Transactional databases have long been the most critical component of application design. Why? Because a steadfast database is generally the ultimate enforcement point for correctness in a messy, distributed world. Without them we’d overpay and undercharge. We’d lose riders trying to get home from the airport, and we’d lose items in our shopping carts. Our online accounts would get lost, duplicated, or corrupted, and become inoperable.
In fact, the transactional database (generally called OLTP — short for online transaction processing — database) has been so central to application development that, over time, it consumed more and more application functionality. However, microservices and other modern application architectures introduced new complexities into application design: Developers needed to manage data across different services and ensure consistency between them, which forced them to build complex data synchronization and processing mechanisms in-house.
And so, as an industry, we’re seeing increasing awareness that transactional guarantees are needed outside of the traditional model. We’re seeing the emergence of systems that extend strong transactional guarantees beyond the database, into the distributed apps themselves.
We’ve been tracking these solutions over the last few years. Generally, they strive to allow for transactional management of state in a large distributed app, without creating scaling challenges and while providing a modern programming environment.
We find these solutions roughly break down into two categories. One category is workflow orchestration. This basically guarantees that a block of code will run to completion, even in the face of failure. So it can be used for the purpose of managing a distributed state machine deterministically without getting wonky. The second category is database + workflow, which extends traditional OLTP database design, allowing for the execution of arbitrary code for the same purpose.
This is still a very nascent area, and there is a lot of confusion around nomenclature, how each tool is used in practice, and who should be using them. To help get a better understanding, we asked practitioners from leading engineering organizations about their transactional stack and how they’re thinking about three key concepts for transactional workloads: application state, business logic, and business data.
Before examining these new stacks, though, here’s a quick semi-technical digression to help understand how we got here.
Transactions, guarantees, and modern apps
The very rough version is this: There are a set of tasks — transactions — that you either want to do all of, or none of. Anything in between (having it partially done) will end in a corrupt state. It’s hard to guarantee anything in a distributed system, but databases do it well with transactions. Therefore, the easiest way to handle guarantees in many systems is to just make most things transactions and let the database handle them.
Modern apps are big distributed systems with lots of users doing lots of things. So even keeping the app state consistent (like tracking where different users are in a check-out flow) turns into a distributed transaction problem. In traditional monolithic architectures, managing transactions using SQL with an OLTP database was somewhat effective. But in the new, complex world of microservices interacting through higher-level APIs (e.g., REST or gRPC), transactional needs have become distributed in nature.
However, many companies going on the journey to microservices haven’t done much to extend strong transactional guarantees beyond the database. And, in practice, that’s almost always OK. But as applications scale, inconsistencies in data grow, as does the resulting bugginess and un-reconciled errors in business data. Which, of course, can be hugely problematic. This forces application developers to deal with a wide swath of failure scenarios and conflict resolution strategies, and to ensure state consistency by coming up with their own strategies through different architectural patterns.
DefinitionsBusiness data (“data”) refers to the business-critical data traditionally stored in an OLTP database for persistence and processing (e.g. user profile info such as name, address, credit score, etc.). Application state refers to the current state of the system; the application state is determined by a value stored in a data storage system and which step the program’s execution is on in a finite state machine (e.g. the state of an order, such as “order received,” “inventory checked,” “credit checked,” “shipped,” “returned”). Business logic refers to the part of the program that deals with how the application actually works or what it does, instead of execution details (e.g. “If user_income > $100K & credit_score >650 ⇒ mortgage_approved = TRUE”). |
For the purposes of this discussion, it’s important to distinguish application state and business data. For example, knowing that a customer has entered their credit card but has not checked out is application state. The data for the credit card and the items in the application cart are the business data.
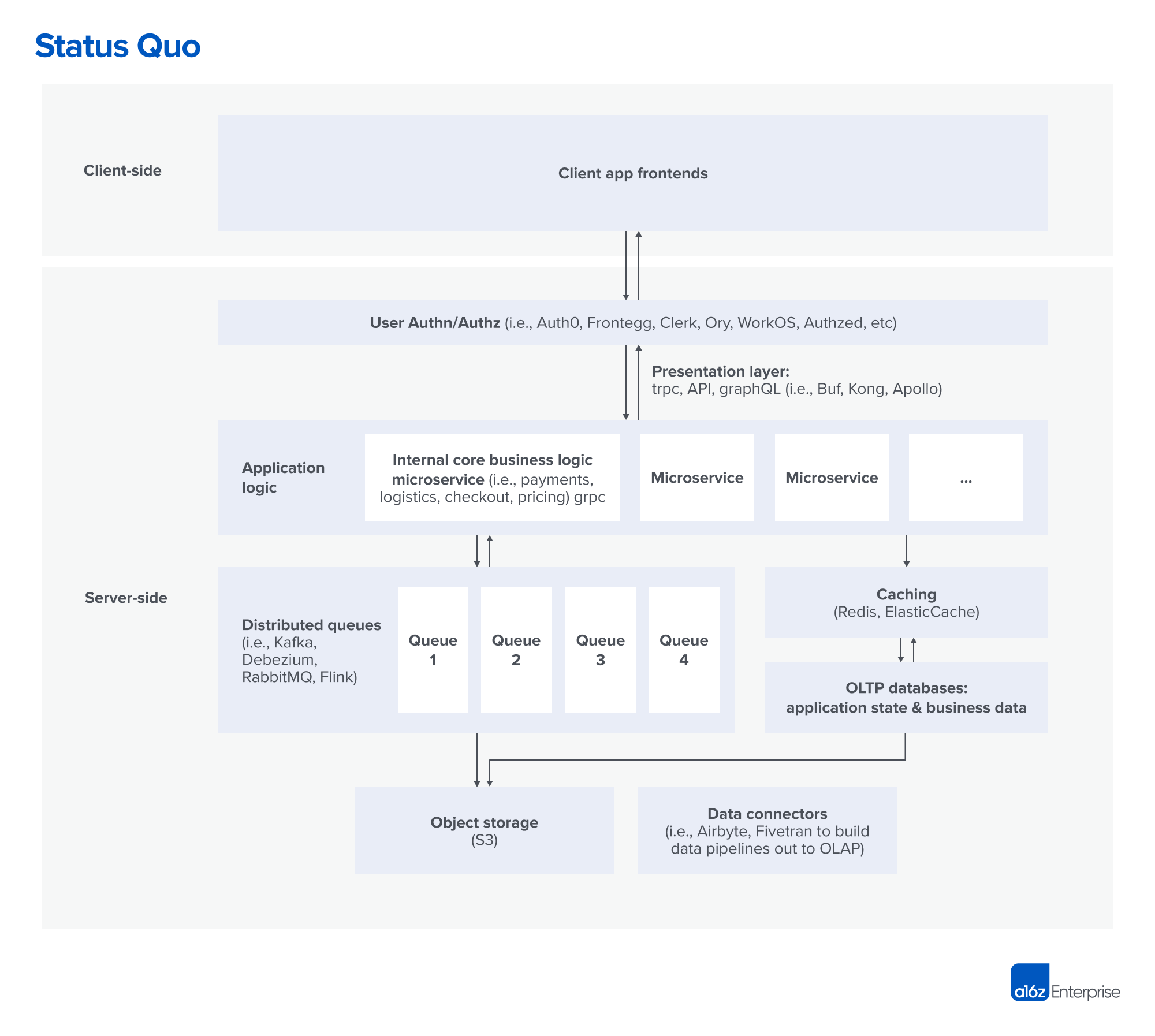
In a typical flow, a request comes from the front-end, is authenticated, and then gets routed via an API gateway or GraphQL to the relevant endpoint.
That single API endpoint now has to orchestrate tens, or hundreds, of microservices to deliver the business transaction to the end-customer. This is where developers typically lump everything into business logic blobs, and then use a combination of queues, caches, and hand-coded retry mechanisms to get the data to the database — hopefully committed as a full transaction.
As the scale of the application increases, so does the complexity of managing queues and caches, as well as the number of sharp edges in reconciliation logic when issues arise.
The rise of workflow-centric and database-centric transactional stacks
OK, so transactions are important. LAMP on a database wasn’t sufficient for scale. And a giant hairball of queues and retry logic is too brittle. To deal with this, we’ve seen, over the last few years, the emergence of new solutions that bring sanity back to transactional logic. They can be roughly categorized as either workflow-centric approaches or database-centric approaches.
To date, workflow engines work primarily on application state rather than the business data, and often require some complexity when integrating with traditional databases. Database-centric approaches add application logic alongside business data, but don’t yet have the same code- execution sophistication of workflow engines.
The diagram below provides a rough sketch of how workflow- and/or database-centric approaches are used in a Javascript/Typescript application, assuming both are in use. While they’re distinct pieces of this architecture today, we have seen early signs of a trend where databases are incorporating workflow features and workflows are starting to adopt durable storage. This merging of capabilities indicates that the lines between the two approaches are blurring and becoming less distinct in modern architectures.
![]()
Workflow-centric approaches in detail
A workflow is simply blocks of code that execute based on events, or timers, that evolve the application state machine. Transactional workflow ensures code execution with strong guarantees, preventing partial or unintended states in the application. Developers write the logic, and the workflow engine handles transactions, mutations, and idempotency. Different workflow engines make different trade-offs in terms of how much of the transaction details are exposed to the developers.
As an example, below is a visual representation of a check-out workflow running on Orkes (Conductor):
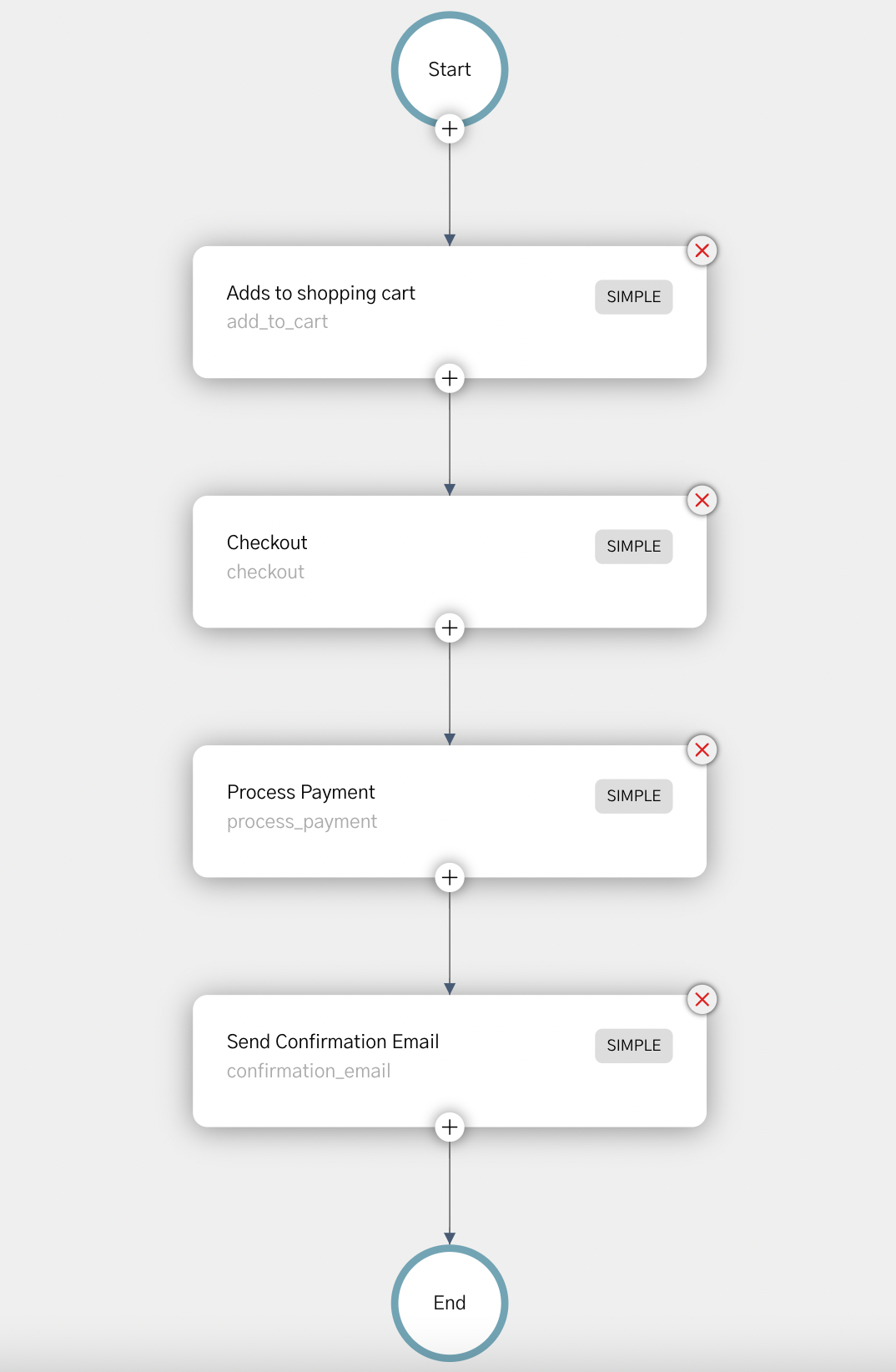
There are two rough approaches by which workflow engines gain traction. In one (typified by Temporal.io), developers write code using standard back-end programming languages (e.g., Go or Java) and the system will ensure the code runs to completion, even during a failure. In this model, the program-call stack is maintained even if the code is waiting for a blocking call to complete (e.g., read or write). To do this, the language runtime is modified to prevent partial code execution during failures. The upside to this approach is that developers can write in familiar languages and debug easily with a maintained call stack. We see this approach most popular with back-end teams dealing with large, sophisticated apps.
The downside is that it often requires a lot of integration work and wrapper code to expose useful and safe interfaces to application developers. Another downside is that it relies on a custom execution layer rather than the bare language, and there are edge cases where the execution will differ from the native language runtime. So, while developers can use languages they are familiar with, they still need to understand how the underlying system works.
The other approach, which is more popular with application developers (particularly Typescript/Javascript) is for the workflow engine to serve as an orchestrator of async functions (e.g., Inngest, Defer, and Trigger). In this model, third-party events or functions are directed to the workflow engine, which will then dispatch logic registered by the application programmers, who must give control back once the need to block on another async function arises. The upside is that this is a far more lightweight method of integrating into a program. It also forces enough structure on the code that the team working on it can understand it more easily. However, this approach can be more difficult to debug without tooling support, so debugging tends to be platform-specific.
Workflow engines are particularly powerful in that they allow for gradual adoption by existing apps. They can be applied on a piecemeal basis to certain workflows with minimal footprint. That said, the two biggest shortcomings of workflow engines stem from the fact that they don’t extend into the database. As a result, there isn’t a single, queryable source of truth across application state and business data. Also, the transactional semantics are generally different from the database semantics, requiring application developers to handle edge conditions.
Although not the norm today, we want to illustrate the conceptual architectures of how workflows can in many cases be used as persistent data stores:


Database-centric approaches in detail
Database-centric approaches start with a database, but extend it to support arbitrary code execution to allow for workflows alongside data management. They do this by giving control to the programmers so they can make explicit decisions on mutations, transactions, and idempotency for regular code blocks — essentially by exposing OLTP semantics directly. The programmer is responsible for keeping business logic and business data separate from application state.
Indeed, the pure database view is that application state can always be derived from business data. This is usually done by storing application state as a set of transactions that modify business data in the database. It’s easiest to think of this as a database that can execute blocks of code with the same strong guarantees as the workflow systems described above.
Internally, we call this the application logic transactional platform (ALTP) approach because, ultimately, it extends OLTP transactions into the application. But what really characterizes ALTP is that, for greenfield apps, it can entirely obviate the need for the app developers to directly manage back-end infrastructure.
From the ALTP lens, the most commonly used approach started with Firebase, which offers a full-service “back-end experience,” including auth, data store, databases, and more. Firebase and more recent entrants, like Supabase, remain very popular platforms for greenfield projects. And while they tend to stay faithful to their OLTP roots — and so don’t support arbitrary code execution for transactional back-end functions — Supabase is already starting to add support for workflows.
However, next-generation ALTP offerings like Convex do allow the execution of arbitrary code as a transaction alongside the database. These offerings allow for writing fully transactionally compliant code in a normal language (e.g., Javascript/Typescript), where a single block of code can read, write, and mutate data — both application state and business data. In a sense, it gives developers a single queryable source of truth, and provides workflow primitives like subscriptions.
ALTP solves the problem workflow engines have in being decoupled from the database, but, as a result, require the users to rely on their database offering rather than a standard OLTP in order to get the benefits. As a result, we primarily see teams adopt ALTP for greenfield apps, rather than integrating it into existing, complex backends.
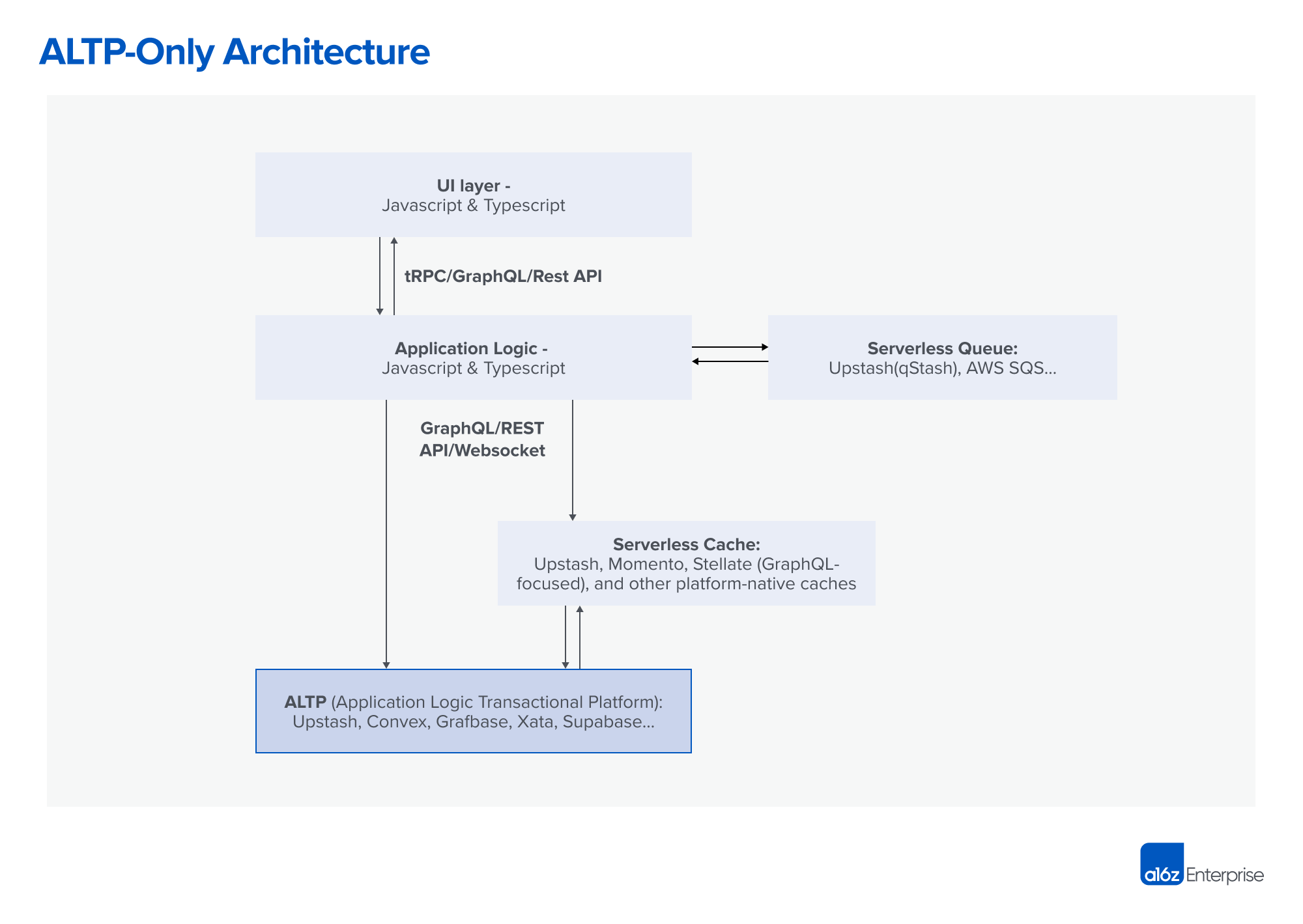
The diagram above is an amalgam of the many operators we spoke with. Some will just use a workflow engine. Some will just use a database-centric approach. But many will use both — especially when they are just starting to adopt workflows. Users of workflow engines today tend to be back-end teams dealing with large, complex applications, although we have also seen many full-stack teams adopting them. Back-end-as-a-service solutions tend to be more application-developer-friendly and are more commonly used when the app drives technology selection.
The convergence
It’s becoming clear that workflow-centric approaches and database-centric approaches are on a collision course. The primary reason for this is that while application state and database state are logically distinct, they are dependent on each other, and a system that doesn’t cover both is complex to get right and to debug.
As an example, consider a workflow engine being used to track the state machine for a user’s checkout process, and that user is adding an item to a cart. Typically, workflow engines ensure that a code step will run even in the event of a failure. However, there may be instances where the engine needs to rerun a given step during a failure because it’s not entirely sure whether the step was fully completed. If that step involves writing business data to a traditional database (in this case, the item in the cart) and the database isn’t aware of the duplicate retry, it’ll end up with a duplicate entry.
There are two ways to deal with this. One way is to push the problem to the application developer, which will use a nonce provided by the workflow system to ensure only one item is written. But that assumes the developer understands idempotency, which is notoriously tricky to get right, and this obviates a lot of the magic of having a workflow system. The other way is to tie the workflow engine to a database that is aware of the workflow transactional semantics. This hasn’t quite happened yet, but it’s not hard to believe it will.
On the other hand, database-centric approaches realize that general workflow is really useful to application developers. And so we’re starting to see databases (like Convex) — which support traditional database functions like queries, mutations, indexes, etc. — implement functionality like scheduling and subscriptions. These allow them to be used as workflow engines. That is, they allow the execution of arbitrary code blocks with strong guarantees.
As Ian Livingstone (who provided feedback on this piece) put it, “It’s the classic ‘Do you bring the application logic to the database, or the database to the application logic?’ playing out again … this time brought on by breaking up the monolith.” Having had that dichotomy for decades, it’s clear both models will persist in the short term. It’s far less clear that’ll remain the case in the long run.
Special thanks to Charly Poly (Defer), Dan Farrelly (Inngest), David Khourshid (Stately), Ian Livingstone (Cape Security), Enes Akar (Upstash), James Cowling (Convex), Jamie Turner (Convex), Paul Copplestone (Supabase), Sam Lambert (PlanetScale), Tony Holdstock-Brown (Inngest), Matt Aitken (Trigger) for reviewing this post and giving feedback. Additionally, thanks to Benjamin Hindman (Reboot), Fredrik Björk (Grafbase), Glauber Costa (Chiselstrike), Guillaume Salles (Liveblocks), Maxim Fateev (Temporal), Steven Fabre (Liveblocks), and Viren Baraiya (Orkes) for helping us with the research.
* * *


