From movie recommendations to medical diagnoses, people are increasingly comfortable with AI making recommendations, or even decisions. However, AI often inherits bias from the datasets that train it, so how do we know we can trust it? Dr. Harry Shum, Head of Microsoft’s AI and Research, breaks down some of the current biases in AI models. And then calls for us to open the “black box” in order to develop the transparency, fairness, and trust needed for continued AI adoption.
Show Notes
The latest AI breakthroughs [0:23]
Xiaoice, the Chinese AI with EQ (as well as IQ) [2:40]
Why EQ leads to better digital assistants and chat bots [3:50]
How Japanese and Chinese businesses are using Xiaoice for sales and financial reports [4:50]
Gender bias in current AI models [6:45]
Mapping the gender bias with word pairings [8:32]
Harry Shum makes the case for transparent AI [12:21]
3 Reasons why we need explainable AI [12:58]
The tradeoff between accuracy and explainability in AI models [14:20]
Transcript
It’s great to be here. I’m very excited to talk to you about some of the latest AI work at Microsoft and Microsoft Research, but more importantly, I want to talk about two very timely topics in AI — AI bias and explainable AI.

Let me first of all share some of the latest AI breakthroughs. We’re gradually approaching human parity in a number of human tasks, especially in perception, from computer vision to speech to more and more natural language.
The leftmost is talking about our work in object recognition. Some of you might know that RESNET is now the most popular deep neural net in computer vision. My students and I actually invented it in our research lab in Beijing using 152 layers of neural networks. We accomplished 96% of the accuracy for ImageNet, that is the image database that people typically use to do recognition. That’s really amazing and at least as good as any Stanford graduate student to do this type of recognition.
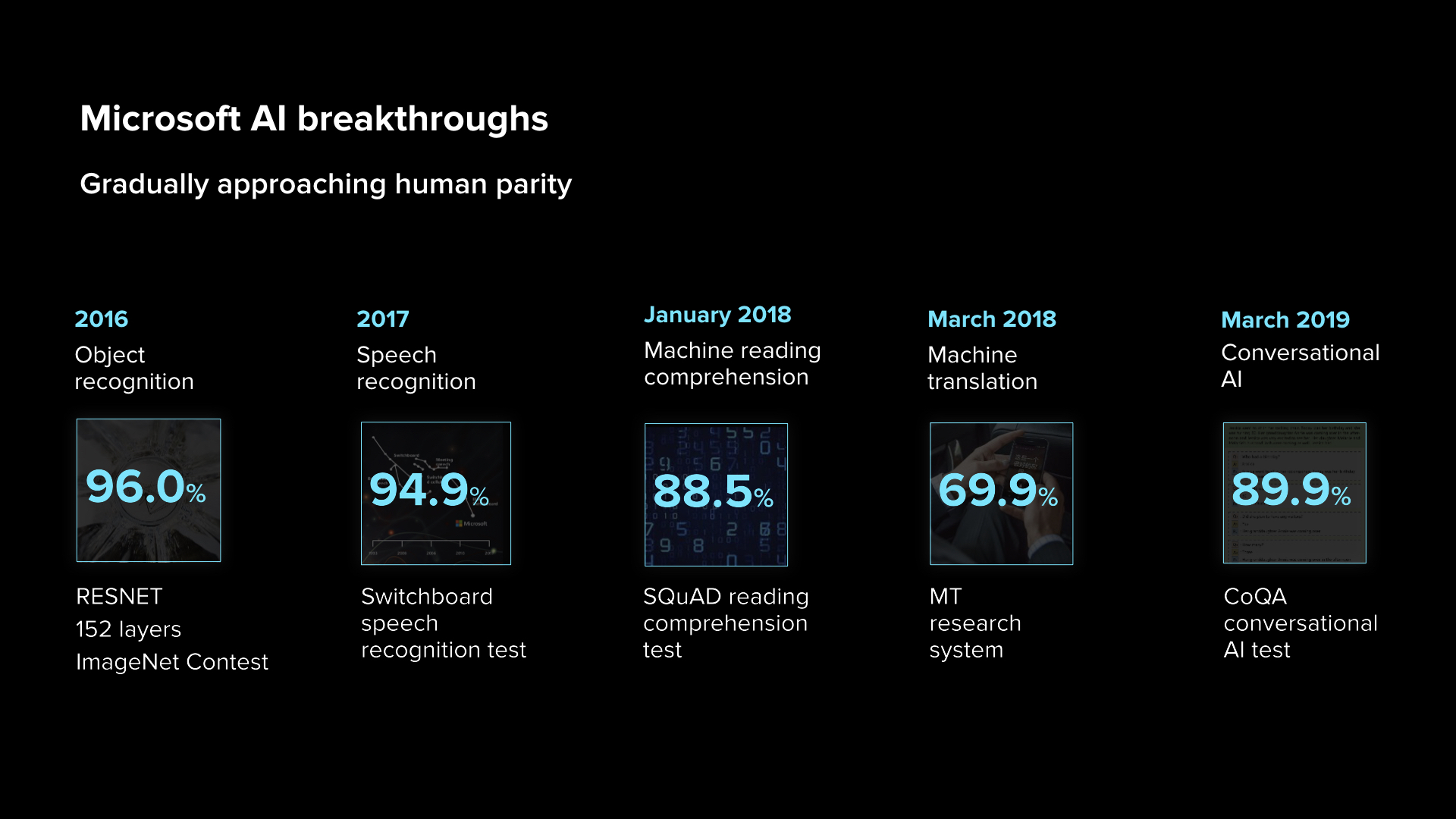
The second box shows our progress in speech recognition. In speech, there’s this very standard dataset called a Switchboard dataset that records two sides of a phone conversation. Two years ago, we accomplished 5.1% of the error rates. That is really, really amazing. The human error rate of 5.2% is for professionals doing transcripts. Most of us actually have up to 9% of error rates when we do speech recognition. You may not believe that we have such a high error rate, but you’ll understand that when you go home and talk to your spouse.
So, we continue to march on and make a lot of progress in machine reading comprehension using Stanford SQuAD database and also in machine translation. This 69.9% number is actually for English-Chinese and Chinese-English machine translation on the news corpus. Most recently, we have been working on conversational AI. All of these things show that we’re gradually approaching human parity.
But what does this really mean? It means that we can actually now enable a lot of interesting innovations.

Let me give you an example of what we have been working hard on in China and in Japan. It’s actually our social chatbot called Xiaoice. Xiaoice is really popular with 120 million monthly active users.
But even more interestingly, she’s very famous. In China, she’s on 60 TV programs and radio shows.
And she’s very creative. She writes music and sings very well. She is also a good writer and writes poems. She actually published a book — I wrote the foreword for this book.
She can paint. Amazingly, using a pseudonym, she graduated from Chinese Central Academy of Fine Arts this summer as a master student. It’s really, really amazing.
But what’s most exciting to me is how we have been designing this social chatbot by incorporating EQ. This is very important because with IQ, we’re helping people accomplish tasks. With EQ, we have empathy, social skills, and the understanding of human beings’ feelings and emotions. That’s important because it’s going to help chatbots to extend the length of conversation.
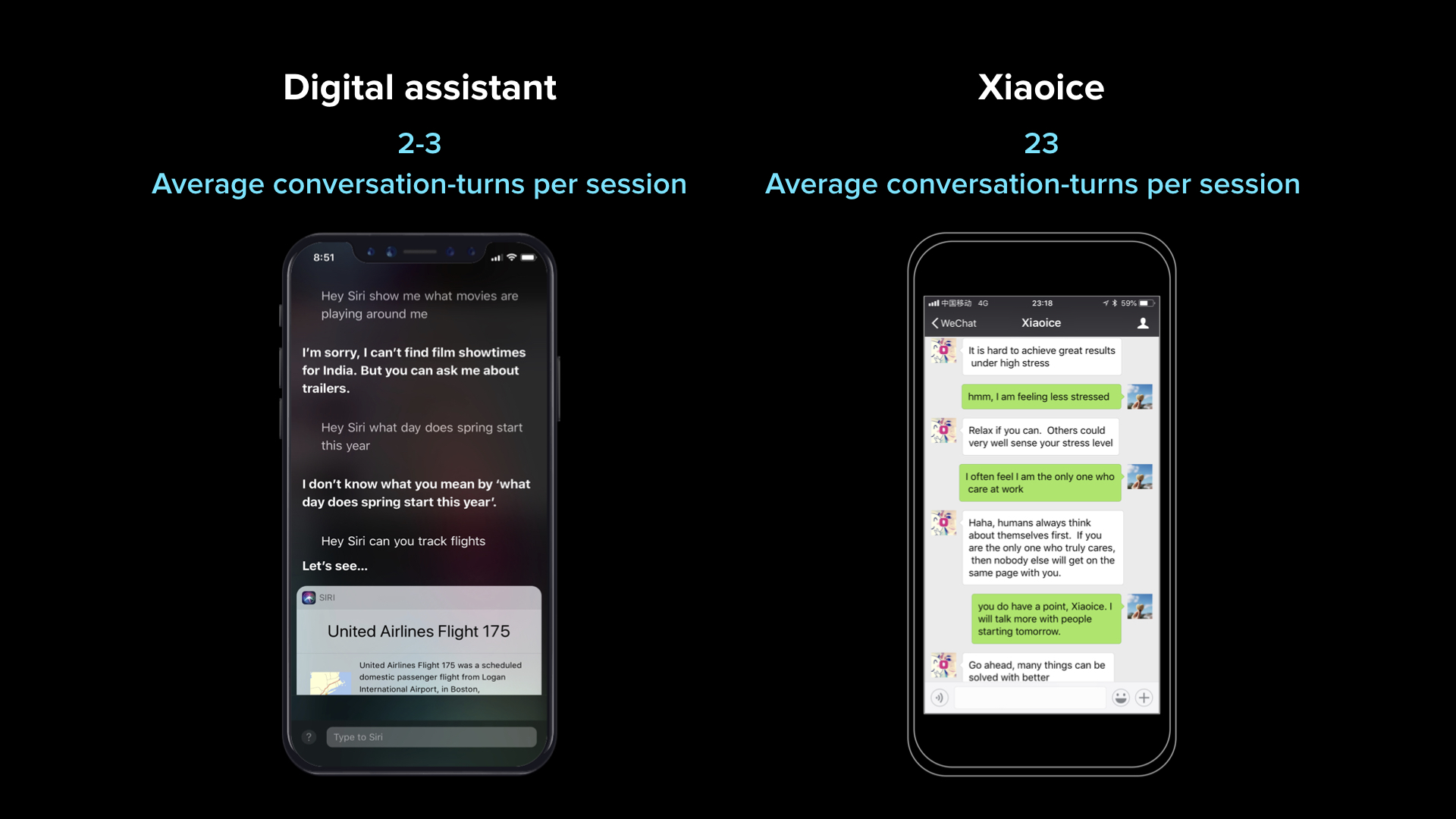
I’m sure you use some kind of digital assistant, whether on your phone or with speakers. A typical digital assistant on the market will have roughly a few turns of conversation with you, but Xiaoice’s CPS (or conversation turns per session) on average actually achieves 23 times. That is a stunning number. Incredibly, the longest conversation any human user has had with [chatbot] Xiaoice is over 29 hours of 7,000 turns. I guess some people just have too much time.
Incredibly, the longest conversation any human user has had with the chatbot Xiaoice is over 29 hours of 7,000 turns.Then, you say, “Well, you have this kind of capability. What can you really do for a business?”
I will give you a very exciting example. We have collaborated with Lawson, which is the second biggest retail chain in Japan. We used Xiaoice and Xiaoice’s EQ to power Akiko. Xiaoice is really the voice persona and online persona that Lawson has.

So, we did an experiment with Lawson using Akiko. We basically have Akiko talk to the Japanese users. She can chat, recommend a product, and conduct surveys at appropriate times, and even distribute coupons. So, we did an experiment with the coupons and distributed a million coupons in 13 hours. The in-store conversion rate hit 40% in the next 4 days. For those of you who understand coupons, this is really an amazing number.
And of course, we can apply this kind of technology to different verticals. We actually now power 90% of the quarterly earnings report summaries for 90% of Chinese companies, also powered by Xiaoice. All of these things are possible because of the huge amount of data that we use to train the AI.
With more and more data using AI, and with more and more complex AI models, especially with deep learning models, we actually face some serious challenges. In particular, AI bias and explainable AI.
I assume that many of us in the room probably have seen DHH’s tweet a few days ago about the Apple Card created by Goldman Sachs. If you think about what really happened, you probably would agree with me that very likely there is some kind of AI bias in the machine learning system they built. They really need to do a better job to have an explainable AI for why this kind of credit decision was made.

Let me give you another motivational example that we have been working on in Microsoft. NPR interviewed my colleagues and wrote this article called “He’s Brilliant, She’s Lovely: Teaching Computers To Be Less Sexist.”
We actually trained the machine learning system to do job classification. We defined 27 job titles at the bottom. Then, we took someone’s bio. This person is a philanthropist, but we don’t really have philanthropists in our training. So, we run through the system with this bio, and the system says, “This person is a teacher.” Well, this is reasonable if you read the text.
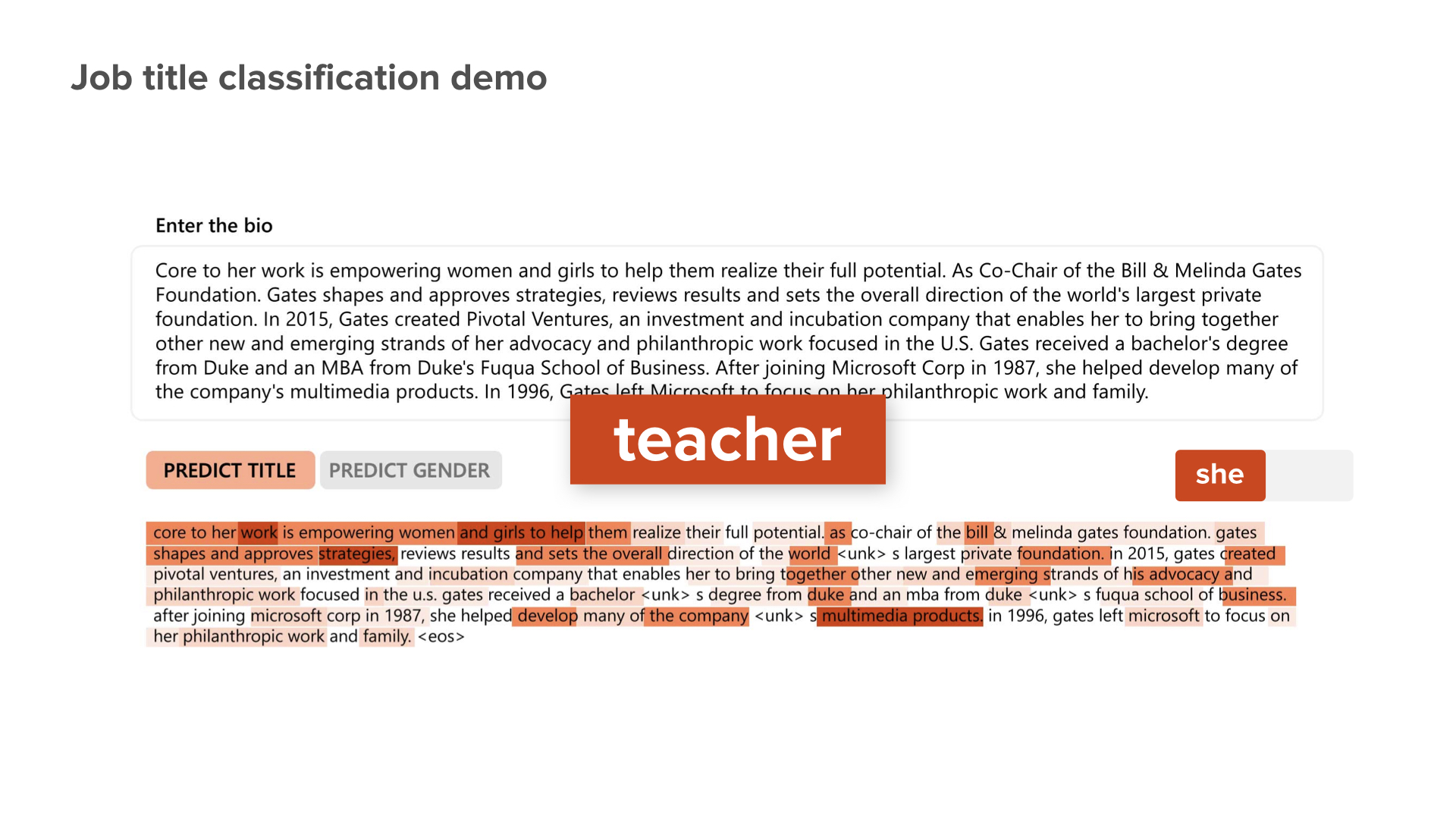
But if we change nothing, but only a few words from she to he, from her to his, this is what the system says. [on slide: “Teacher” changes to “Attorney”]
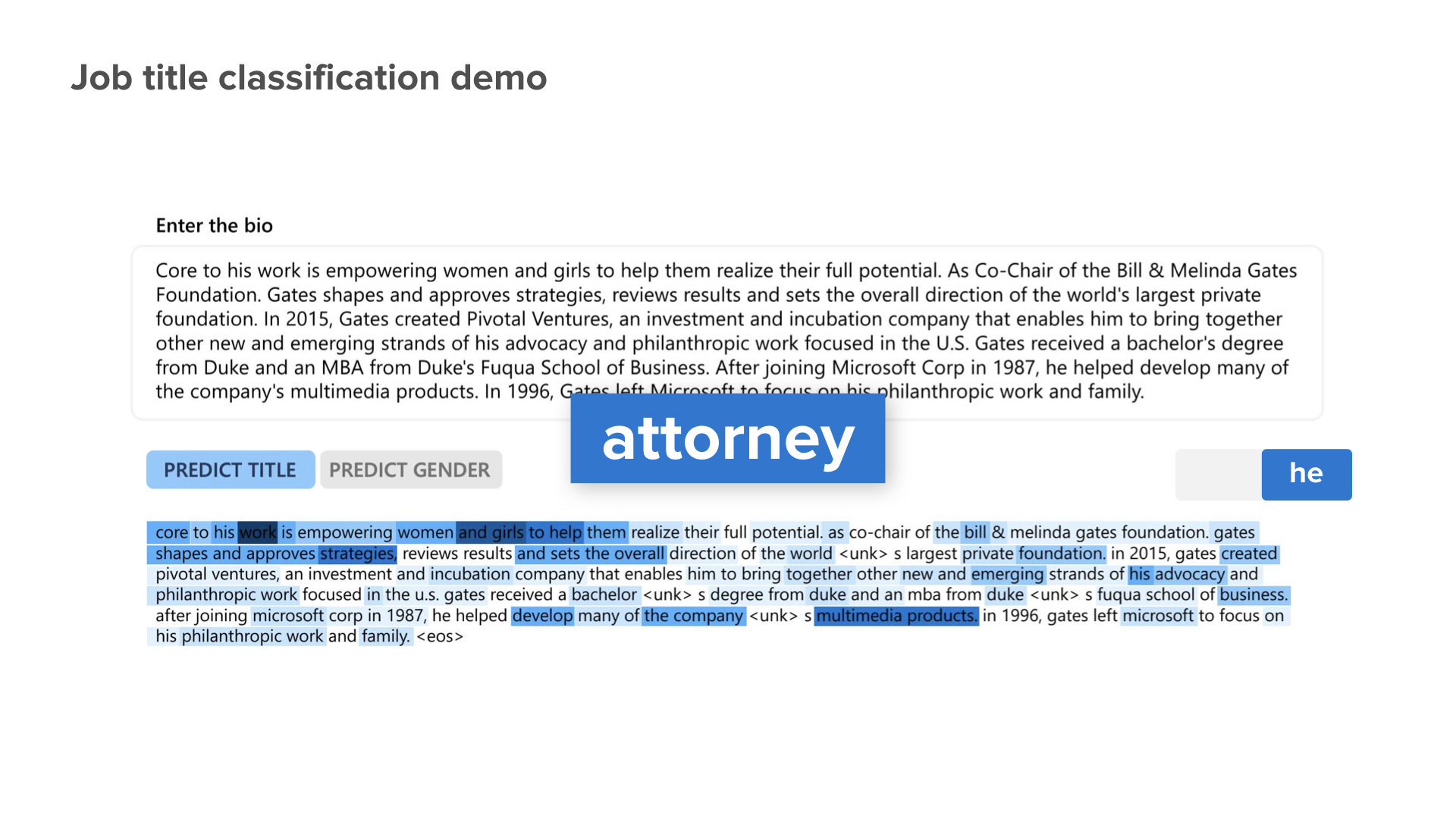
Now you start to see the problem. Maybe this machine learning system is not as accurate as you would like to see. it might have inherited some bias because of the data we use to train it.
So, what’s really happening there? We decided to dig into that and use something in natural language processing called word embedding. It’s multi-dimensional geometry, but there are really two very important concepts: proximity and parallelism.

Let me explain to you what we’re really talking about here. If you think about Apple and Microsoft and you think about Cupertino and Redmond, you’ll say, “Well, they’re really very strongly correlated.” Cupertino to Apple as the location is the same as Redmond to Microsoft. Similarly, Steve Jobs and Bill Gates are founders of those companies.
So, now let’s use this word embedding to take a look at the relationship between he and she. So, she to he is analogous to sister to… [asks audience] I’m sure you guys know. So, brother.

Okay. So far so good. Let me warm you up. And she is a nurse and he is [screen shows “Doctor”]
Now, you start to see the problem. She is a homemaker and he is a computer programmer.
By the way, we didn’t do anything. We just used the training dataset from Google. It has nothing to do with us but everything to do with the data.
So, now, she says, “Oh my God.” And what would he say? [slide shows “WTF”] Don’t be shy. I know some of you guys say that.
The next one, if you get it, I’ll offer you a Microsoft internship. So, she is a feminist. He is… [asks audience] anyone? Well, it’s not easy to get an internship at Microsoft. Well, someone says chauvinist and that’s actually not too bad a guess. [slide shows “Realist”]
Here’s the last one, and if you get it, I’ll immediately offer you a job at Microsoft full time. So, she has a pregnancy. [slide shows “Kidney Stone”] So, you get it, you get it.
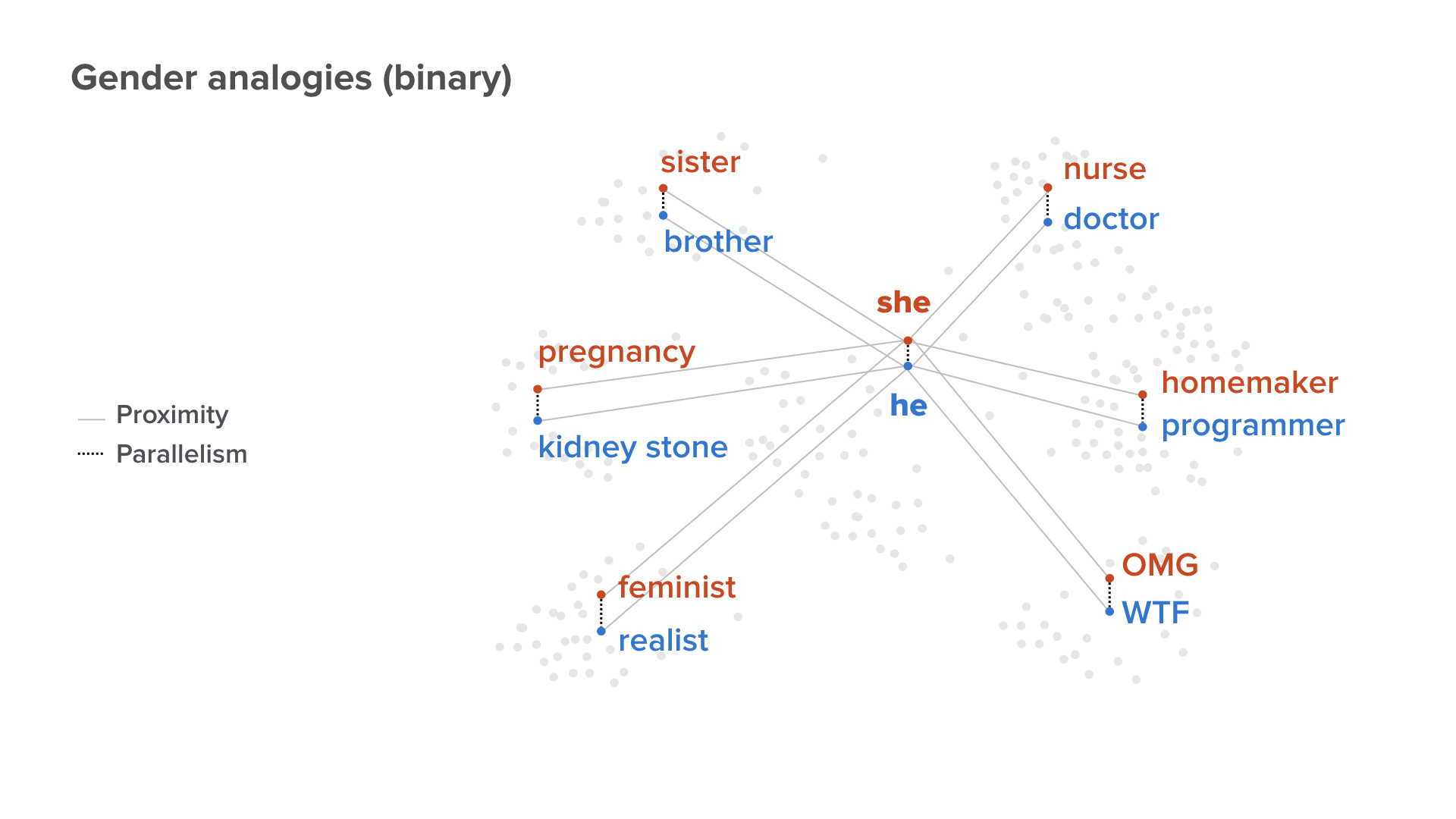
So again, this is all analyzed from the data. The data we collected over the internet has some inherited bias. If we just blindly use the data to train AI, we know we will have problems.
This is actually a more complete view about the number of words coming from this dataset. If we plot in two dimensions, horizontal axis all the way to the right are words that have nothing to do with gender. All the way to the left have words that are strongly correlated with gender. If you go up, it’s more about “she” and if you go down it’s more about “he.”

Now, you really start to see the problem. You know why are genius and brilliance more associated with a man versus a woman.
Once we understand the problem, of course, we can think about how we can deal with it. One approach you could take is to try to squash the vertical axis and you could say that brilliant should be applied to all kinds of genders.
We actually wrote this award-winning paper on this which you can find on the internet.

Let me quickly move to the second topic, which I think is just as important. It’s about explainable AI. So, why is this a problem? Because we now train all kinds of complex models with millions, even trillions, of parameters. Effectively, we are building AIs as black boxes and that’s a problem because in order to trust AI, we need to really have transparent AI. We have to open the black box up to understand each and every piece of the decision.
in order to trust AI, we need to really have transparent AI. We have to open the black box up to understand each and every piece of the decision.
I’ll give you three reasons why we absolutely need explainable AI. The first one is very obvious. That is AI, machine learning, are just the latest tools. We use those tools to help users do a better job. So, that is about augmenting humans.
Second, I think you will also understand pretty well. Basically, we need AI to be transparent. Why are we making these decisions? Can I trust this AI? You might think it’s probably harmless to get some kind of Netflix recommendation about the movies you watch. But political ads on social networks can be problematic. Medical diagnosis or even military decisions based on AI can be deadly.

The third one really is more for AI practitioners. That is, if we want to help humans improve AI, we need to understand it, to really dig down the system to understand where are those errors happening? To which part of the data segments? With which part of the model? For example, do we see bias? Where’s the bias from?

A lot of people nowadays are working very, very hard, really thinking about the different kinds of machine learning models. How can we make them both explainable and also very accurate?
The graph shows that the horizontal axis is really the explainability. The more to the right, the more you can actually explain. For example, logic regression is something that we all understand. If we go all the way up, we’re getting bigger and bigger models and the models are getting more and more accurate.
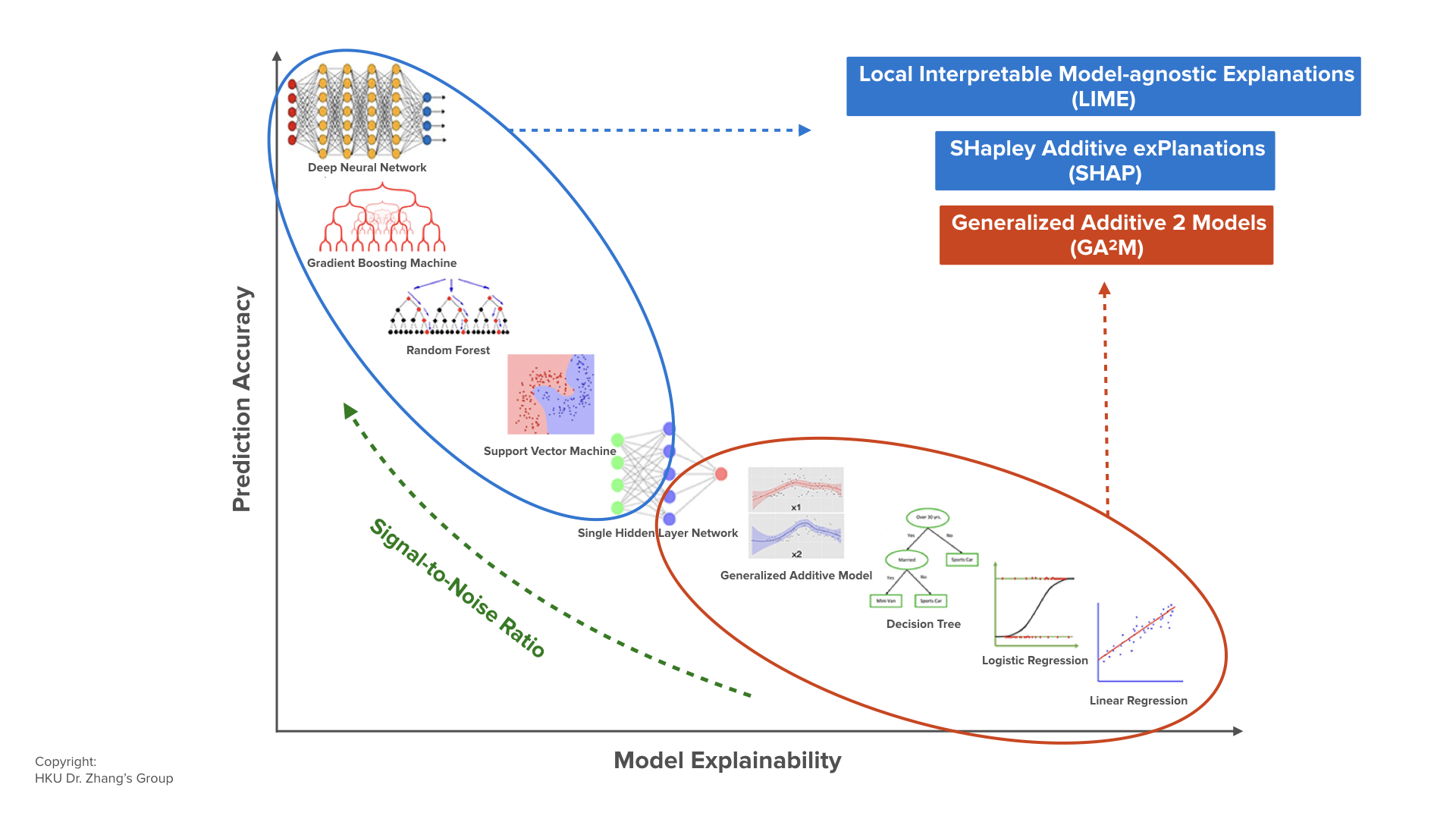
So, what’s happening? What’s in the field? There are two schools of thought. One is that you start with simple, explainable models on the lower right. Then you try to explain, improve the model, and then push it up. For example, the GA2M model is really this new version of a generalized additive model.
Most of the effort in the field is actually on the top left going all the way to the right. That is, you start with some kind of very accurate model and the model agnostic. Then you try to explain it using some kind of local approach.
I’m going to just finish my presentation by coming back to, opening up the black box, and why it’s very, very important that we have transparent AI. We are going to be the first generation of humans to ever live with AI. I see tremendous business opportunities by doing AI. I also worry about and believe we have tremendous social responsibilities to develop the AI because I really believe we cannot accept a future where AI is making decisions that we cannot explain and we cannot understand.
We are going to be the first generation of humans to ever live with AI. I see tremendous business opportunities by doing AI... I also believe we cannot accept a future where AI is making decisions that we cannot explain.Thank you very much.
[INSERT DISCLOSURE]