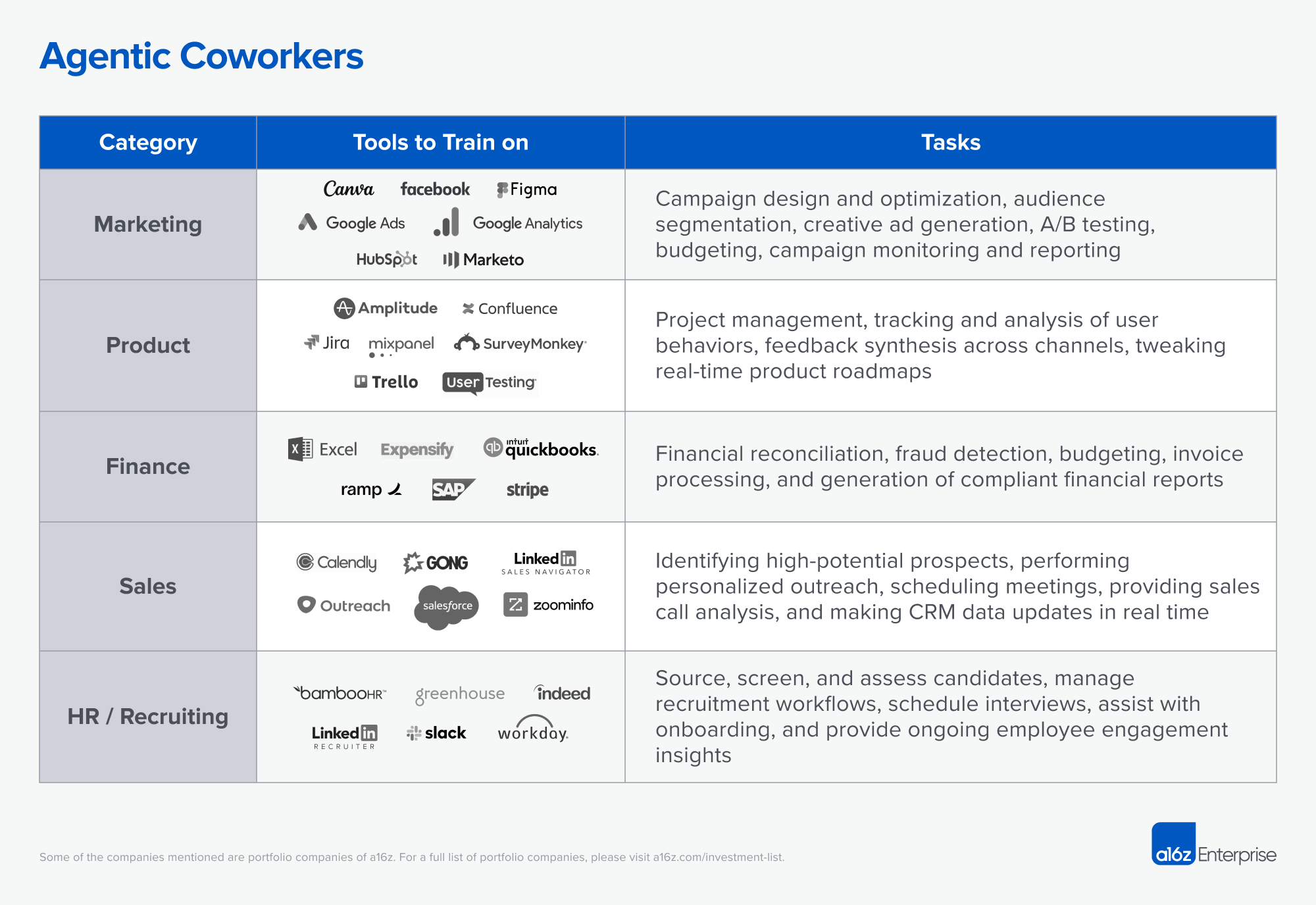
Combining these domain and even company-specific capabilities with the broad horizontal competencies that computer-using agents will have access to — such as web search, email management, internal communication via Slack, document handling through Google Drive, and content organization with Notion — unlocks new functionality. These agents will also be able to handle more bespoke and legacy actions, integrating with systems that offer limited API access, where computer use is particularly helpful.
This delivers two key advantages. First, agents become more effective at their jobs with more context. They can independently gather and synthesize internal and external information, enhancing task performance. For example, a sales agent drafting a cold email can seamlessly incorporate the latest product roadmap from Google Drive. Second, this comprehensive integration of tools simplifies deployment and implementation. Agents naturally integrate into existing workflows and toolsets without requiring specialized interfaces or separate platforms like traditional software, which reduces friction. One can imagine swarms of agents working together in the near future, staying in sync with each other and their human counterparts through existing systems of record and communication channels.
Conclusion
Computer-using agents mark a step-change beyond browser automation and RPA. By working across existing tools and adapting to legacy systems, they bring us closer to truly agentic coworkers that can operate across the same fragmented and legacy-laden environments human workers navigate every day.
The challenge ahead is not proving whether agents can work, but shaping how they are tuned, contextualized, and deployed within real enterprises. Startups that master this contextualization will define the first generation of agentic coworkers, and in doing so set the standard for how digital labor transforms entire industries.
If you’re also excited about computer using models and applications built with them, reach out to ezhou@a16z.com and samble@a16z.com. If you’re excited about building infrastructure around these models, reach out to yli@a16z.com and jli@a16z.com.



