In the expansive world of software, I have a particular fondness and passion for the arcane yet critically important area of system software. For my entire career, whether as a programmer, kernel hack, or CEO, I have been involved with building companies and selling system software.
Generally speaking, system software is the entire operating system and related services that directly interface with the operating system. Software for networking, storage, compute, and (sometimes) security are examples of system software. You might think of system software as the plumbing of computing — and to extend the analogy, applications are the fixtures we all see and use. Not to put too fine a point on it, but without the plumbing, shit would be everywhere!
Innovations in system software tend to follow broad trajectories, given the dependence on hardware innovation and adoption of compute architectures in organizations. One of the most fundamental building blocks in system software is a piece of software called a file system, which is essentially a “file cabinet” of data. Without a file system, modern computers would not operate. At some point, all I/O and most data on a computer finds its way into a file system — making it one of the most indispensable system software components.
In 1990, I joined a company called Veritas Software that pioneered a new file system. The file system was so innovative for its time that it became the de-facto standard in nearly all datacenters. Of course, no one believed that building and selling a file system would amount to much. Boy were they wrong! The broad adoption of the Veritas File System (affectionately called VxFS) enabled Veritas to become a multi-billion-dollar revenue company.
In the years since VxFS, however, there have been only incremental file system developments. File systems have always been designed for a disk-drive-centric storage environment, so today’s disk-based computing systems are well tuned and perfected. Little new innovation is needed. It’s a fundamental paradigm that has existed since the beginning of computing.
But the world is changing. As we confront unprecedented amounts of data, much of it in real-time, there is a shift from disk-centric to memory-centric computing. This shift requires a complete re-think in file — and storage — system design.
Memory-centric computing assumes that large working sets of data live in system memory (or RAM) as opposed to disk drives or solid-state disks (SSDs). We can reliably predict, with the cost of system memory decreasing, that memory for both storage and compute will be the exact same thing. Until now, we have always had tiered memory (RAM, disk drives, tape), which served to trade off cost and performance, and led to an entire computing architecture that has persisted for the past 40 years. Memory-centric computing will flatten this memory hierarchy and completely up-end compute architectures. It’s a revolutionary concept, one that has never existed before… and we are finally close to achieving this milestone.
This shift to memory-centric computing requires an entirely new file and storage system. And that’s where Tachyon comes in to play.
Tachyon is a memory-centric, fault-tolerant, distributed storage system, which enables reliable data sharing at memory-speed across a datacenter. Tachyon already supports many applications, with more to come, but will be especially valuable for big data applications. Think of Tachyon as the pioneer of next-generation file and storage systems, much like VERITAS was in the 1990s with VxFS.
So I am pleased to announce our investment in the company created by Haoyuan Li (“HY”), the co-inventor and lead of Tachyon and a Berkeley Ph.D. candidate (advised by top computer scientists Ion Stoica and Scott Shenker). HY drove the open source development of Tachyon at the U.C. Berkeley AMPLab, the birthplace of other industry-defining technologies such as Spark and Mesos.
HY’s insight and expertise — amplified by the incredible community working on the project — is bringing the next generation storage system to market. In less than two years, its industry traction is nothing short of phenomenal:
— Tachyon has more than 70 contributors from over 30 companies.
— Tachyon is deployed at more than 50 companies, some of which have deployed Tachyon with more than 100 nodes in production.
— It is the fastest-growing project in AMPLab history. Data also shows it is the fastest-growing project in the big data ecosystem.
One reason the IT community is going nuts over Tachyon is its ability to scale and perform with enterprise-class reliability. See for example this chart comparing Tachyon with today’s de-facto big data file system, HDFS:
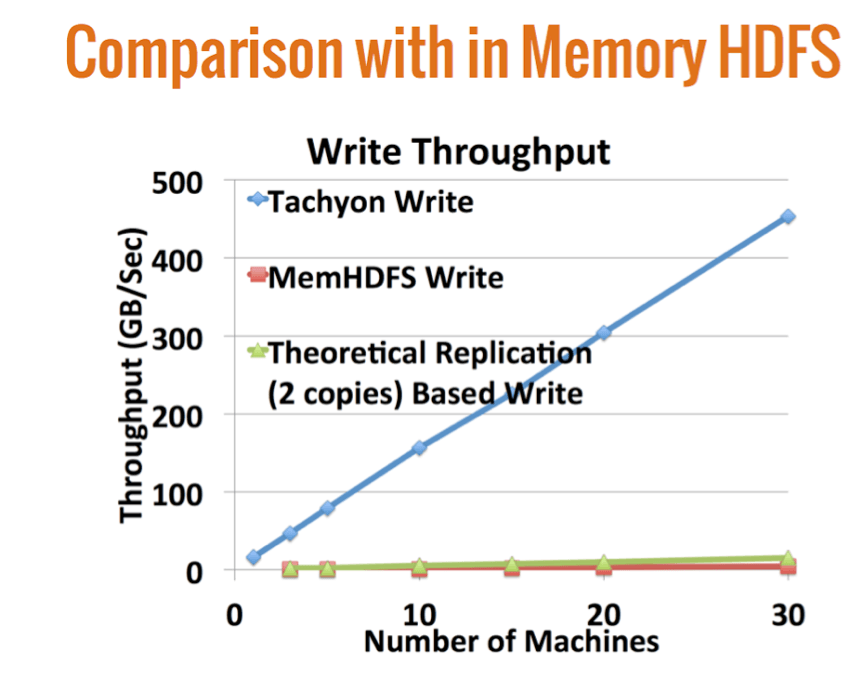
As you can see, Tachyon linearly scales and blows HDFS away (even with HDFS running entirely in memory). Think of what this +100X performance boost will do for big data applications!
But that’s not all. As a general-purpose file system, Tachyon’s architecture supports data in traditional storage formats (e.g. HDFS, NFS) and modern workloads to power big data analytics.
Tachyon’s memory-centric architecture represents the future of storage. In fact, it’s the first new file system that was built from the ground up to take advantage of memory-centric compute architectures. With Tachyon as the “memory-centric” storage layer, our investments (including Databricks and Mesosphere) in the memory-centric infrastructure out of the “badass” Berkeley Data Analytics Stack (BDAS) — from big data storage to compute — is complete.
I am thrilled to be joining the board of HY’s company, currently dubbed Tachyon Nexus, based on the open source project Tachyon. We look forward to seeing this company become the next great software franchise delivering file and data management platform capabilities.
