AI has enormous potential to disrupt markets that have traditionally been out of reach for software. These markets – which have relied on humans to navigate natural language, images, and physical space – represent a huge opportunity, potentially worth trillions of dollars globally.
However, as we discussed in our previous post The New Business of AI, building AI companies that have the same attractive economic properties as traditional software can be a challenge. AI companies often have lower gross margins, can be harder to scale, and don’t always have strong defensive moats. From our experience, many of these challenges seem to be endemic to the problem space, and we’ve yet to uncover a simple playbook that guarantees traditional software economics in all cases.
That said, many experienced AI company builders have made tremendous progress in improving the financial profiles of their companies relative to a naive approach. They do this with a range of methods spanning data engineering, model development, cloud operations, organizational design, product management, and many other areas. The common thread that often guides them is a deep, practical understanding of the problem to be solved.
So while our previous post outlined the challenges facing AI businesses, the goal of this post is to provide some guidance on how to tackle them. We share some of the lessons, best practices, and earned secrets we learned through formal and informal conversations with dozens of leading machine learning teams. For the most part, these are their words – not ours. In the first part, we’ll explain why problem understanding is so important – particularly in the presence of long-tailed data distributions – and link it to the economic challenges raised in our last post. In the second part, we’ll share some strategies that can help ML teams build more performant applications and more profitable AI businesses.
We are hugely bullish on the business potential of AI and continue to invest heavily in this area. We hope this work will continue to spark discussion and support founders in building enduring AI companies.
Note: The focus of this post is AI companies and products that rely on machine learning – primarily supervised learning – to deliver a significant portion of their core functionality, not on ML tooling / infrastructure or traditional software that includes add-on ML features.
Part I: Understanding the problem to be solved
Building vs. experimenting (or, software vs. AI)
As the CTO of one late-stage data startup put it, AI development often feels “closer to molecule discovery in pharma”* than software engineering.
This is because AI development is a process of experimenting, much like chemistry or physics. The job of an AI developer is to fit a statistical model to a dataset, test how well the model performs on new data, and repeat. This is essentially an attempt to reign in the complexity of the real world.
Software development, on the other hand, is a process of building and engineering. Once the spec and overall architecture for an application have been defined, new features and functionality can be added incrementally – one line of code, library, or API call at a time – until the full vision takes shape. This process is largely under the control of the developer, and the complexity of the resulting system can often be reigned in using standard computer science practices, such as modularization, instrumentation, virtualization, or choosing the right abstractions.
Unlike software engineering, very little is in the developer’s control with AI applications – the complexity of the system is inherent to the training data itself. And for many natural systems, the data is often messy, heavy-tailed, unpredictable, and highly entropic. Even worse, code written by the developer does not directly change program behavior – one experienced founder used the analogy that “ML is essentially code that creates code (as a function of the input data)… this creates an additional layer of indirection that’s hard to reason about.”**
The job of an AI developer is to fit a statistical model to a dataset, test how well the model performs on new data, and repeat. This is essentially an attempt to reign in the complexity of the real world.The long tail and machine learning
Many of the difficulties in building efficient AI companies happen when facing long-tailed distributions of data, which are well-documented in many natural and computational systems.
While formal definitions of the concept can be pretty dense, the intuition behind it is relatively simple: If you choose a data point from a long-tailed distribution at random, it’s very likely (for the purpose of this post, let’s say at least 50% and possibly much higher) to be in the tail.
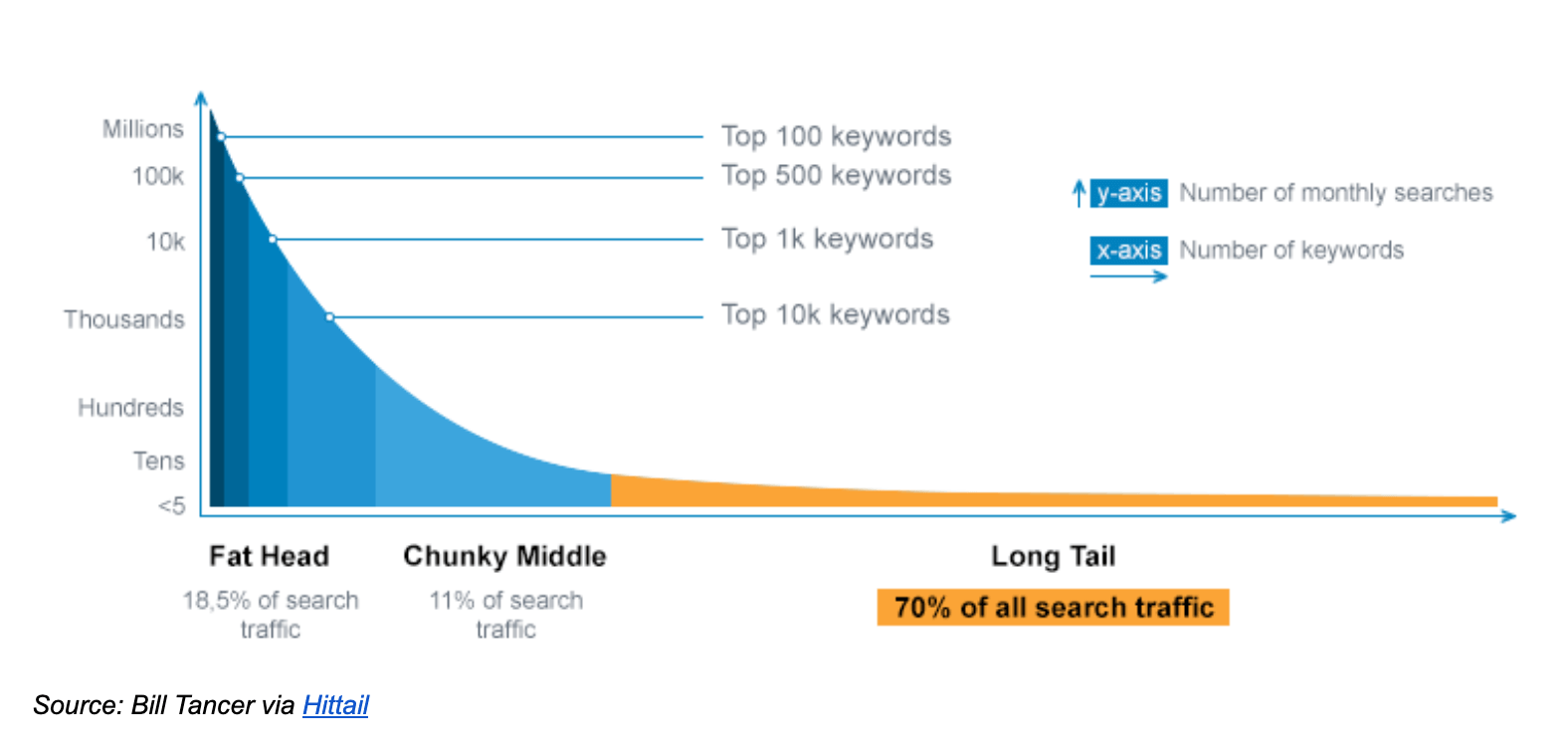
Take the example of internet search terms. Popular keywords in the “head” and “middle” of the distribution (shown in blue below) account for less than 30% of all terms. The remaining 70% of keywords lie in the “tail,” seeing less than 100 searches per month. If you assume it takes the same amount of work to process a query regardless of where it sits in the distribution, then in a heavy-tailed system the majority of work will be in the tail – where the value per query is relatively low.
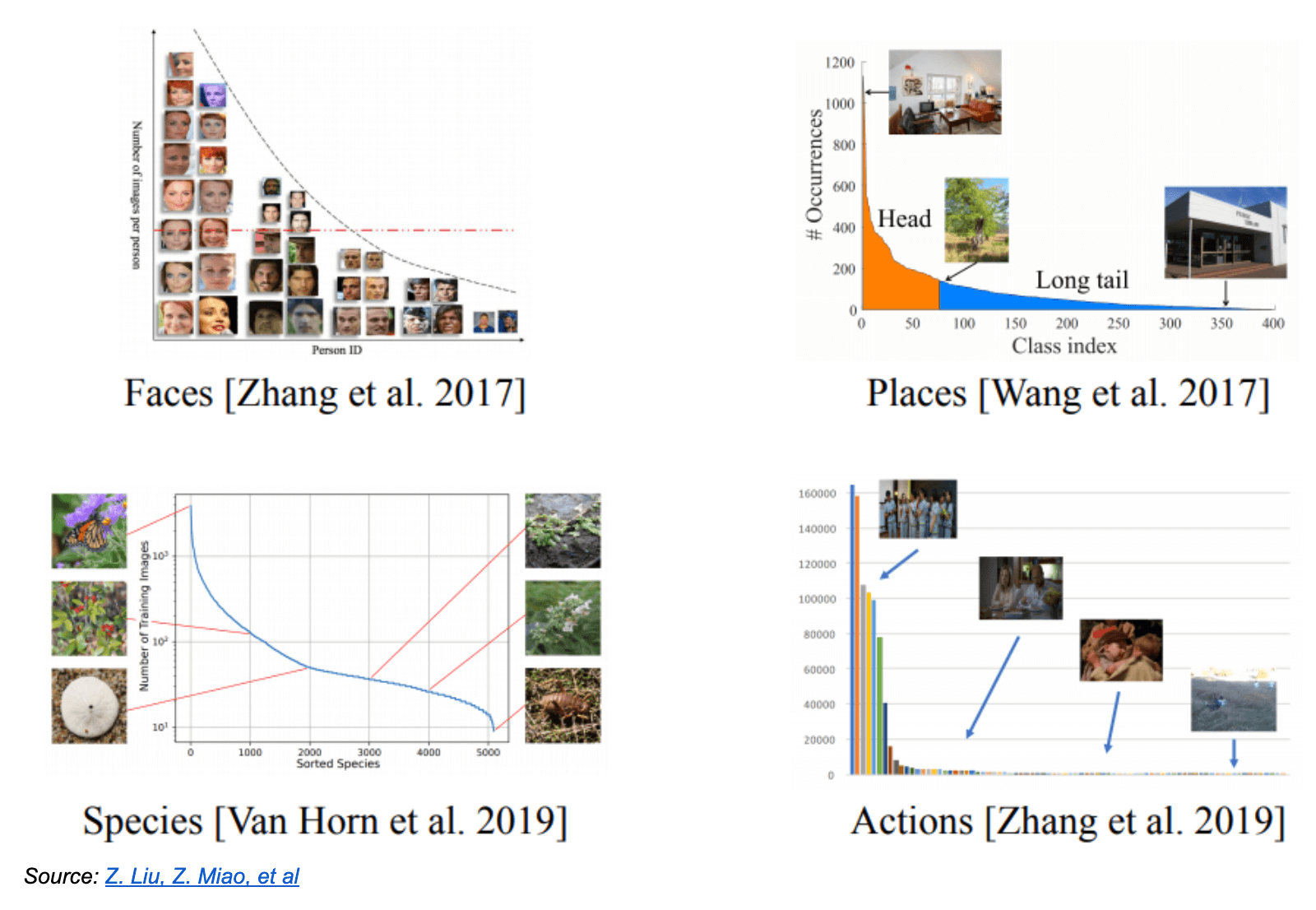
It’s becoming clear that long-tailed distributions are also extremely common in machine learning, reflecting the state of the real world and typical data collection practices. These charts, for instance, show the frequency of model classes in several popular AI research datasets.
These types of distributions are not necessarily bad. But – unlike the internet search example – current ML techniques are not well equipped to handle them. Supervised learning models tend to perform well on common inputs (i.e. the head of the distribution) but struggle where examples are sparse (the tail). Since the tail often makes up the majority of all inputs, ML developers end up in a loop – seemingly infinite, at times – collecting new data and retraining to account for edge cases. And ignoring the tail can be equally painful, resulting in missed customer opportunities, poor economics, and/or frustrated users.
Since the tail often makes up the majority of all inputs, ML developers end up in a loop – seemingly infinite, at times – collecting new data and retraining to account for edge cases.Impact on the economics of AI
The long tail – and the work it creates – turn out to be a major cause of the economic challenges of building AI businesses.
The most immediate impact is on the raw cost of data and compute resources. These costs are often far higher for ML than for traditional software, since so much data, so many experiments, and so many parameters are required to achieve accurate results. Anecdotally, development costs – and failure rates – for AI applications can be 3-5x higher than in typical software products.
However, a narrow focus on cloud costs misses two more pernicious potential impacts of the long tail. First, the long tail can contribute to high variable costs beyond infrastructure. If, for example, the questions sent to a chatbot vary greatly from customer to customer – i.e. a large fraction of the queries are in the tail – then building an accurate system will likely require substantial work per customer. Unfortunately, depending on the distribution of the solution space, this work and the associated COGS (cost of goods sold) may be hard to engineer away.
Even worse, AI businesses working on long-tailed problems can actually show diseconomies of scale – meaning the economics get worse over time relative to competitors. Data has a cost to collect, process, and maintain. While this cost tends to decrease over time relative to data volume, the marginal benefit of additional data points declines much faster. In fact, this relationship appears to be exponential – at some point, developers may need 10x more data to achieve a 2x subjective improvement. While it’s tempting to wish for an AI analog to Moore’s Law that will dramatically improve processing performance and drive down costs, that doesn’t seem to be taking place (algorithmic improvements notwithstanding).
In what follows, we present guidance collected from many practitioners on how to think through and tackle these issues.
Part II: Building better AI systems
Toward a solution
So – many AI systems are designed to predict the interactions in complex underlying systems, resulting in long-tailed distributions of input data. Developers usually can’t fully characterize the data, so they model it through a series of (supervised) learning experiments. This process requires a huge amount of work, can hit an asymptote in terms of performance, and causes or exacerbates many of the economic challenges facing AI companies.
This is the crux of the AI business dilemma. If the economics are a function of the problem – not the technology per se – how can we improve them?
There is no easy answer. The long tail is, in some ways, a measure of the complexity of the problem being solved – i.e. it’s the reason we need automation in the first place – and is directly correlated to the effort needed to tackle it. There are, however, ways to treat the long tail as a first-order concern and build for it.
We heard a ton of great advice from ML engineers and researchers on this topic. We share some of the best and most innovative guidance below.
The long tail is, in some ways, a measure of the complexity of the problem being solved and is directly correlated to the effort needed to tackle it. There are, however, ways to treat it as a first-order concern and build for it.Easy mode: Bounded problems
In the simplest case, understanding the problem means identifying whether you’re actually dealing with a long-tailed distribution. If not – for example, if the problem can be described reasonably well with linear or polynomial constraints – the message was clear: don’t use machine learning! And especially don’t use deep learning.
This may seem like odd advice from a group of AI experts. But it reflects the reality that the costs we documented in our last post can be substantial – and the causes behind them, covered in the first part of this post, difficult to work around. These problems also tend to get worse as model complexity grows, since sophisticated models are expensive to train and maintain. They can even perform worse than simpler techniques when used inappropriately, tending to overparameterize small datasets and/or produce fragile models that degrade rapidly in production.
When you do use ML, an engineer from Shopify pointed out, logistic regression and random forests are popular for a reason – they are interpretable, scalable, and cost-effective. Bigger and more sophisticated models do perform better in many cases (e.g. for language understanding/generation, or to capture fast-moving social media trends). But it’s important to determine when accuracy improvements justify significant increases in training and maintenance costs.
As another ML leader put it, “ML is not a religion, but science, engineering, and a little art. The vocabulary of ML approaches is quite large, and while we scientists tend to see every problem to be the nail that fits the hammer we just finished building, the problem might just be a screw sometimes if we look precisely.”
Harder: Global long tail problems
If you are working on a long-tail problem – which includes most common NLP (natural language processing), computer vision, and other ML tasks – it’s critical to determine the degree of consistency across customers, regions, segments, and other user cohorts. If the overlap is high, it’s likely you can serve most of your users with a global model (or ensemble). This can have a huge, positive impact on gross margins and engineering efficiency.
We’ve seen this pattern most often in B2C tech companies that have access to large user datasets. The same advantages often hold for B2B vendors working on unconstrained tasks in relatively low entropy environments like autonomous vehicles, fraud detection, or data entry – where the deployment setting has a fairly weak influence on user behavior.
In these situations, some local training (e.g. for major customers) is often still necessary. But you can minimize it by framing the problem in a global context and building proactively around the long tail. The standard advice to do this includes:
- Optimize the model by adding more training data (including customer data), adjusting hyperparameters, or tweaking model architecture – which tends to be useful only until you hit the long tail
- Narrow the problem by explicitly restricting what a user can enter into the system – which is most useful when the problem has a “fat head” (e.g. data vendors that focus on high-value contacts) or is susceptible to user error (e.g. Linkedin supposedly had 17,000 entities related to IBM until they implemented auto-complete)
- Convert the problem into a single-turn interface (e.g. content feeds, product suggestions, “people you may know,” etc) or prompt for user input / design human failover to cover exceptional cases (e.g. teleoperations for autonomous vehicles)
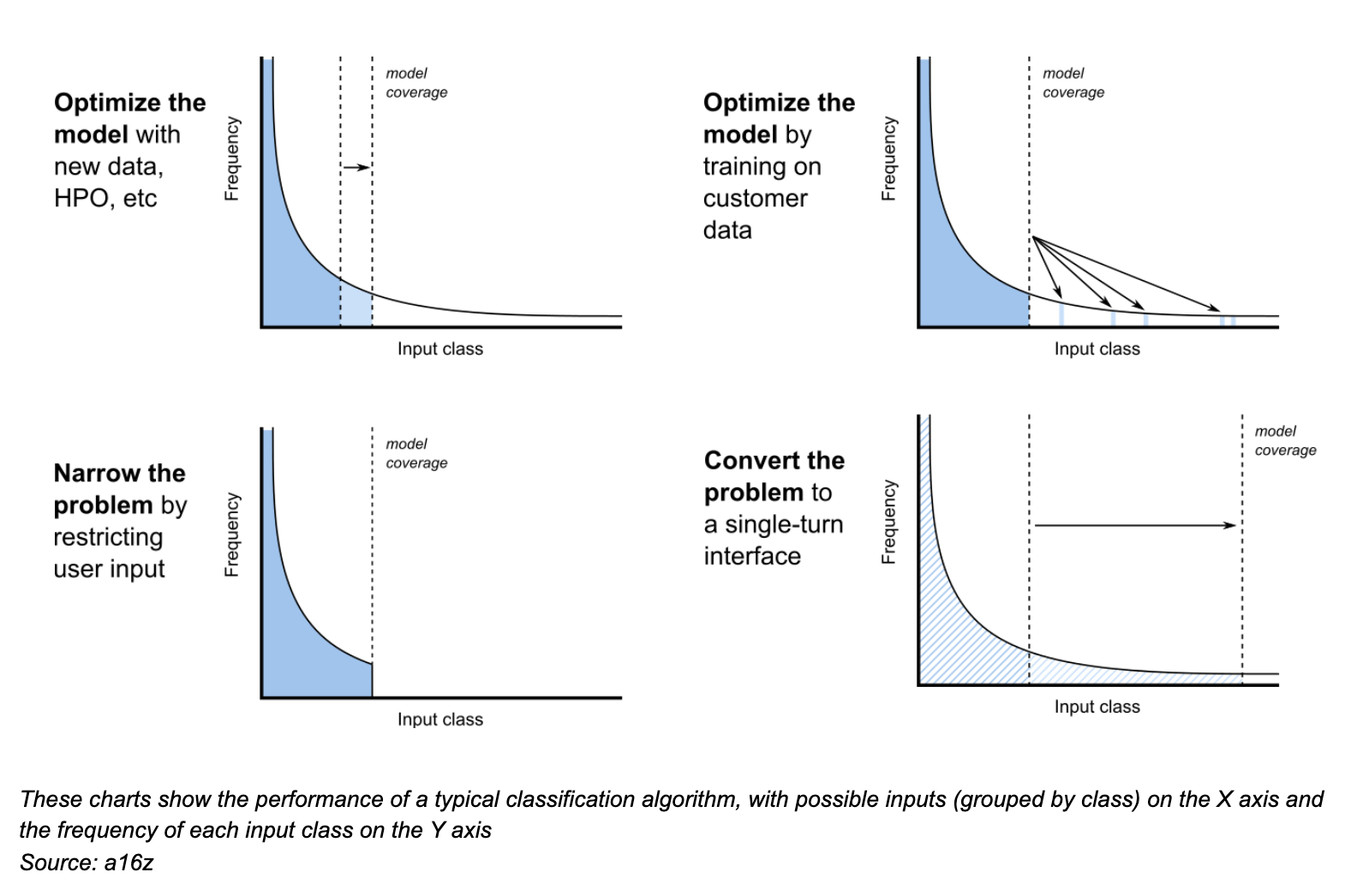
For many real-world problems, however, these tactics may not be feasible. For those cases, experienced ML builders shared a more general pattern called componentizing.
An ML engineer at Cloudflare, for example, shared an example related to bot detection. Their goal was to process a massive set of log files to identify (and flag or block) non-human visitors to millions of websites. Treating this as a single task was ineffective at scale because the concept of a “bot” included hundreds of distinct subtypes – search crawlers, data scrapers, port scanners, etc – exhibiting unique behaviors. Using clustering techniques and experimenting with various levels of granularity, though, they ultimately found 6-7 categories of bots that could each be addressed with a unique supervised learning model. Their models are now running on a meaningful portion of the internet, providing real-time protection, with software-like gross margins.
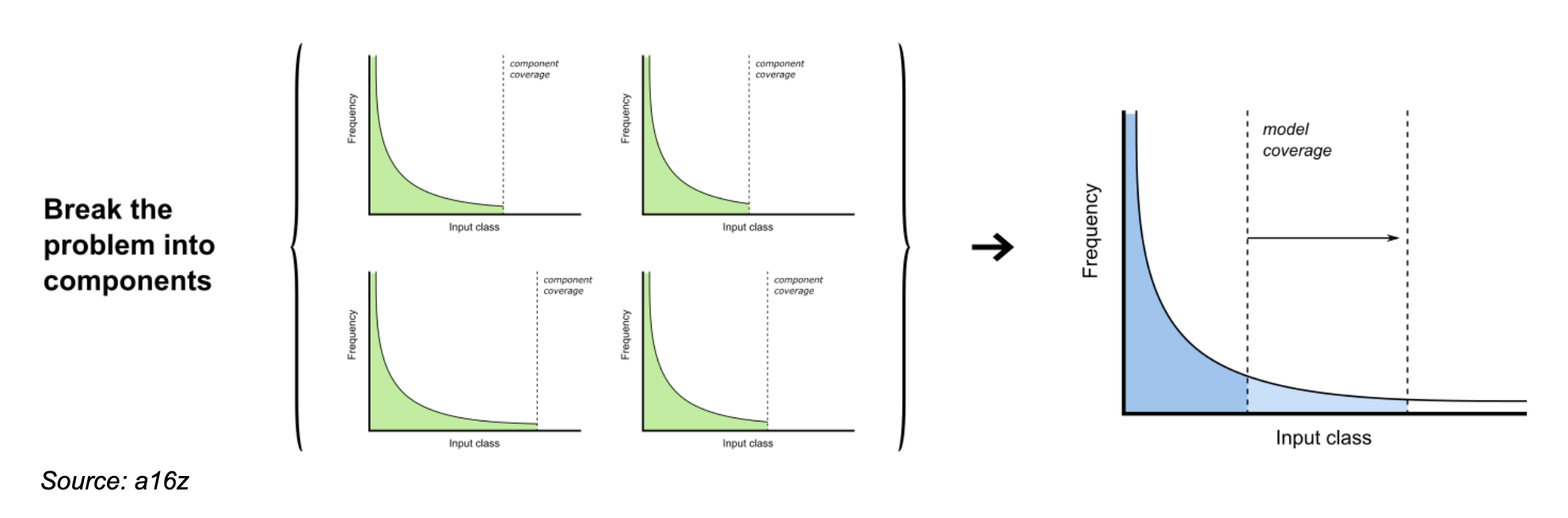
Componentizing is in use across many high-scale production ML systems, including advertising fraud detection, loan underwriting, and social media content moderation. The critical design element is that each model addresses a global slice of data – rather than a particular customer, for instance – and that the sub-problems are relatively bounded and easy to reason about. There is no substitute, it turns out, for deep domain expertise.
In componentizing, each model addresses a global slice of data and sub-problems are relatively bounded and easy to reason about.Really hard: Local long tail problems
Many problems do not show global consistency across customers or other user cohorts – nearly all ML teams we spoke with emphasized how common it is to see at least some local problem variation. Determining overlap is also nontrivial, since input data (especially in the enterprise) may be segregated for commercial or regulatory reasons. Frequently, the difference between a global problem and a local problem lies in the scope of available data.
Local ML problems still often have long-tailed distributions that must be addressed. But the work can quickly multiply based on the degree of local variation. A large music streaming company, for instance, found they needed unique playlist generation models for each country where they operate. Factory floor analytics vendors, similarly, often end up with a unique model for each customer or assembly line they service. While there is no simple fix for this, several strategies can help bring the benefits of global models to local problem spaces.
A near-term, practical option is the meta model pattern, in which a single model is trained to cover a range of customers or tasks. This technique tends to be discussed most often in a research setting (e.g. multi-task robots). But for AI application companies, it can also drastically reduce the number of models they need to maintain. One successful marketing startup, for instance, was able to combine thousands of offline, customer-specific models into a single meta model – which was much less expensive in aggregate to retrain.
Another emerging solution is transfer learning. There is widespread enthusiasm among ML teams that pre-trained models – especially attention-based language models like BERT or GPT-3 – can reduce and simplify training needs across the board, ultimately making it much easier to fine-tune models per customer with small amounts of data. There’s no doubting the potential of these techniques. Relatively few companies, however, are using these models heavily in production today – partly because their massive size makes them difficult and costly to operate – and customer-specific work is still required in many applications. The benefits of this promising area do not seem to be broadly realized yet.
Finally, several practitioners at large tech companies described a variant of transfer learning based on trunk models. Facebook, for instance, maintains thousands of ML models, most of which were trained separately for a specific task. But over time, models that share similar functionality can be joined together with a common “trunk” to reduce complexity. The goal is to make the trunk models as “thick” as possible (i.e. doing most of the work) while making the task-specific “branch” models as “thin” as possible – without sacrificing accuracy. In a published example, an AI team working on automated product descriptions combined seven vertical-specific models – one for furniture, one for fashion, one for cars, etc – into a single trunked architecture that was 2x as accurate and cheaper to run.
In the limit, this approach looks a lot like the global model pattern. At the same time, it allows for parallel model development and a high degree of local accuracy. It also gives data scientists richer, embedded data to work with and converts some O(n^2) problems – like language translation, where you have to translate each of n languages into n other languages – into O(n) complexity – where each language can be translated into an intermediate representation instead. This may be an indication of where the future is headed, helping to define the basic building blocks or APIs of the ML development process.
An AI team working on automated product descriptions combined seven vertical-specific models – one for furniture, one for fashion, one for cars, etc – into a single trunked architecture that was 2x as accurate and cheaper to run.Table stakes: Operations
Finally, many experienced ML engineers emphasized the importance of operational best practices to improve AI economics. These are a few of the most compelling examples.
Consolidate data pipelines. Model sprawl doesn’t have to mean pipeline sprawl. When global models weren’t feasible, one founder achieved efficiency gains by combining most customers into a single data transformation process with relatively minor impact to system latency. Other groups reduced costs by retraining less often (e.g. via a nightly queue or when enough data accumulates) and performing training runs closer to the data.
Build an edge case engine. You can’t address the long tail if you can’t see it. Tesla, for instance, assembled a huge dataset of weird stop signs to train their Autopilot models. Collecting long-tail data in a repeatable way is a critical capability for most ML teams – usually involving identifying out-of-distribution data in production (either with statistical tests or by measuring unusual model behavior), sourcing similar examples, labeling the new data, and intelligently retraining, often using active learning.
Own the infrastructure. Many leading ML organizations run (and even design) their own ML clusters. In some cases, this can be a good idea for startups, too – one CEO we spoke with saved ~$10 million annually by switching from AWS to their own GPU boxes hosted in colocation facilities. The key question for founders is to determine at what scale cost savings justify the maintenance burden – and how quickly cloud price curves will come down.
Compress, compile, and optimize. As models continue to get bigger, techniques to support efficient inference and training – including quantization, distillation, pruning, and compilation – are becoming essential. They are also increasingly available through pre-trained models or automated APIs. These tools will not change the economics of most AI problems but can help manage costs at scale.
Test, test, test. This may sound obvious, but several experts encouraged ML teams to make testing a priority – and not based on classical mechanisms like F score. Machine learning applications often perform (and fail) in non-deterministic ways. “Bugs” can be unintuitive, introduced through bad data, precision mismatches, or implicit privacy violations. Upgrades also routinely touch dozens of applications, and backward compatibility isn’t available. These problems require robust testing of data distributions, expected drift, bias, adversarial tactics, and other factors yet to be codified.
—
Artificial intelligence and machine learning are only beginning to emerge from their formative stage – and the peak of the hype cycle – into a period of more practical, efficient development and operations. There is still a huge amount of work to do around the long tail and other issues, in some sense reinventing the familiar constructs of software development. It’s unlikely the economics of AI will ever quite match traditional software. But we hope this guide will help advance the conversation and spread some great advice from experienced AI builders.
Want more a16z?
Sign up to get our best articles, latest podcasts, and news on our investments emailed to you.
Thanks for signing up.
We would like to extend a HUGE thank you to everyone who responded to our last post and provided insights for this one, including (quote attributions in parentheses): Aman Naimat (*), Shubho Sengupta, Nikon Rasumov, Vitaly Gordon (**), Hassan Sawaf (), Adam Bly, Manohar Paluri, Jeet Mehta, Subash Sundaresan, Alex Holub, Evan Reiser, Zayd Enam, Evan Sparks, Mitul Tiwari, Ihab Ilyas, Kevin Guo, Chris Padwick, and Serkan Piantino.
—

