Last year, it seemed like every week a new frontier video model would one-up its peers and push our expectations. We learned to simply expect relentless improvement on measurable benchmarks: longer video output, sustained stories, better physics, character consistency, movement cohesion, and more.
But this year, if you care about the benchmarks a lot, you might be getting a little restless. We pretty much expect all video models to generate 10-15 seconds with synced audio and speech, and an all-around sense of realism; which is a great achievement, but not the runaway model progress to which we’d been conditioned. Instead, we’re entering a more exciting time: the product era of video models, where “abundance” isn’t about benchmark performance – it’s about variety.
- We’re beginning to see models specialize across specific dimensions: there is no “God Model” that’s great at everything.
- Startups are finding new opportunities across two main dimensions: video models that excel at one key thing (Physics! Anime! Multiple shots!) and products that abstract away arduous workflows.
- Hot take: even if video model progress stopped entirely, founders would be playing years of catch-up building products around current model capabilities.
- This is great for startups: it creates space for verticals and wedges that can become their own massive companies.
A brief history of models
For the past few years, frontier diffusion model labs have consistently released models that outperform prior generations on major benchmarks. This progress inculcated an assumption among researchers, creators, and (yes) VC’s like myself: a “god-tier” model that is great at everything would eventually emerge, and become the default provider for a multitude of different video use-cases. But this year, the assumption was challenged: Sora 2 was released last month, and appeared below Veo 3 on benchmarks like LMarena. There’s a sense that progress might be slowing on the diffusion model level, and the concept of “SOTA”, at least when it comes to video models, may not actually exist.
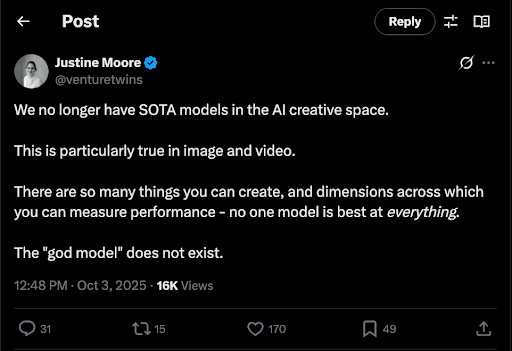
Of course, this assumption (and subsequent confrontation with reality) is not unique to diffusion models. Frontier lab LLMs also followed a pattern of step-function improvements from 2023-2025, and then saw performance begin to level off across a variety of benchmarks. When this happened with LLMs, we saw major foundation labs begin to specialize in specific verticals, and the overall AI product layer take off; in fact, we wrote about this trend earlier this year.
Upon reflection it does make sense that progress on video models is beginning to plateau, at least when it comes to public benchmarks. Models have come an extremely long way in terms of realism and aesthetic quality, and now generate outputs that are so realistic that at this point, they might be hitting an asymptote. Once you convincingly look like real life, how much more “real” can you get? A good analogy here might be still-life painting in the 17th and 18th century: at a certain point, the old masters got so good at painting realistic portraits and pastoral scenes that preferring one artist over another came down to a simple matter of aesthetic taste, rather than any objective measure of what looked more “real”.
So what happens when realism stops being the differentiator for video models? We get more variety and specialization. Welcome to the abundance era.

The Models are Specializing
Before we explore the increased specialization we’re seeing at the model layer, it’s worth taking a quick stroll (or more appropriately, scroll) down memory lane. Back in early 2024, I wrote a piece taking stock of the state of video model outputs. At the time, it was a struggle to generate videos longer than 3-4 seconds. Physics was a joke: people might randomly melt into the ground; basketballs might rebound off the backboard, ricochet toward the ground, then miraculously end up in the hoop in the final frame. At the time, I remarked that it would be awhile before we saw AI generate a Pixar-level short film. Google hadn’t yet released Veo, or any public model for that matter; they would just tease the timeline with research papers.
How quickly things change. Google now dominates LMArena and other leaderboards with their Veo models. OpenAI is producing a $30 million animated feature with a team of 30 people on a timeline of nine months (admittedly they’re not one-shotting the feature from a single prompt, but this is still staggering progress!). As stated in the introduction, we can now expect longer video outputs, and higher degrees of physics realism: the basketball rebounds off the backboard and hits the ground now.
But even as models collectively are getting better, we’re beginning to see them specialize. Why? Because no one model is good at everything. Some teams are optimizing for price and speed of outputs. Others are going all-in on post-training, with apparent focuses on specific verticals. Here are a couple of examples of what I’m seeing:
- Veo 3: has the strongest handle on physics, complex movement, and audio & speech synced with video
- Sora 2: will “direct” for you from a short prompt, writing the script (it’s often funny!) and creating multiple shots.
- Wan – a solid open source player with an ecosystem of LoRAs for specific styles, motions, or effects.
- Grok: fast, inexpensive, and particularly great at anime and animation

- Seedance Pro: – can product multi-shot scenes in a single generation

- Hedra: great at long-form clips of talking characters

Comparing outputs from Sora 2 and Veo 3 is a great illustration of how models are beginning to specialize. Both are exceptional video models, but I’d argue they’re good at very different things. Sora excels at inserting yourself (or friends) into a scene, and crafting a story (or meme, or joke) from a short prompt, like the Stephen Hawking sports clips or Pikachu in famous movies. It’s great for consumers and meme makers.
However, it’s not as good as Veo 3 at syncing video with audio. You’ll often get multiple fast clips where the audio lags behind or the wrong person is talking. And in my opinion, it’s less good at understanding physics or any kind of more complex motion. Veo 3, meanwhile, has less of a sense of humor and needs more guidance, but I’d argue that it’s a more powerful and controllable model for prosumer and professional creatives.
This trend of model specialization is also positive for players up and down the stack. AI video cloud providers like Fal and Replicate now host dozens of models for users seeking to access these various vertical use-cases. Editing suites like Krea give users a central hub that allows them to interact with multiple models and build entire workflows around them.
Still, I expect to see the extremely well-capitalized labs trying to achieve “god mode” when it comes to video, and we hope and expect to see continued performance improvements! But there’s also a ton of opportunity in being the best for a certain use case or in a certain vertical.
Products for the Masses
If you follow me on X, you’ve probably picked up on the fact that I love experimenting with multiple video and image models to create extremely bespoke outputs. This involves a ton of cross-pollination between different model providers and editing tools. For example, creating a custom furniture staging video involves leveraging Ideogram, nano-banana, and Veo3, and adding product swag to an existing video requires nano banana, Hedra, and editing suites like Krea and Kapwing. Not everyone has access to all of these tools (or the level of masochism) required to generate their desired outputs. We need better end-to-end products.
There’s still a ton of “room to run” when it comes to catching up to model progress on the product side. Creators are hacking together complex workflows across multiple products to do things that could feasibly be done by the models – e.g. getting consistent characters across generations, extending a scene by taking the end frame of the last clip, controlling camera movement via start and end frames using an image edit model, or collaging storyboards.
The good news is that some labs are starting to address this product gap. Runway released a suite of apps that enable creators to edit camera angles, do next-shot video generation, perform style transfers from one clip to the next, change the weather, and add or remove items from clips. Sora Storyboard enables users to specify precise moment-to-moment action in a video sequence. And Veo 3.1, which was released earlier this month, consists almost entirely of product updates around audio and visual control, as opposed to model-level improvements.
Some people like to say that if LLM progress stalled tomorrow, entrepreneurs would still have years of catchup to play building useful products around the models’ capabilities. The same is true of video models too: we’re only just beginning to see end-to-end products being built around these models, with a lot of opportunities that haven’t been explored yet. In the future I’m excited to see smaller, more specialized models. There will likely be products that guide these models towards the best generations for specific use cases or industries – like home-staging, marketing, or animation. And finally, we still need creative suites to bring all the modalities together and make it easier to generate and edit in one place: video, dubbed audio, music, and more.
If you’re working on new verticals in video models, or end-to-end products for AI video orchestration, reach out! I’d love to hear from you. You can find me on X at @venturetwins, or email me at jmoore@a16z.com.
