Is software losing its head?
Last month Salesforce announced it would open its APIs and launch a headless product, essentially betting that in an agentic world, its value lies in the data layer, not the UI. It’s a smart repositioning. (Although it’s worth noting that not much appears to have changed technically: the APIs Salesforce is now marketing as a “headless product” have largely existed for years. In other words it was a classic Salesforce marketing launch.) The idea behind the new product is that agents can access the data from the system of record without needing to interact with the UI, which is designed for humans to track workflows.
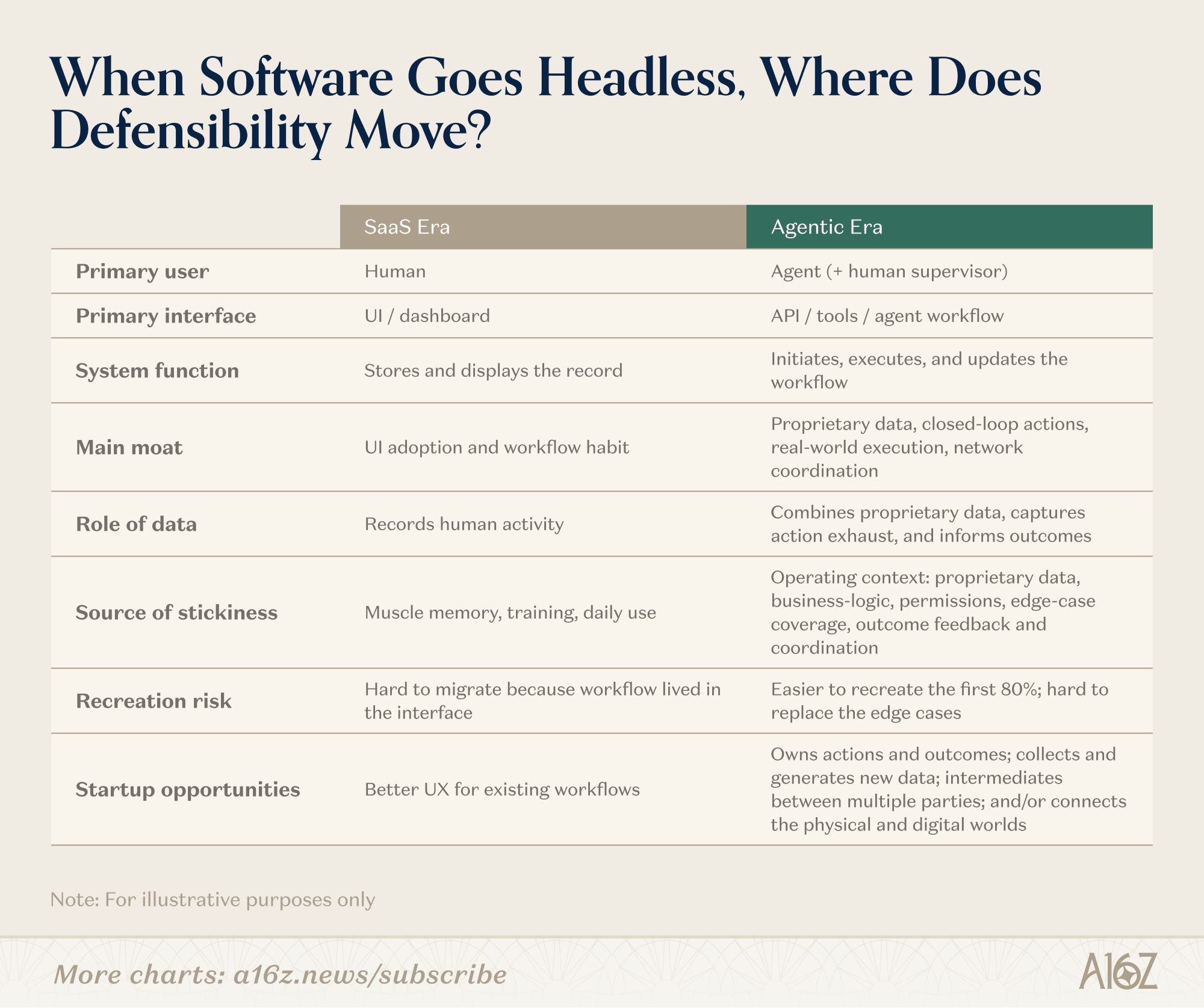
The announcement is a useful prompt for a more interesting question: if you strip away the UI and expose the database, what are you actually left with? How is that different from a Postgres database, a well-designed schema, and an API? Do the classic factors that make systems of record durable persist, or is there a new set of criteria? In the SaaS era, the system of record was defensible because humans lived in the interface. In the agentic era, that advantage weakens. The defensible layers shift downward into data models, permissions, workflow logic, and compliance, and upward into networks, proprietary data generation, and real-world execution.
When software goes headless, where does defensibility move?
The UI was the product
A system of record is the authoritative source of truth for a given domain of business data. It’s the place where the official version of a customer relationship, an employee record, or a financial transaction lives, the system other tools read from and write back to. A CRM is the system of record for revenue. An HRIS is the system of record for people. An ERP is the system of record for money. What makes them powerful isn’t just that they store data, it’s that they become the shared reality an entire organization operates from.
For the last two decades, Salesforce sold a way for sales leaders to run their teams. The dashboards, pipeline views, forecasting tools, and activity feeds were what people were buying. Their business model was predicated on selling seats to users that provided access to these features. The database underneath was critical, but incidental.
Which means the UI drove stickiness. It enforced data hygiene. It created shared vocabulary: Leads, Opportunities, Accounts. It made thousands of sales reps enter data they otherwise wouldn’t have. The UI has been the mechanism that kept the data coherent. The product is so sticky that many sales leaders insist on bringing Salesforce with them to new jobs not because the UI is good, but because it is muscle-memory.
Agents are beginning to upend this model. Instead of interacting through the UI, they can read and write directly to the underlying data, which has prompted a wave of new tools and workarounds that bypass the interface entirely (Salesforce isn’t the only example here: we recently wrote about how SAP is seeing an entire AI-friendly ecosystem proliferate around it). Computer using agents also make the traditional human level factors like preferences, training, undocumented context obsolete over time. In other words, the requirements to be a durable system of record are evolving.
The historical scorecard
Before asking what changes in an agentic world, it’s worth being precise about what drove stickiness for a system of record in the first place. The first few really focus on how humans interact with software and their preferences. Software was made sticky largely by the UI, habit, human workflow and embedded process.
How frequently is it accessed? A CRM is used every day by the GTM team and beyond. That frequency makes it critical infrastructure, and the human layer built on top of it, such as rituals, muscle memory, management cadences built over years, is often the hardest thing to migrate, because it’s not even recognized as something that needs migrating.
Is it write-only or read-write? A sticky SoR is a read-write SoR. A CRM, for example, isn’t a write-only archive; it’s being read constantly. Every call logged, every stage updated, every task created was inputted by someone (who presumably cared about what they were doing). That bidirectional flow means any replacement has to handle live operational data, not just a historical export. There’s no safe moment to cut over, which means that enterprises tend to stick with a provider once they’ve onboarded. On the flip side, an applicant tracking system (ATS) tends to be write-only, there are limited reasons to return to the data after the hire has been made.
How many undocumented SOPs are there? Business-critical context doesn’t live in any wiki; it’s encoded in workflow rules built up over years by admins and system integrators. In the sales example, the undocumented context is that enterprise deals over $100K need VP approval, EMEA deals require privacy review, and strategic logo discounts can bypass finance only at quarter-end. And this context is often what makes the difference between something getting done in a timely fashion (or without violating some important practice) or not happening at all. Migrating means reverse-engineering every automation, or losing the institutional memory entirely.
Are there a lot of internal or external dependencies? The core question is how many internal systems, team processes, or outside stakeholders depend on this system of record. Internal connectivity refers to other software or workflows downstream of it. External connectivity refers to outside parties like auditors, accountants, or regulators who need direct access to the data for something like an ERP. The higher the connectivity on either dimension, the more that needs to be untangled during a migration.
How critical is the data from a compliance perspective? The core question here is simply: is this system compliance-critical? Compliance-critical systems like payroll, ERPs, and HR data require a legally defensible source of truth, strict admin access controls, and direct involvement from auditors and regulators in any migration. That makes them significantly stickier. Sales data and customer support tools like Zendesk sit at the other end: you care about continuity and context, but there’s no regulatory exposure if data moves or someone gains access.
Not all systems of record have carried the same switching cost. Score a CRM against an Applicant Tracking System (ATS) across these same dimensions and the gap is stark. An ATS is a workflow tool for a bounded process: recruiting. Once a candidate is hired or rejected, that record is largely write-once. The integrations are narrower. The user base is small and concentrated.
An ERP sits at the other extreme: the ledger is the audit trail, and your accountants, auditors, and regulators become direct stakeholders in any migration. Replacing your ATS is painful but survivable. Replacing your CRM is open-heart surgery. Replacing your ERP is open-heart surgery while the patient is running a marathon.

Traditionally, systems of record have not taken advantage of moat-creators like proprietary data or network effects; the workflow typically created enough of a moat. If anything, consumer businesses have brought together tools and a network; historically SORs have not.
Proprietary Data – While many systems of record collected customer data, they didn’t really do much with that data (and often contractually couldn’t). So while a CRM has a rich set of data and could aggregate across customers to generate cross-customer insights, they never did in a meaningful way (although there have been some attempts like Salesforce’s Einstein).
Network Effects – The holy grail would have been network effects. The CRM becomes more valuable because software sellers can find buyers. Like data, network effects have been weak at best for systems of record historically.

So if the UI disappears — and agents arrive — what’s left?
An agent doesn’t need a browser. It needs an API, context, instructions, and the ability to act. Two things made this possible at scale: LLMs became capable enough to reason. As such, an agent can now read context, form a plan, select tools, execute actions, and review output, without a human in the loop for most tasks. And MCP standardized tool access, giving agents a common interface to call external capabilities. An agent with MCP access to your platform can do what a human user does in milliseconds, at scale, without a browser. With the right context, computer-using agents should be able to navigate incumbent software interfaces without even needing APIs.
Simplistically looking at it, there are now three paths for a software buyer:
1) Incumbent system + agents. Use the incumbent’s CLI and APIs — either through their native agent product (Salesforce’s Agentforce, SAP’s Joule) or by building your own agents on top. (Suspend disbelief that APIs are complete and usable and that going headless is not as operationally complex as it is.)
2) DIY the system of record entirely. Build your own data model, operational logic, and things like permissioning, audit trails, integrations, etc. and your own agents from scratch (likely leveraging third party agent building and database tools).
3) Buy an AI-native replacement. Buy the new generation of software built from the ground up for the agentic era, designed for machine readability, with agent orchestration as a first-class feature rather than a bolt-on. This could be headless.
So, what stays from the old scorecard? The elements driven by human behavior and preferences fade away like frequency of access or read vs. read-write which are related to human muscle memory. Agents may kill muscle memory as a moat, but they do not kill operational logic and context as a moat. If anything, they make that logic more important, because agents need explicit rules, permissions, and process definitions in order to act safely.
Undocumented SOPs stay important in the short-term. The institutional logic encoded in your workflow rules is exactly what agents need to operate correctly on your behalf. It’s also the hardest thing to reconstruct. That doesn’t export cleanly, yet, especially when there are still humans involved in some part of the process. However, capturing context is becoming easier, and as agents replace more labor this becomes less relevant.
Connectivity is still hard to unwind and extends further. The connectivity factor shifts. It’s less about keeping up with humans and more about maintaining connectivity across traditionally siloed functions and software. A CRM agent needs to stitch together data and context across sales, billing and customer success. And if your platform is also the node through which agents from multiple external organizations transact buyers, sellers, partners, the dependency deepens further. An incumbent with agents is going to have a tougher time working across the primitives of various underlying software, as would a DIY database and set of agents.
Compliance-critical data remains important. Data for regulators or with regulatory or legal risk needs a single trusted source of data. A customer is less likely to switch if they trust their existing product. Take payroll and accounting data – an agent might want to access this data, you’re less likely to build and maintain this in-house. In a fully agentic world, one of the hardest unsolved problems is: which agents are authorized to do what, on whose behalf, with what auditability? A system of record that becomes the identity and permissioning layer for agent-to-agent interactions has a structural role that’s genuinely hard to displace, not because of the data it holds, but because of the trust architecture it enforces.
Going forward an increasingly relevant set of factors become important for driving defensibility for AI native startups:
How hard is it to recreate the SoR? – Data is going to matter more in a few ways. First, in the near term, the ease in extracting and recreating the data that underlies the system of record. AI is making this easy with a number of tools that enable a user to do this. In the near term, incumbents can and will make this harder by making APIs painful, gated, incomplete, or economically unattractive, if APIs are even provided at all. But as the extraction tools get better, particularly as computer using agents improve, they will make it even easier. Simultaneously, of course, new companies are recreating a richer set of data from emails, phone calls and voice agents, and internal documents. AI lowers the cost of recreating the first 80% of a system of record. The remaining 20%, which are the exceptions, approvals, compliance requirements, and edge-case workflows, is still what separates a useful wedge from a true replacement.
Is there meaningful proprietary data? – Second, the data itself becomes more interesting. The defensible data is not the data you import; it’s the data your product uniquely causes to exist. We talk about walled gardens of data – data that is either proprietary, regulated, or constantly needs to be updated. A software provider that has invested in collecting authoritative and complete data has an advantage over general-purposed providers or competitors that don’t have this data. Another vector here around data is when the data depends on internally generated actions. The best businesses won’t just warehouse data entered elsewhere. They will generate new data exhaust through being in the loop and include things like observed behavior, response rates, timing patterns, process outcomes, benchmarks, exception patterns and agent performance traces. The key thing here is that the data is the context now.
Does it own the action layer? – In the old world, storing the record was enough. In the new world, agents take action and defensibility may shift toward products that can operate in a closed loop from taking the action, to capturing, the outcome, to using that feedback to improve future decisions. For an ERP, this could be approving spend, triggering payroll, reconciling invoices, sending notices, etc. Products that close the loop are more defensible because they sit inside execution, not just observation: they generate unique data, improve with use, and become harder to remove without breaking the workflow. The value here increases of course with more context gathered and more edge cases handled.
Is there a real-world execution element? – Business models that have connectivity into real-world operations that will not be fully automated. The obvious examples are businesses with an operations network built out, like DoorDash, which historically were not systems of record but are instructive here. More broadly, any software business that closes the loop into services, fulfillment, logistics, field operations, or payments has a different kind of defensibility than pure SaaS. These companies do not just store the record or recommend an action; they dispatch people, move goods, or complete the service.
For builders, this suggests opportunity in markets where software can increasingly decide and agents can increasingly coordinate, but where the final mile still requires execution in the real world. For example, vertical software tied to field services.
Are there network effects? – Historically, network effects were weak in most systems of record because the software was primarily internal. But in an agentic world, network effects may become much more important if the system is embedded in a multi-party workflow. If the system mediates recurring interactions between multiple parties like buyers and sellers, employers and employees, companies and auditors, vendors and customers, payers and providers, then each additional participant can make the network more useful to the next.
One way is via shared workflow coordination: the product becomes the place where both sides of a process transact, exchange context, and resolve exceptions. Another is through benchmarking and intelligence: the system can surface norms, anomalies, and recommendations based on patterns observed across the network, which works together with the data point above. And a third is through trust and standardization: once counterparties begin to rely on the same rails for approvals, handoffs, compliance, or payments, the product becomes harder to displace because it is no longer just a database, but part of the coordination infrastructure for the market itself.
How technically capable is the buyer? – In a world where anyone can theoretically build their own agents, there is still a wide range in buyers’ actual ability to do so. Especially in vertical end markets and among functional buyers that have historically not had strong internal engineering resources, the odds that they will build, maintain, and continuously improve their own database, workflow logic, agent stack, and governance layer remain low. Cost matters here too: DIY may reduce software licensing in theory, but often shifts spend into implementation, maintenance, and internal complexity. This means there is real opportunity in categories where the buyer’s operations are operationally complex but technically underserved which is true of much manufacturing, construction back-office, industrial and field-service workflows, or for areas like accounting.
There are a few other important factors, which will also be table stakes for software. For example, the ontology needs to be different. A lot of “DIY database” thinking underestimates how much value lives in the object model itself. Incumbent software was built for dashboards, reports, and humans, capturing workflow. This would be opportunities, tickets, candidates, etc. Agentic schema needs to capture reasoning, actions, state tracking, exception handling, delegation, and coordination across systems. The native object model might become tasks, intents, threads, policies, or outcomes instead.
Similarly, permissioning needs to be updated for managing agents, not just humans. This includes: who can do what, through which agent, under what policy, with what approvals, with what audit trail, and with what rollback / exception handling.
And of course, all of this is in the context of cost (e.g. how much it costs to build and maintain agents/database, how much the API access costs), which again circles back to things like how hard it is to recreate the data and the number of dependencies.
So where does this leave us?
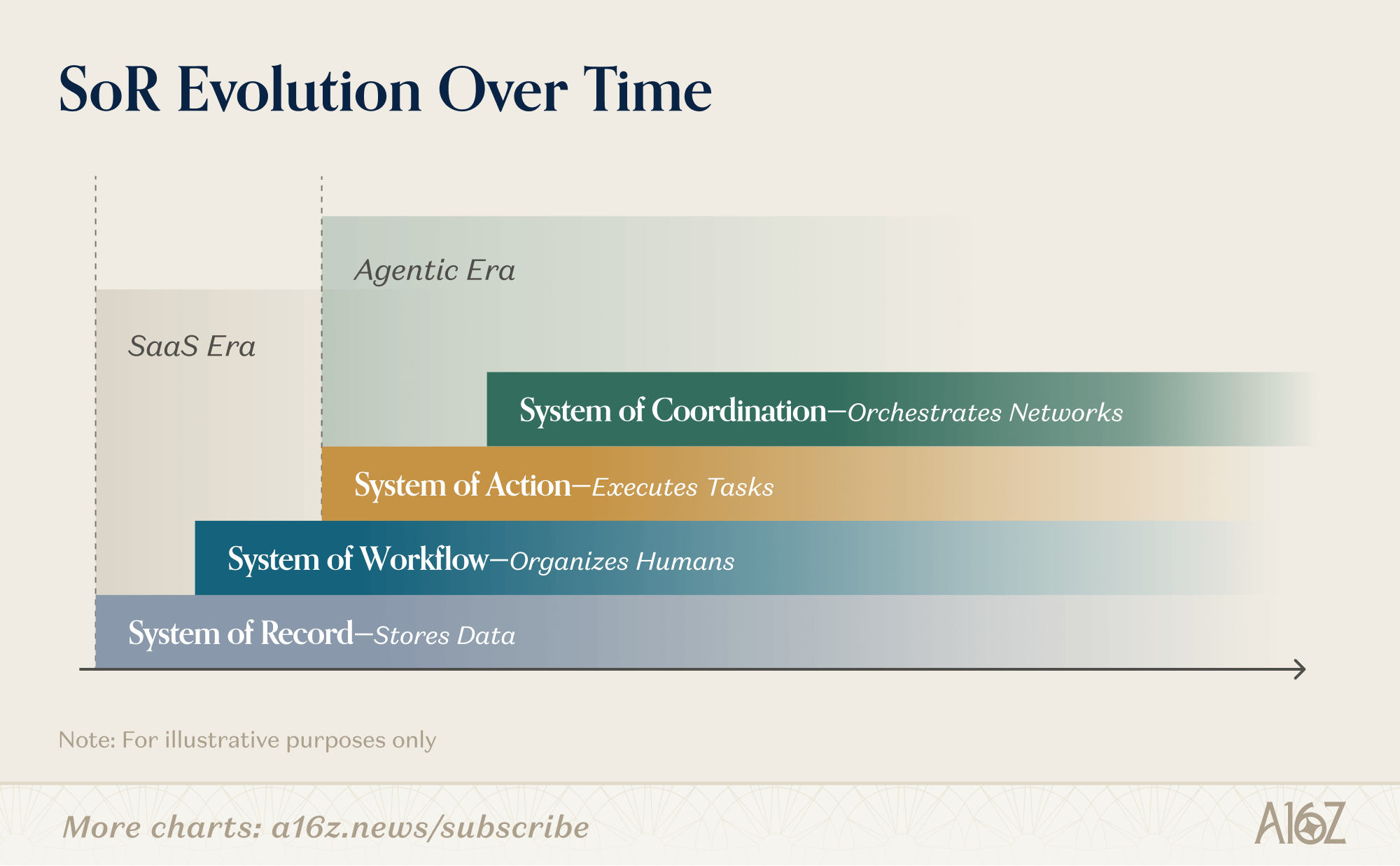
As incumbents go headless, they are making an implicit bet that the data layer will remain the source of value. In some categories, especially those that are deeply compliance-bound like financial services, that bet may hold for some time and going headless may be farther away. For the software builder, the opportunity to compete against the incumbents as they go headless and build durable software changes. The next generation of systems of record are already starting to look different: not just repositories of data collected to log human work, but agentic such that they capture the context, initiate the work and record the data exhaust. Moreover, the most interesting businesses will extend into real-world execution, coordinating the likes of field workers, logistics providers, service teams, and physical assets, or sit between multiple parties. They will be mixing the business models of the old world, and the core of the traditional system of record, the data, will be what sits in the background.
A big thank you to Angela Strange for her thought partnership on this!
