For the last few years, visual AI has mostly been judged by its pixels. The better the final image or video looked, the better the model seemed.
That made sense. Diffusion models turned text prompts into beautiful images, then videos, then increasingly realistic worlds. The obvious comparison point was Photoshop or a camera.
But for many visual-related tasks, like graphics design, UI design, or 3D modeling, the end representation users look for is not limited to the end state pixels. Instead, they are looking for artifacts where they can continuously iterate based on feedback and new ideas. A designer does not just need a mockup; they need layers, components, and handoff. An animator does not just need a video; they need timing curves, keyframes, and editable motion. A 3D artist does not just need a rendered picture; they need geometry, materials, lighting, cameras, and scene structure.
The most interesting visual AI tools today have stopped trying to generate the final output. Instead, they’re generating the source code behind it. This change is unlocking editability, iteration, and a feedback loop that pixel-native models can’t match.”
The two stacks of visual generation
There are two major ways to think about visual generation.
The first is pixel-native generation. These systems generate images or videos directly, usually in latent space. They are great at texture, atmosphere, lighting, and realism. If the goal is to generate a cinematic shot, a beautiful moodboard, or a photorealistic image, diffusion models are still the dominant method.
The second is code-native generation. These systems generate a representation that is then executed or rendered by another engine. The model does not directly produce the final pixels; it produces the program that produces the pixels.
That program might be an SVG file, an HTML/CSS layout, a React component, a Lottie JSON file, a Blender script, a USD scene graph, a shader, or a game-engine scene. The visual output is still pixels at the end, but the source of truth is a structured representation.
This distinction matters because production workflows care a lot about what happens after generation. A generated image is useful as an output, but a generated visual program is useful as an artifact – it can be edited, reused, improved, versioned. It can be integrated into the rest of the software stack and validated against constraints. It can be rendered repeatedly under different conditions or be handed off between designers, engineers and agents.
That is the big shift I think is already underway: for a subset of visual problems, we will learn to reframe the visual generation task to a coding task, and get highly efficient improvements from solving a well-defined and validatable coding problem.
Code is a good substrate for visual problems
The easiest way to understand the value of visual code generation is to look at what happens after the first draft.
Say a model generates a logo. If the output is a raster image and one curve is wrong, the user has to mask it, inpaint it, regenerate it, or manually redraw it. Whereas if the output is SVG, the user can edit the path, the primitive, the gradient, the stroke, or the text element. This is already how designers are designing logos on Quiver.





In the realm of UI design, if the output is a screenshot, it is mostly inspiration. If the output is HTML/CSS or React, the designers can inspect the DOM, swap in real components, test responsive states, check accessibility, and wire it into the application.
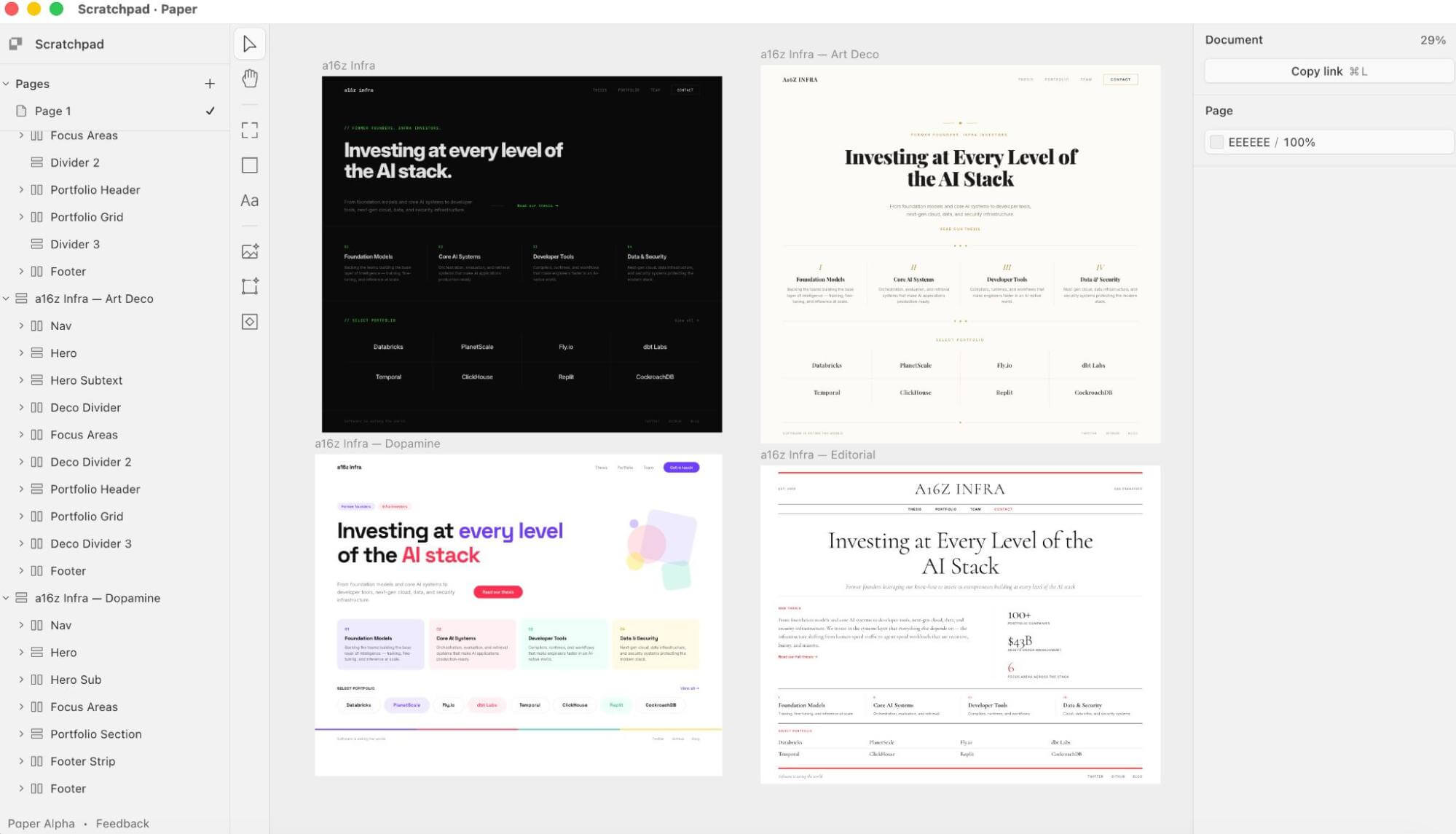
Screenshot from Paper (all visuals are represented by code)
This is also why visual code generation is especially interesting for test-time compute. In pixel-native generation, more inference often means sampling more outputs: generate twenty images, pick the best one, maybe try again. That is useful, but every attempt is mostly a new roll of the dice. The model can respond to feedback, but the feedback is usually global and imprecise.
Technically, diffusion models can also benefit from test-time compute. For example, Inference-time Scaling of Diffusion Models through Classical Search shows that search at inference time can improve diffusion outputs across planning, RL, and image generation. But the loop here is different. In diffusion, the system is usually searching over latent trajectories or finished samples. A reward can tell the model that one output is better than another, but it cannot map feedback cleanly onto a specific source-level edit.
Code-native generation creates a more precise loop:
Code → Render → Inspect → Revise.
The model produces the artifact, renders it, sees what broke, and patches the source. If the spacing is wrong, change the CSS. If a logo curve is off, edit the SVG path. If an animation feels slow, adjust the timing. The key is that every iteration improves the underlying artifact, not just the rendered output. That is why visual code generation is on the direct path of benefiting from generating more tokens and test-time compute. The model is debugging a visual program in a closed-loop, verifiable environment; not just sampling more images.
The visual generation stack with code
Underneath the above examples is this stack:
Coding model + symbolic representation + renderer or engine

The coding model is the author and editor of the artifact. It writes the HTML, SVG, Lottie JSON, Blender script, USD scene, or bespoke 3D asset program.
The symbolic representation is the source of truth. This is what makes the artifact editable. A UI has DOM nodes, layout rules, and components. A Lottie animation has layers, vector shapes, timing curves, keyframes, and motion parameters. A 3D asset has geometry, materials, joints, constraints, and hierarchy.
The renderer or engine turns that structure into pixels. The browser renders HTML/CSS. An SVG renderer renders vectors. A Lottie player renders motion. Blender or a game engine renders 3D scenes. A simulator validates whether an articulated asset can actually move or interact.
OmniLottie is a good example of why the symbolic representation matters. Lottie is a lightweight and JSON-based animation format that represents motion as editable vector shapes, layers, keyframes and timing parameters rather than as a flat video. OmniLottie proposes turning this raw Lottie JSON into a more model-friendly sequence of commands so a model can generate and edit Lottie animations more reliably. The paper is not primarily about building a full agentic loop. Its key move is to make Lottie more model-native: it turns raw Lottie JSON into a compact sequence of commands and parameters that a model can generate. That matters because Lottie is already an editable animation format. Once motion is represented as shapes, layers, timing, and animation parameters, feedback can map to source-level edits. If the object moves too slowly, adjust the timing. If the path is wrong, edit the vector. If the morph is off, update the shape sequence.
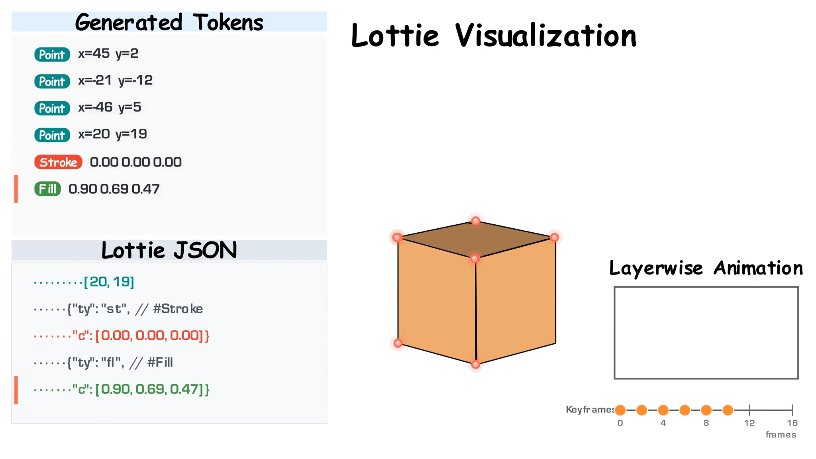
Video from OmniLottie’s project website
The stack corresponds to the test time compute loop the coding agent can run to improve the output quality: at every Code -> Render -> Inspect -> Revise loop, the model is not just generating another sample; it is using the renderer as feedback to improve the underlying artifact. It can change the CSS rule, adjust the SVG path, fix the animation timing, or update the 3D constraint, then render again and continue improving.
This is what gives the loop a chance to converge. In pixel-native generation, each retry often produces a new output. In code-native generation, each retry can improve the source artifact itself. The model is not merely sampling more images or videos; it is debugging a visual program in a closed-loop, renderable environment.
Market map: wedge around runtimes
The market for visual code generation is starting to organize around the runtime where the artifact is rendered or executed. In code-native visual generation, the model is producing a symbolic artifact that gets executed somewhere: in a browser, an SVG renderer, a Lottie player, Blender, a game engine, or a simulator.
Each runtime creates a different wedge, because each one has its own source representation, feedback loop, and production workflow.

The most obvious applications today are in 2D design, especially UI and graphics design. But visual code generation is broader than design tooling. It shows up anywhere the visual artifact has an underlying representation that can be generated, rendered, inspected, and refined.
Why 3D is the next important frontier
While product design and 2D design are the most obvious use cases today, 3D artifacts may be able to benefit the most from reframing its consistency problem to a coding problem.
A 2D design can sometimes be useful if it simply looks right. A 3D asset cannot. A rendered image of a chair is not a chair. It is a picture of a chair. For the asset to be useful in a game, simulation or 3D editing tool, the artifact needs the consistent underlying 3D representation with the right geometry, materials, part hierarchy and scene context.
This is why 3D is a natural fit for visual code generation. The value is not just generating something that looks 3D from one angle, instead it’s generating a consistent 3D structure that holds up across views, edits, and interactions. That requires an iterative loop: propose the object, render it, inspect whether the geometry and parts make sense, then revise the underlying representation. But the loop only works if the agent has the right tools and context as it’s not enough to keep running Blender until something looks better. The agent needs ways to change camera views, query scene state, isolate objects, compare against the target, remember prior attempts, and translate visual discrepancies into source-level edits. That is what gives test-time compute a path to converge.
For many assets, visual consistency is only the baseline. The object also needs the right part semantics and functional constraints: doors should open, hinges should rotate, drawers should slide, wheels should spin. In other words, the output has to be more than a plausible shape. It has to behave like the thing it represents.
This is where projects like VIGA and Articraft3D stood out in the space and we expect to see more work – both commercial and open sourced – to come out this year. VIGA uses Blender as the rendering and feedback environment, turning visual reconstruction into a code-render-inspect loop; VIGA does not just expose raw Blender in a loop. It gives the agent semantic tools for observation and modification, plus memory over prior attempts, so it can inspect from better viewpoints, diagnose what is wrong, and make targeted edits. Articraft3D goes even more directly at asset structure: it frames articulated 3D generation as writing programs that define parts, geometry, joints, and tests.

Example 3D scene reconstruction generated by VIGA
Future implications and unsolved problems
If visual code generation works, the winning products will not just generate prettier outputs. They will own the loop: generate the artifact, render it, inspect what broke, and revise the source.
That has a few implications. First, renderers become feedback environments. The browser, SVG renderer, Lottie player, Blender, game engines, and simulators will become the environments where agents test and improve their work, like how coding agents are leveraging sandboxes and VMs today.
Second, the quality of the iteration context becomes more important than ever. To get an agent into the visual-code equivalent of a “Ralph loop,” the intermediate representation has to be precise enough to guide the next step. The model needs to know not just that something looks wrong, but which part of the source to change and why. Small errors in structure, rendering, or feedback can compound quickly across iterations.
Third, the future is likely to be hybrid. Pixel-native models will still be best for realism, texture, and exploration. Code-native systems will be better for structure, iteration, and production. The most useful workflows will combine both.
There are still open questions. Which representation wins for each domain? Do we need to remake the engines and renderers instead of using what we have from the previous generation? And how much of visual taste can be captured by constraints, tests, and feedback loops?
Still, the direction feels clear: visual AI is moving from outputs to code artifacts. The first wave made it easier to generate images. The next wave will make it easier to generate visual artifacts that can be edited, tested, shipped, and improved.
It’s time to build in this space. If you are building relevant representations, doing research, or have thoughts on how the industry evolves, reach out to yli@a16z.com.
