In our popular post on emerging data infrastructure, we highlighted technologies that have led to a new wave of data-stack investments. These stacks represent the culmination of a number of trends in the industry, including the migration from on-prem to cloud; the maturity of new data lake technologies that span both analytical and transactional workloads; and the transition from cumbersome ETL pipelines to the smoother ELT process. In that same post, we predicted the rise of a new class of data applications and products built atop these emerging technologies.
Today, we are observing this shift take off in earnest. It’s especially prevalent among the categories of data applications that aim to solve unique challenges in the marketing sphere: business processes centered around customer experience and satisfaction; marketing practices becoming more personalized and integrated; and high consumer expectations on the timeliness of each engagement.
In this post, we explore one prominent example of this trend: the customer data platform (CDP).
What is a CDP?
In many ways, the massive growth of investments in customer experience (CX) systems parallels that of data infrastructure, and represents investments being made directly by the customer-facing teams – marketing, sales, and support. Teams in these customer-facing groups, separate from IT, have been building technology infrastructure to support the fast-changing landscape and respond to real world events. The data layer that supports the operational complexity is often a CDP.
Historically, CDPs are magic wands mostly waved by the marketing specialists at large organizations in the name of customer segmentation and identity resolution for more accurate ads. They wanted better targeting and online engagements.
Today, the promise of the CDP is to unify, analyze, and activate customer data, and to break down traditional data, technology, and channel silos within an organization. The platform that was predominantly adopted by marketing teams for targeting and engaging with audiences is now expanded to the entire customer journey, from first touch to post sales. Rather than teams having to manage dozens of data silos that exist in each of their martech applications, CRM, or primary user data stores, the CDP can unify that data, help teams slice and dice audiences, enrich customer profiles, and paint an overall customer profile for the business team to act upon.
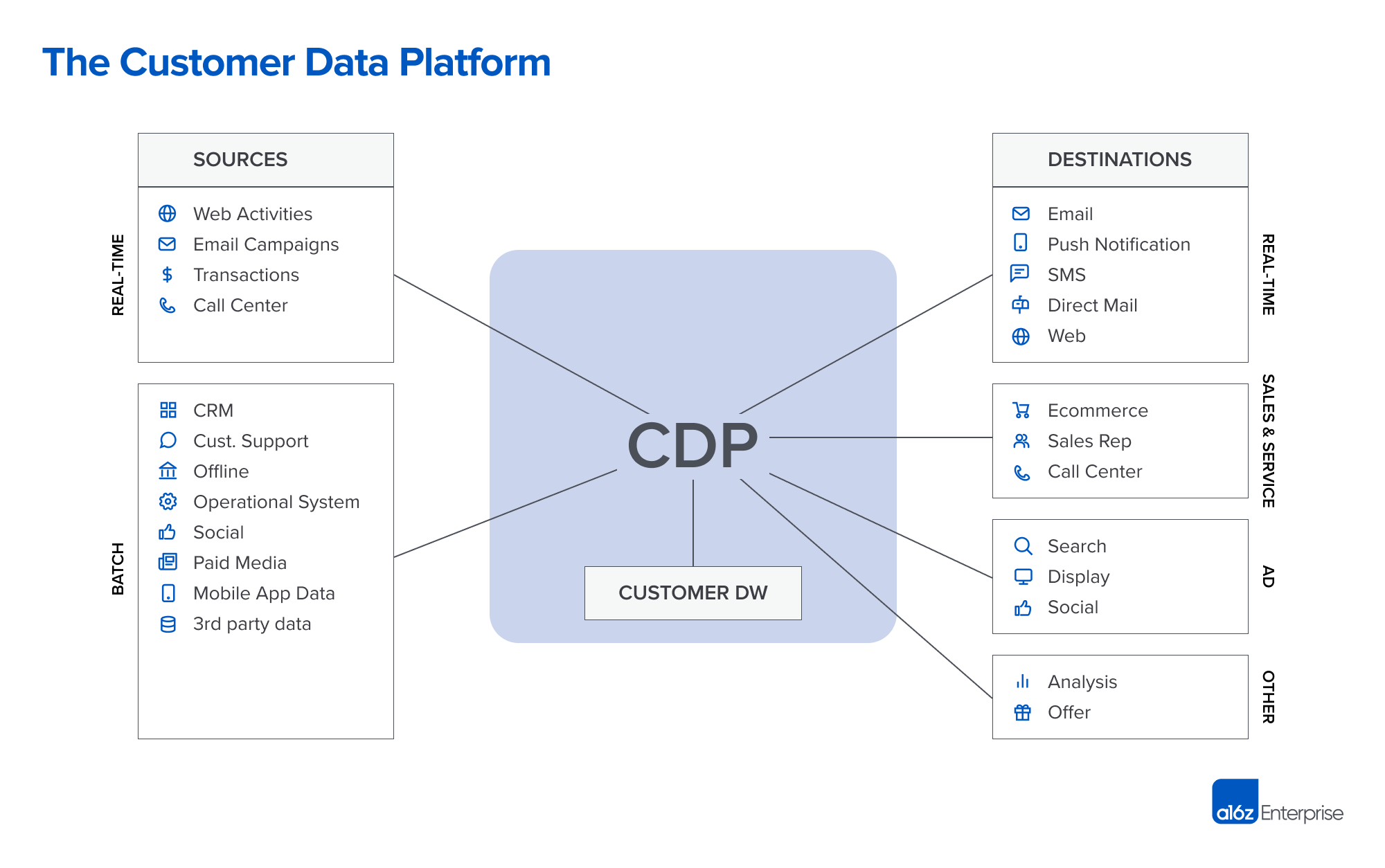
Like most analytical application providers, traditional CDP players are early adopters of concepts such as cloud data warehouses and data lakes, but in a “bundled” offering. The aggregated customer data becomes another form of a data silo that lives outside of the cloud data warehouse, which more and more is treated as the ground truth.
The result is that, in the shifts toward a more accessible and self-served modern data stack, marketing and data leaders are faced with a dilemma: Where should we consolidate the customer data, the CDP or the data warehouse? And, more importantly, where does that leave business users who need access to customer data in a fast but trustworthy manner?
Adapting CDP to a warehouse-first paradigm
The ideal solution to the prior problem is to leverage the general-purpose data infrastructure for the backend, and let business teams use existing functionalities that are offered by the CDP. That way, organizations can minimize switching and infrastructure costs while continuing to benefit the from many of the emerging capabilities offered by the modern data stack:
- Serverless architecture (BigQuery, Redshift Serverless, Databricks Serverless SQL): Developments are accelerated with the use of serverless options that allow users to deploy code without having to manage the infrastructure required to execute it. This enables faster implementation times for common tasks like data collection and complex transformation, all the way to turnkey automation built for customer engagement.
- Native data sharing (Databricks, Snowflake): Complex and costly data pipelines operations with flat files in the middle are no longer required. Data sharing capabilities provided by data clouds offers a controlled and simplified approach to making data accessible by consumers.
- Federated queries (Starburst, BigQuery Omni): Fragmentation of cloud technology adoption increased the need to be able to query data not in just one cloud, but across multiple clouds. New architectural patterns such as data fabrics and data meshes are embracing the “more than one place” requirement.
- Query push-down (Databricks, Snowflake): With customer data being centralized in data clouds, queries can be generated by the business application and pushed down to execute in the respective data warehouse. The scalable infrastructure and advanced data governance control reduces the headache of rising infrastructure cost and removes the data residency concerns.
Composable CDPs are taking advantage of this shift in data infrastructure toward the data cloud and embracing a “warehouse-first” architecture. The goal is to minimize or eliminate data replication and to deploy best-of-breed solutions from different technology providers. The characteristics of a composable CDP are:
- Zero copy: An architecture where no data is persisted outside of the client’s data warehouse. This zero copy guarantee must extend to all downstream processing and be enforceable by client-owned security and access controls.
- Data warehouse/lake agnostic: The customer data activation layer data can access data across different warehouse technologies. This helps avoid data-store-vendor lock-in, and helps future-proof for a heterogeneous data stack with different infrastructure vendors supporting different workloads (e.g., analytics, ML, real-time).
- No-code interface: Business users are key adopters and users of CDPs. The platform translates business requirements through a no-code UI into code and SQL that is pushed down into the data warehouse. This decouples the dependencies between business stakeholders and the data team, so each can independently move fast.
- Define once, use everywhere: By building atop data infrastructure tooling like dbt, composable CDP can reuse metrics defined for the broader organization in the marketing context and enable better collaboration with the central data team, making running campaigns and experiments more streamlined.
Emerging architecture for modern CDPs
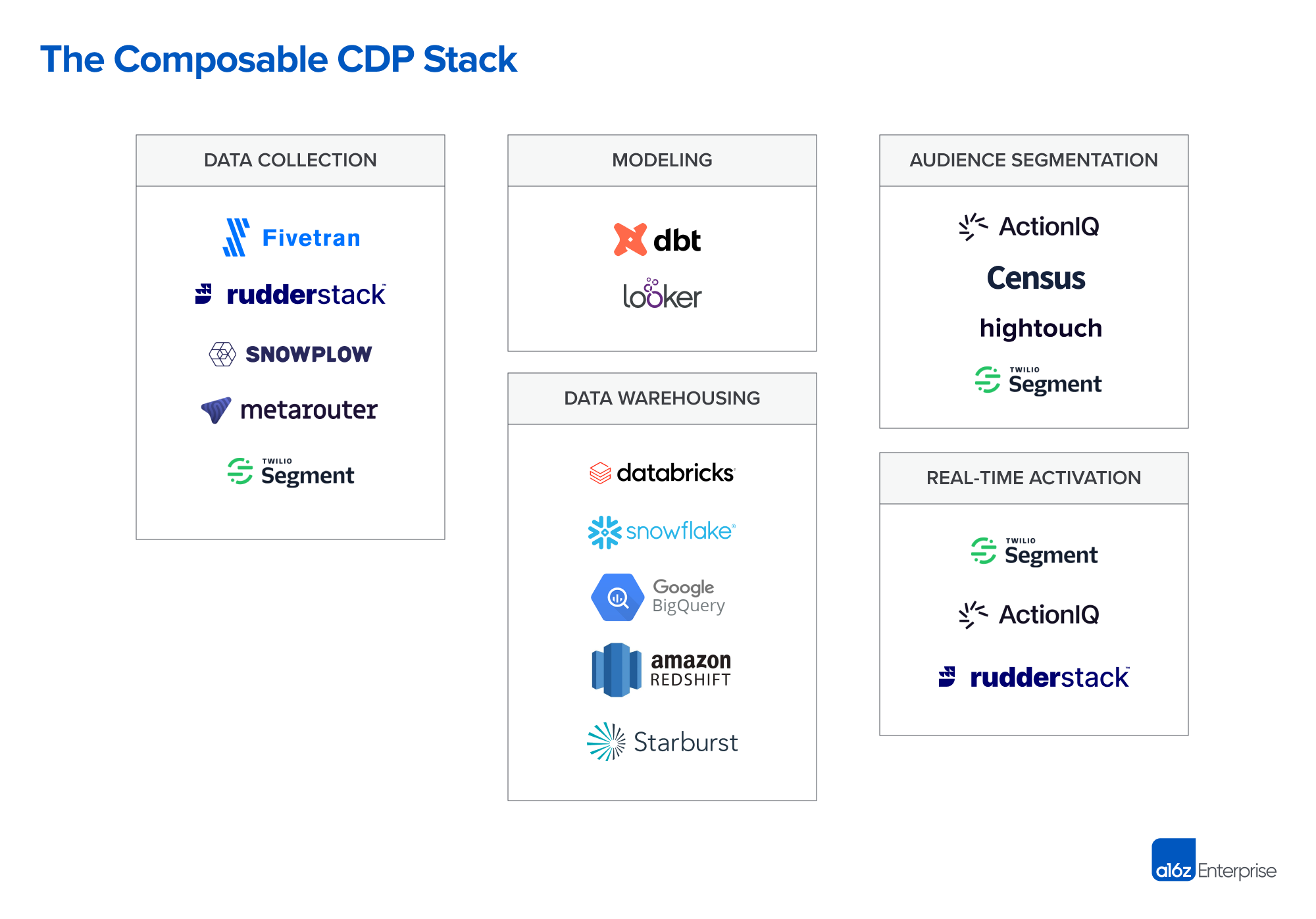
Built on the foundation of the modern data stack, the new CDP architecture is a lot more modular and adaptive to enterprises needs. Upon streamlining and consolidating several core data infrastructure blocks, each component is focused on what they are best at and serves a particular group or audience. Let’s dive into these core capabilities.
Customer data infrastructure for data collection
Data is the foundation of a CDP. Depending on the source of data, collection can happen in several ways:
- For first-party data, traditional CDPs deploy a proprietary tag or SDK to collect digital behavioral data (e.g., clicks, page views, etc.) in real-time. Today, tools like Snowplow or Segment allow you to embed the collector once and use it multiple times to funnel the customer data into data warehouses or trigger event driven workflows.
- For third-party data, such as CRM or payments data, products that specialize in ELT pipelines with built-in integrations across a wide range of SaaS platforms have emerged as the clear best-of-breed option.
Key capabilities include:
- Real-time digital data collection via SDK
- Real-time data transformation
- Built in governance
- ELT pipelines for batch or mini-batch data
Customer data infrastructure for data modeling and identity resolution
Once the data has been ingested, it’s crucial to clean and model data correctly to reduce noise for the consequent steps. BI or transformation tools like dbt offer the possibility for data analysts to prepare customer tables in the underlying data warehouses that can be shared by multiple teams. The other benefit of having a shared modeling layer is that it’s relatively easy to uniquely identify each customer and resolve duplicate entities. It also provides a more economical solution for enrichment when there’s one master customer table.
Key capabilities include:
- Deterministic identity stitching and probabilistic identity resolution
- SQL-based data transformation pipelines
- Real-time read and write to the mastered entity table
- Configurable and automated data cleansing
- Enrichment with third party data sources
Customer data storage
The storage and compute layer acts as the source of truth for the raw customer data, as well as the compute resources necessary to query it. This is the biggest differentiation between a composable CDP and the earlier traditional bundled architectures: In a composable CDP stack, this layer is more than likely provided by cloud data warehouse that’s owned and managed by the organization doing the querying, rather than by a CDP vendor.
While SQL-based analytics workloads remain the most prominent for the current workloads, it’s likely that more clients will embrace machine-learning-powered recommendations and personalization around customer experiences. In that case, infrastructure that is purpose-built for these workloads will need to be integrated into a heterogeneous infrastructure stack, a trend we see captured in the rise of the lakehouse architecture.
Key capabilities include:
- Storage layer for storage of large scale customer datasets
- SQL interface with analytic query capabilities
- ML modeling and model hosting
- Real-time analytics
Customer data activation for audiencing
The activation layer is where non-technical business teams (i.e., marketing, sales, service, support, etc.) access this unified and modeled customer data. Either an interface is provided for the domain expert to easily construct audiences and derive insights (e.g., ActionIQ), or the data is transferred back through reverse ETL to an end-user application such as Hubspot, Marketo, or Braze to perform the next set of actions.
One challenge to note is that many real-time use cases, such as loyalty-based discounts, require quick actions triggered by a customer event. The whole process happens in seconds before the data hits storage. Reverse ETL solutions (e.g., Census) today are still largely batch processes. This is where traditional CDPs are much better suited to cover a variety of use cases.
Key capabilities include:
- Out-of-the-box modeling
- Batch and real-time data segmentation
- Governance and access controls of data
What’s next
As the core pieces of data infrastructure continue to mature, consolidation is happening on the backends toward data warehouses and event-driven architectures. These compostable and adaptive backends enable a new wave of interaction on top of shared data models, which makes the collection, analysis, and dissection of customer data much more tenable and shareable across different teams. More importantly, the same architectural shift enables the automation and engagement layer, from transactional notifications to custom workflows, to be more modular and programmable.
All of which will lead to a delightful and personalized consumer experience!
* * *
The views expressed here are those of the individual AH Capital Management, L.L.C. (“a16z”) personnel quoted and are not the views of a16z or its affiliates. Certain information contained in here has been obtained from third-party sources, including from portfolio companies of funds managed by a16z. While taken from sources believed to be reliable, a16z has not independently verified such information and makes no representations about the enduring accuracy of the information or its appropriateness for a given situation. In addition, this content may include third-party advertisements; a16z has not reviewed such advertisements and does not endorse any advertising content contained therein.
This content is provided for informational purposes only, and should not be relied upon as legal, business, investment, or tax advice. You should consult your own advisers as to those matters. References to any securities or digital assets are for illustrative purposes only, and do not constitute an investment recommendation or offer to provide investment advisory services. Furthermore, this content is not directed at nor intended for use by any investors or prospective investors, and may not under any circumstances be relied upon when making a decision to invest in any fund managed by a16z. (An offering to invest in an a16z fund will be made only by the private placement memorandum, subscription agreement, and other relevant documentation of any such fund and should be read in their entirety.) Any investments or portfolio companies mentioned, referred to, or described are not representative of all investments in vehicles managed by a16z, and there can be no assurance that the investments will be profitable or that other investments made in the future will have similar characteristics or results. A list of investments made by funds managed by Andreessen Horowitz (excluding investments for which the issuer has not provided permission for a16z to disclose publicly as well as unannounced investments in publicly traded digital assets) is available at https://a16z.com/investments/.
Charts and graphs provided within are for informational purposes solely and should not be relied upon when making any investment decision. Past performance is not indicative of future results. The content speaks only as of the date indicated. Any projections, estimates, forecasts, targets, prospects, and/or opinions expressed in these materials are subject to change without notice and may differ or be contrary to opinions expressed by others. Please see https://a16z.com/disclosures for additional important information.


