The context on context
Recently in the world of data and AI agents, context layers and graphs have emerged as an interesting topic of discussion. In fact, it’s difficult today to have a conversation with an organization working with data and AI and not have the topic of context come up.
And for good reason. Over the past year, the market has realized that data and analytics agents are essentially useless without the right context – they aren’t able to tease apart vague questions, decipher business definitions, and reason across disparate data effectively.
It’s not their fault, of course. The modern data stack has undergone a decade+ transition from disparate data sources to consolidated data and cleaned definitions (which is good), but even then the consolidation is never perfect and a lot of messiness is introduced. The general market evolution has been as follows:
- The rise of the modern data stack – We’ve covered the transformational rise of the modern data stack with Tristan Handy from dbt in the past and in our own reference architectures. The general evolution over the past decade has transformed data architectures across ingestion, transformation, warehousing, and storage to centralize data and make it quickly and easily accessible. The idea is then with cleanly organized data, teams could simply write SQL to derive data from their data warehouses, power charts/dashboards, and enable business intelligence across an entire organization.
- The agent frenzy – In 2024 moving into 2025 as LLM capabilities increased, essentially every single organization wanted to build and deploy agents on top of their existing data stacks. We’ve previously discussed how we define agents, but from an organizational point of view the natural allure of more work being done with greater efficiency and less time naturally led to the gravitation towards agentic workflows. Companies attempted to build “chat with your data” chatbots, support agents, etc. The frenzy was both bottoms-up and tops-down – developers wanted to make use of the newest, shiniest LLM capability and leadership applied AI adoption pressure to increase automation and reduce costs.
- Hitting the wall – Despite the initial optimism, it quickly became clear that most of these efforts failed. Organizations tried to deploy their agents but ran into a wall. MIT famously published their “State of AI in Business 2025” report which stated that with AI deployments, “most fail due to brittle workflows, lack of contextual learning, and misalignment with day-to-day operations.”
A crucial reason agents didn’t work well was a lack of proper data context. Enterprise data today is still incredibly disparate and messy – and because of that, data agents struggled to answer basic questions like “what was revenue growth last quarter?” across various data architectures amassing structured and unstructured data.
Just like how the vision of fully self-serve analytics of years ago fell short, the vision for data agents seemed to fall short as well.
The context problem – beyond just text to SQL
So why did that initial era of agent deployments struggle? At first, many believed the issue to be a fundamental data reasoning and SQL/Python codegen gap on the model side. The general idea was that a model should be able to take in a natural language query as an initial input, reason over existing data systems, and generate corresponding SQL code in traditional business intelligence (BI) fashion to pull the right data and answer the initial question accordingly.
If the model failed or wasn’t accurate, the gap was chalked up to the model not being good at SQL with the expectation that model performance would improve.
This is not entirely false. While model capabilities have improved dramatically for use cases like codegen and mathematical reasoning, they still lag behind on the data side (as evidenced through SQL benchmarks like Spider 2.0 and Bird Bench). There have undoubtedly been big leaps in models’ abilities, but we’ve quickly learned that the problem extends beyond just text to SQL.
To crystallize things and break down the revenue growth example a bit more:
- Let’s say a data agent is constructed internally within an organization. It’s built to leverage modern foundational models, connected to all the right data sources, and is hooked up to a nice UI to field data questions from internal users.
- Our query comes in. “What was revenue growth last quarter?” A deceptively simple question that is typically easily answered by a quick glance at a Looker or Tableau dashboard – shouldn’t be a challenge for an advanced, intelligent agent!
- Challenge #1 – how does the agent know how revenue or quarters are actually defined? Revenue is actually a business definition that isn’t hard-coded into a warehouse or pipeline. Is the user looking for run rate revenue or ARR? Fiscal quarter reporting may not be normalized for all organizations and could be a completely different three month period depending on the company you ask. What’s the right time window to look at?
- Luckily the head of the data platform steps in and says – “we’ve built semantic layers to solve this exact problem. We capture our revenue definition there.” And – the agent should be able to ingest all semantic layers as context. A promising potential solution, but the team takes a look at a couple of YAML files and realizes that they were updated by a data team member that left last year, no longer used by BI tools, and also doesn’t include the two new product lines that have launched since then. The agent has no idea how revenue is actually defined today.
- To overcome this blocker, a team member hard codes the exact revenue and timeframe definitions. The data agent continues chugging along but quickly runs into challenge #2 – where are the right data sources? Which ones are the right sources of truth? Raw data is split across multiple tables and warehouses. The finance team uses the fct_revenue table which could be correct, but the data team has materialized views created like mv_revenue_monthly and mv_customer_mrr.
It’s clear that data agents need access to a repository of up-to-date business definitions and data sources to overcome these problems.
Enter the context layer
The crux of the problem at hand is that the agent isn’t given the proper business context to answer even the most basic questions. This is representative of a larger gap that’s present in building automated AI systems within organizations – there needs to be up-to-date and maintained context that not only understands how an enterprise works and how the data systems are structured, but also maintains the tribal knowledge to tie everything together.
This has led to the evolution of the context layer. Many names have emerged in discussion today – context OS, context engine, contextual data layer, ontology, and more – but the underlying concept remains the same. Tie together all of an enterprise’s messy data, add a contextual layer on top that helps agents understand business logic, and package it such that the context can be supplied to agents.
Context management déjà vu
But wait. Doesn’t what we’re describing sound eerily similar to a semantic layer…? There are indeed some similarities, but at the end of the day if agent workflows are to become truly autonomous they need a bit more than how semantic layers currently manifest.
A traditional semantic layer in the context of BI is great for specific metric definitions (like revenue, churn, ARPU). However, they are usually hand constructed by data teams using very specific syntax through a dedicated layer like LookML and are connected directly to a BI tool like Looker.
A modern data context layer should essentially become a superset of what a semantic layer would traditionally cover. Sure, specific metric definitions can be hard-coded, but a modern context layer should include more to ensure agent autonomy – canonical entities, identity resolution, specific instructions to dissect tribal knowledge, proper governance guidance, and more.
This piece will primarily focus on data context that ties together traditional systems of record. An equally important and overlapping opportunity is also capturing an organization’s decisions and workflow logic so truly multipurpose agents can be built that are properly grounded in all of an organization’s data and decisioning context.
Putting it all together
Based on our recent conversations with customers and understanding their needs, here’s what we believe a modern context layer paired with an agentic data system could look like, broken down step-by-step:
1) Accessing the right data – the first order of business is ensuring all the right data is accessible. This is table stakes. Ideally an organization would be implementing some form of the modern data stack with some degree of unification through a lakehouse architecture. Even then, we’d want to ensure the agent has access to all the data it needs, which may extend beyond just what’s available in warehouses and operational apps. This includes tribal knowledge captured in internal systems, GDrive/Slack, etc.
2) Automated context construction – once all the right data is accessible, the next step is starting the construction of the context layer. The benefit of using LLMs is that a lot of the initial context gathering can be done in an automated way. An emphasis of focus should be on high signal context – for example, looking through past query history can be high signal in determining the most referenced tables and most common joins, and data modeling solutions like dbt or LookML can provide clear definitions for business metrics.
3) Human refinement – Automated context construction may be able to form a large portion of the context corpus, but it can’t create the full picture. It’s tempting to set agents loose and have them collect all internal knowledge, but some of the most important context is implicit, conditional, and historically contingent, and only exists as tribal knowledge inside teams.
Human input provides the final crucial links that enable true agent automation. For example – “for CRM data, look at Affinity for all new USCAN deals from 2025 onwards but Salesforce for all global leads before that.”
In this way the context layer can become a multi-dimensional corpus where code lives alongside natural language, capturing any context an agent might need. Just like developers can set up .cursorrules files to guide agents and control output behavior, data practitioners can maintain rules and guidelines.
4) Agent connection – once the context layer is properly constructed, it just needs to be exposed to agents and accessible real-time. This can typically be done through API or MCP.
5) Self-updating context flows – While the initial system has been set up correctly, data systems are never static and as a result the context layer shouldn’t be either. Data sources and formats can change upstream and individuals may have custom instructions they’ll want to add and modify based on changing business requirements. In the case a data agent provides incorrect data and requires accuracy refinement, that should of course be incorporated back into the context layer. In this way the context layer becomes a living and constantly evolving corpus.

One takeaway from this whole exercise is that building a proper data agent is no small feat. It’s a blend of technical challenges related to data infrastructure and engineering with human operational challenges related to tribal knowledge collection.
The OpenAI team recently published a fantastic piece detailing the creation of their own internal data agent. It’s a transparent detail of a very detailed and elegant implementation – but points to the long journey required to get there. Similarly, Palantir has a long history of constructing ontologies for organizations that provide clear context from messy data, and have built a big business doing so.
Market direction
Naturally, that opens up a window for an external solution. Realistically not every enterprise can (or should) build this in house, and we’re starting to see various solutions coming to market already.
While we believe we’re still early in seeing solutions come to fruition, the below is a high level market map of solutions being built:
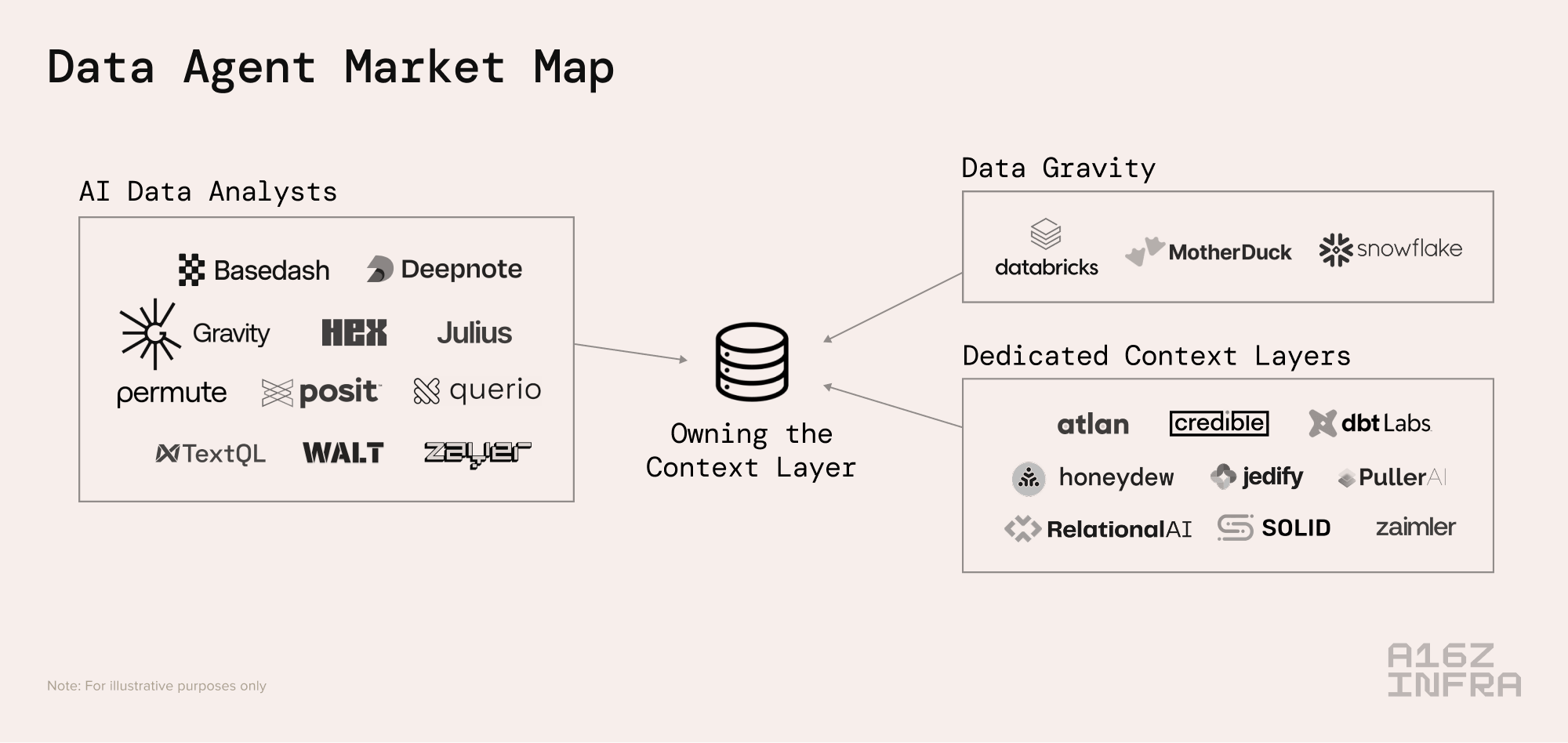
To break the categories down:
Data gravity platforms – platforms like Databricks and Snowflake have already gone through the motions of data ingestion, transformation, and storage and data gravity is powerful. They are already working on AI data analyst products like Databricks Genie and Snowflake Cortex Analyst which are built on top of data warehouses and utilize foundational models for text to SQL to allow users to ask questions about their data in natural language.
While these platforms don’t have super sophisticated context layer functionalities per se, they do allow for lightweight semantic modeling and there’s a feasible path forward through either company acquisition or in-house development for context layers to be brought in on platform.
Existing “AI data analyst companies” – there’s a wave of companies that have already emerged utilizing AI to allow customers to chat with your data. Many have realized through time in market that the key to effective data agents is actually building the relevant context layer. As a result, some have evolved to encompass data context construction as a key part of their products.
New, dedicated context layer companies – a new category of company has emerged that is building context layers from the ground up. They will have to go through our journey above of ingesting data, collecting tribal knowledge, and more – and will have to do so for each individual customer they work with.
Looking forward
We are at an interesting point in time of market development, where the problem of a lack of context has become apparent, but we are still in the early innings of building solutions.
The future is exciting – perhaps the vision of truly self-serve analytics can be fully realized, and BI, data analytics, and data science can be transformed through AI.
Naturally, many open questions still remain. Where will this context layer live? Can it live in multiple places? Will it be its own standalone product?
We remain excited about the opportunities for innovation here. If you’re building in the space, we’d love to chat! Please reach out at jcui@a16z.com or @jasonscui on X.

