This post has been adapted from a thread from a16z Partner Justine Moore on X. Follow Justine on X for more analysis and observations.
2023 was a breakout year for AI video. At the start of the year, no public text-to-video models existed. Just 12 months later, dozens of video generation products are in active use, with millions of users worldwide creating short clips from text or image prompts.
These products are still relatively limited — most generate 3 to 4 second videos, the outputs tend to be mixed in quality, and things like character consistency have yet to be cracked. We’re still far from being able to create a Pixar-level short film with a single text prompt (or even multiple prompts!).
However, the progress we’ve seen in video generation over the past year suggests that we’re in the early innings of a massive transformation — similar to what we saw in image generation. We’re seeing continued improvements in text-to-video models, as well as offshoots like image-to-video and video-to-video gaining steam.
To help understand this explosion in innovation, we’ve tracked the biggest developments so far, companies to keep an eye on, and the remaining underlying questions in this space.
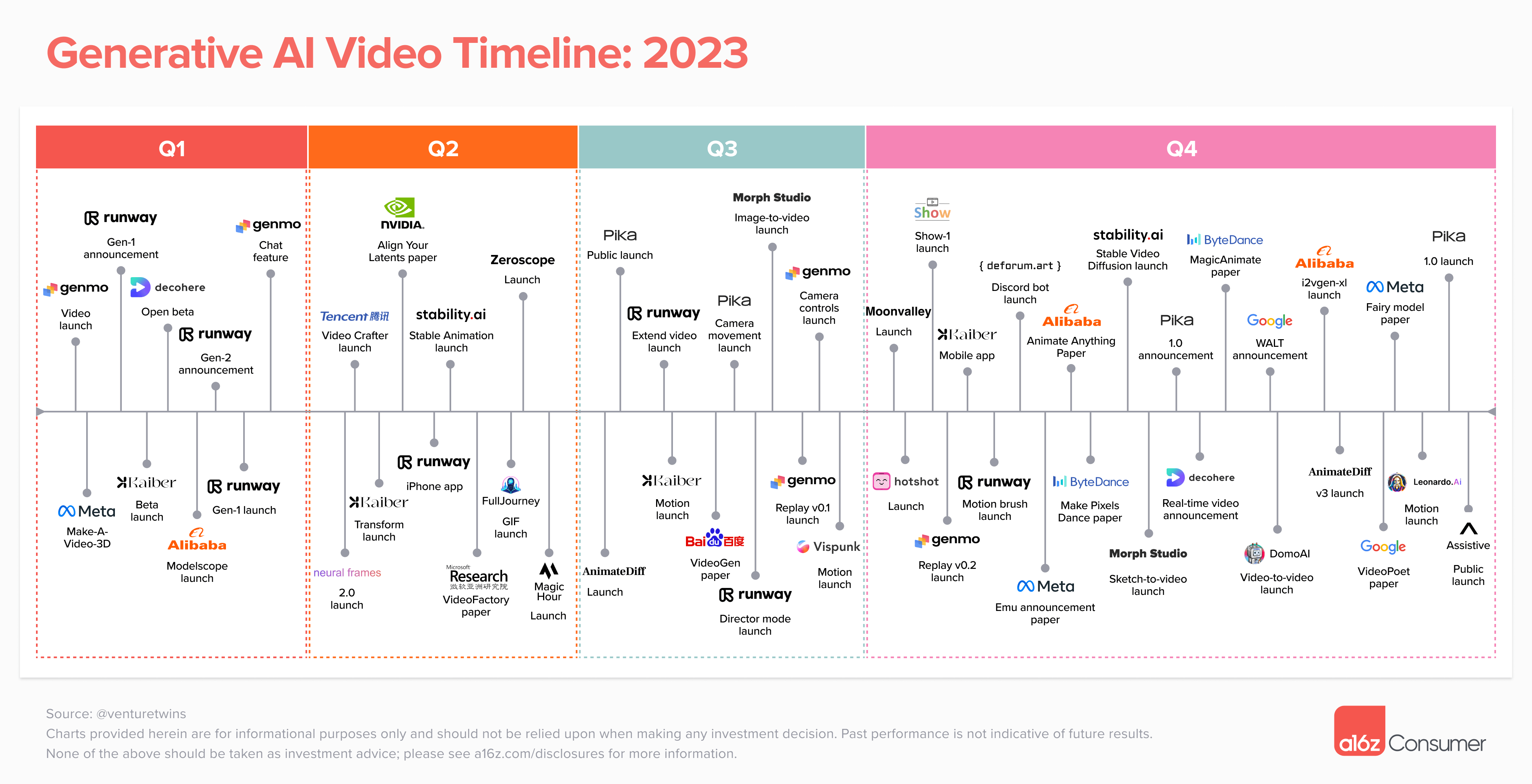
Where can you generate AI video today?
Products
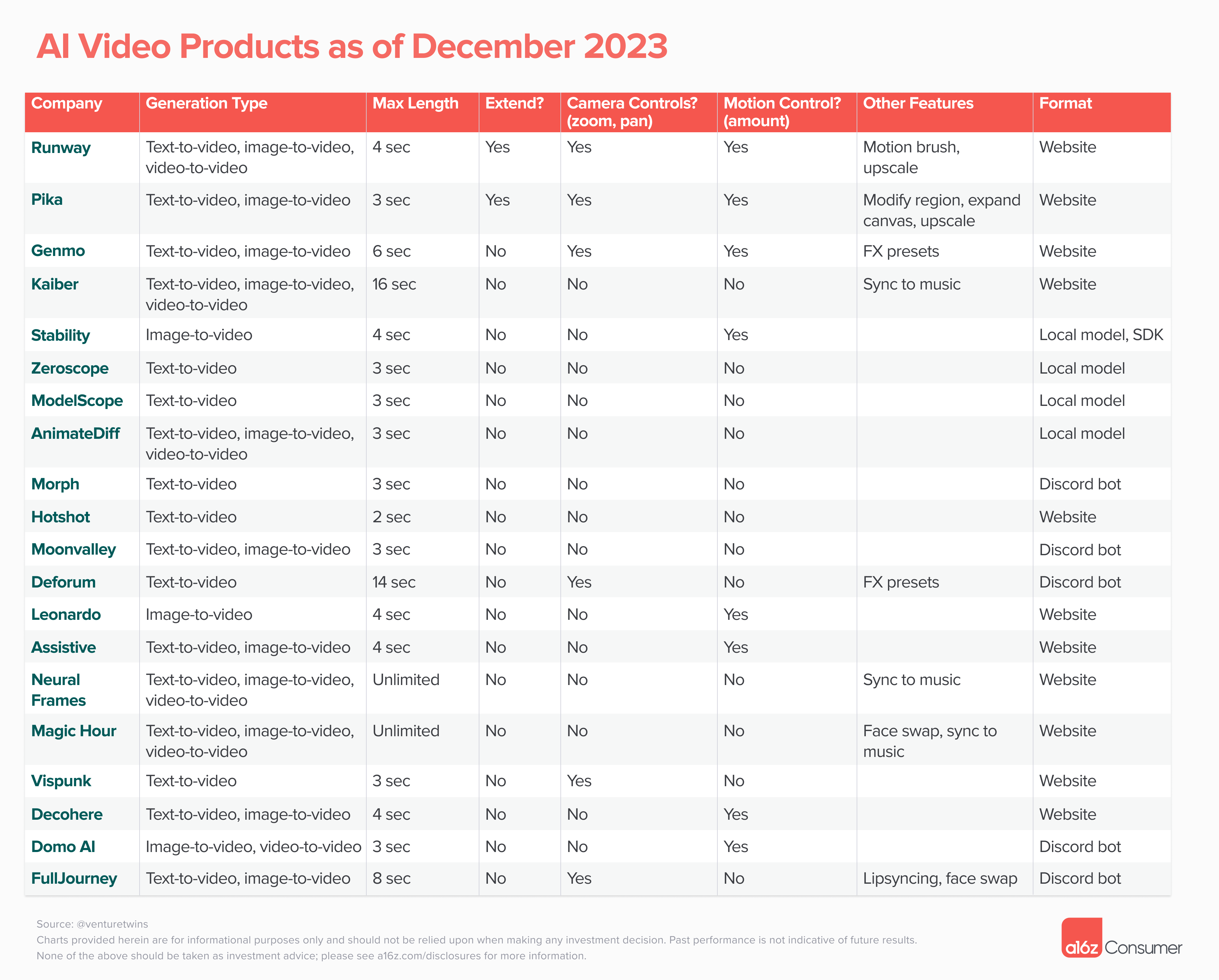
We have been tracking 21 public products so far this year. While you’ve likely heard of Runway, Pika, Genmo, and Stable Video Diffusion, there’s a long list of others to discover.
Most of these products come from startups — many of which begin with Discord bots, which have a few advantages:
- You don’t need to build your own consumer-facing interface, and can focus exclusively on model quality
- You can tap into Discord’s base of 150 million monthly active users for distribution — especially if you get featured on the platform’s “Discover” page
- Public channels provide an easy way for new users to get inspiration on what to create (by seeing what others generate) and provide social proof for the product
However, we’re starting to see more video products build their own websites or even mobile apps, especially as they mature. While Discord provides a good launchpad, it’s limited in terms of the workflow you can add on top of pure generation, and teams have very little control over the consumer experience. It’s also worth noting that there’s a large percentage of the population who don’t use Discord and may find the interface confusing or don’t return to it frequently.
Research and Big Tech
Where are Google, Meta, and others? They’re conspicuously missing from the list of public products — though you may have seen their splashy posts announcing models like Meta’s Emu Video, Google’s VideoPoet and Lumiere, and ByteDance’s MagicVideo.
Thus far, the big tech companies — with the exception of Alibaba — have chosen to not publicly release their video gen products. Instead, they’re publishing papers on various forms of video generation and dropping demo videos without announcing if or when their models will ever be public.
TLDR: Meet ✨Lumiere✨ our new text-to-video model from @GoogleAI!
Lumiere is designed to create entire clips in just one go!
Seamlessly opening up possibilities for many applications:
Image-to-video ?️ Stylized generation ?️ Video editing ? and beyond.See ?? pic.twitter.com/Szj8rjN2md
— Hila Chefer (@hila_chefer) January 24, 2024
These companies all have massive distribution advantages, with billions of users on their products. Why not drop their video models, when their demos look strong and they could have the opportunity to capture meaningful market share in this emerging category?
It’s important to remember that these companies move slowly. Most still haven’t released text-to-image products, though Instagram shipped an AI background generator for Stories late last year, and TikTok has been quietly launching AI filters. Legal, safety, and copyright concerns often make it difficult to convert research into products at these companies and delay rollout — giving newcomers the chance to gain a first-mover advantage.
What’s next for AI video?
If you’ve ever used one of these products, you know that there’s much to be improved before AI video is ready for primetime. Getting a “magic moment” where a model generates a beautiful clip that matches your prompt is possible, but relatively rare. It’s more common that you need to hit re-generate a few times and crop or edit the output to get professional-grade clips.
Most of the companies in this space are focused on tackling a few core (and as of yet unsolved) issues:
- Control — can you control both what happens in a scene (e.g., if you prompt “man walking forward,” is the movement as described?) and how the “camera” moves? On the latter point, a number of products have added features that allow you to zoom or pan the camera or even add special effects.
The former point — is the movement as described? — has been more difficult to tackle. It’s an underlying model quality issue (does the model understand and can it execute on your prompt), though some companies are trying to give users more control pre-generation. Runway’s motion brush is a good example of this, as it allows you to highlight specific areas of an image and determine how they move.
Okay, my new favorite thing to do with Multi Motion Brush is dramatic western inspired squints ?? pic.twitter.com/aFMYaBzJ5b
— Always Generating (@notiansans) January 19, 2024
- Temporal coherence — how can you make characters, objects, and backgrounds stay consistent between frames and not morph into something else or warp? This is a very common problem across all of the publicly available models. If you see a temporally coherent video today that’s longer than a few seconds, it’s likely video-to-video, taking a video and transforming the style with something like AnimateDiff prompt travel.
I experimented with DomoAI to modify the style of a video.
I used small clips of a Tamil song and transformed to Anime style.
I am surprised with how nicely it transformed the original video and also interestingly, it retained the text.
Song: Maari 2 – Rowdy Baby (Wunderbar… pic.twitter.com/dT8ItwPXhY
— Anu Aakash (@anuaakash) January 3, 2024
Video to 70's Cartoon AI exploration. Created with #AnimateDiff and #IPAdapter to stylize input video for a retro cartoon look.
? Result (10fps) vs input (30fps iPhone footage)#aivideo #stablediffusion #ComfyUI
More imagery (and result video by itself) in thread!? pic.twitter.com/i9UDEHtP5h
— Nathan Shipley (@CitizenPlain) December 1, 2023
- Length — can you make clips beyond a couple of seconds? This is highly related to temporal coherence. Many companies limit the length of the videos you can generate because they can’t ensure any kind of consistency after a few seconds. If you see a long-form AI video (like the one below), you’ll notice it’s comprised of a bunch of short clips and required dozens, if not hundreds, of prompts!
Outstanding questions
It feels like AI video is at GPT-2 level. We’ve made big strides in the last year, but there’s still a way to go before everyday consumers are using these products on a daily basis. When will the “ChatGPT moment” arrive for video? There’s no broad consensus among researchers and founders in the field, and a few questions still to be answered:
- Does the current diffusion architecture work for video? Today’s video models are diffusion-based: they essentially generate frames and try to create temporally consistent animations between them (there are multiple strategies to do this). They have no intrinsic understanding of 3D space and how objects should interact, which explains the warping / morphing. For example, it’s not uncommon to see a person walking down a street in the first half of a clip and then melting into the ground in the second — the model has no concept of a “hard” surface. It’s also difficult (if not impossible) to generate the same clip from a different angle due to the lack of 3D conceptualization of a scene.
Some people believe that video models don’t fundamentally need an understanding of 3D space. If they’re trained on enough quality data, they will be able to learn the relationships between objects and how to represent scenes from different angles. Others are convinced that these models will need a 3D engine to generate temporally coherent content, particularly beyond a few seconds.
- Where will the quality training data come from? It’s harder to train video models than other content modalities, largely due to the fact that there’s not as much quality, labeled training data for these models to learn from. Language models are often trained on public datasets like Common Crawl, while image models are trained on labeled datasets (text-image pairs) like LAION and ImageNet.
Video data is harder to come by. While there is no shortage of publicly accessible video on platforms like YouTube and TikTok, it’s not labeled and may not be diverse enough (things like cat clips and influencer apologies are likely overrepresented in the dataset!). The “holy grail” of video data would likely come from studios or production companies, which have long form videos shot from multiple angles that are accompanied by scripts and directions. However, it’s TBD whether they’ll be willing to license this data for training.
- How will these use cases segment between platforms / models? What we’ve seen across almost every content modality is that one model doesn’t “win” for all use cases. For example, Midjourney, Ideogram, and DALL-E all have distinct styles and excel at generating different types of images.
We expect that video will have a similar dynamic. If you test today’s text-to-video and image-to-video models, you’ll notice that they’re good at different styles, types of movement, and scene composition (we’ll show two examples below). The products built around these models will likely further diverge in terms of workflow and serve different end markets. And this doesn’t even include adjacent products that aren’t doing pure text-to-video, but are tackling things like animated human avatars (e.g., HeyGen), VFX (e.g., Wonder Dynamics), and video-to-video (e.g., DomoAI).
Prompt: “Snow falling on a city street, photorealistic”

Genmo

Runway

Stable Video Diffusion

Pika Labs
Prompt: “Young boy playing with tiger, anime style”

Genmo

Runway

Stable Video Diffusion

Pika Labs
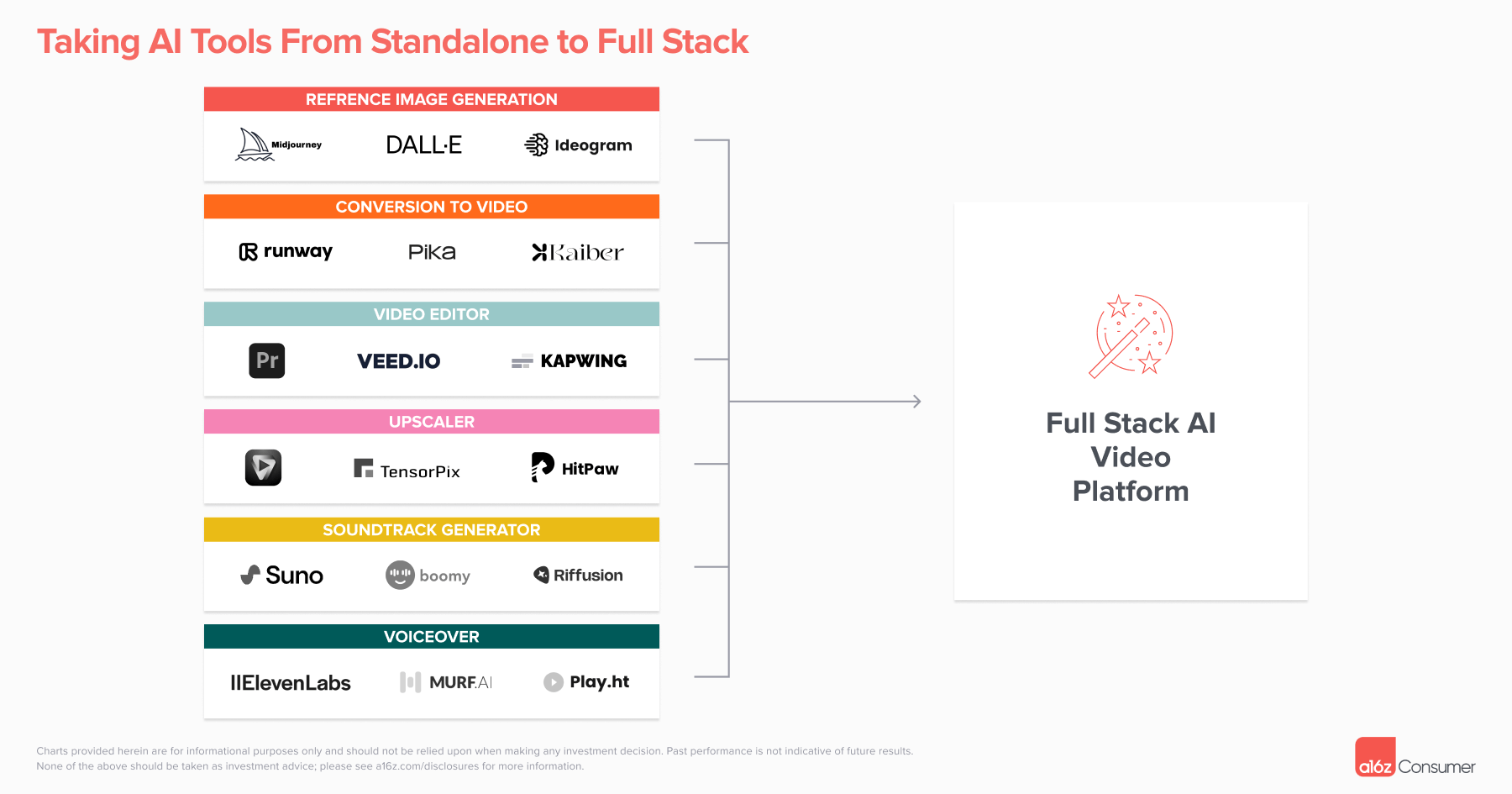
- Who will own the workflow? Beyond pure video generation, making a good clip or film typically requires editing, especially in the current paradigm, where many creators are using video models to animate photos created on another platform. It’s not uncommon to see a video that started as a Midjourney image, got animated on Runway or Pika, and upscaled in Topaz. Creators will then take the video to an editing platform like Capcut or Kapwing and add a soundtrack and voiceover (often generated on other products like Suno and ElevenLabs).
It doesn’t make sense to go back-and-forth between so many products. We expect to see the video generation platforms start to add some of these features themselves. For example, Pika now enables you to upscale video on their site. However, we’re also bullish on an AI-native editing platform that makes it easy to generate content across modalities from different models in one place and piece these things together.
If you’re working on something here, reach out! We’d love to hear from you. You can find me on X at @venturetwins, or email me at jmoore@a16z.com
