As an industry, we’ve gotten exceptionally good at building large, complex software systems. We’re now starting to see the rise of massive, complex systems built around data – where the primary business value of the system comes from the analysis of data, rather than the software directly. We’re seeing quick-moving impacts of this trend across the industry, including the emergence of new roles, shifts in customer spending, and the emergence of new startups providing infrastructure and tooling around data.
In fact, many of today’s fastest growing infrastructure startups build products to manage data. These systems enable data-driven decision making (analytic systems) and drive data-powered products, including with machine learning (operational systems). They range from the pipes that carry data, to storage solutions that house data, to SQL engines that analyze data, to dashboards that make data easy to understand – from data science and machine learning libraries, to automated data pipelines, to data catalogs, and beyond.
And yet, despite all of this energy and momentum, we’ve found that there is still a tremendous amount of confusion around what technologies are on the leading end of this trend and how they are used in practice. In the last two years, we talked to hundreds of founders, corporate data leaders, and other experts – including interviewing 20+ practitioners on their current data stacks – in an attempt to codify emerging best practices and draw up a common vocabulary around data infrastructure. This post will begin to share the results of that work and showcase technologists pushing the industry forward.
Data infrastructure includes…
This report contains data infrastructure reference architectures compiled from discussions with dozens of practitioners. Thank you to everyone who contributed to this research!
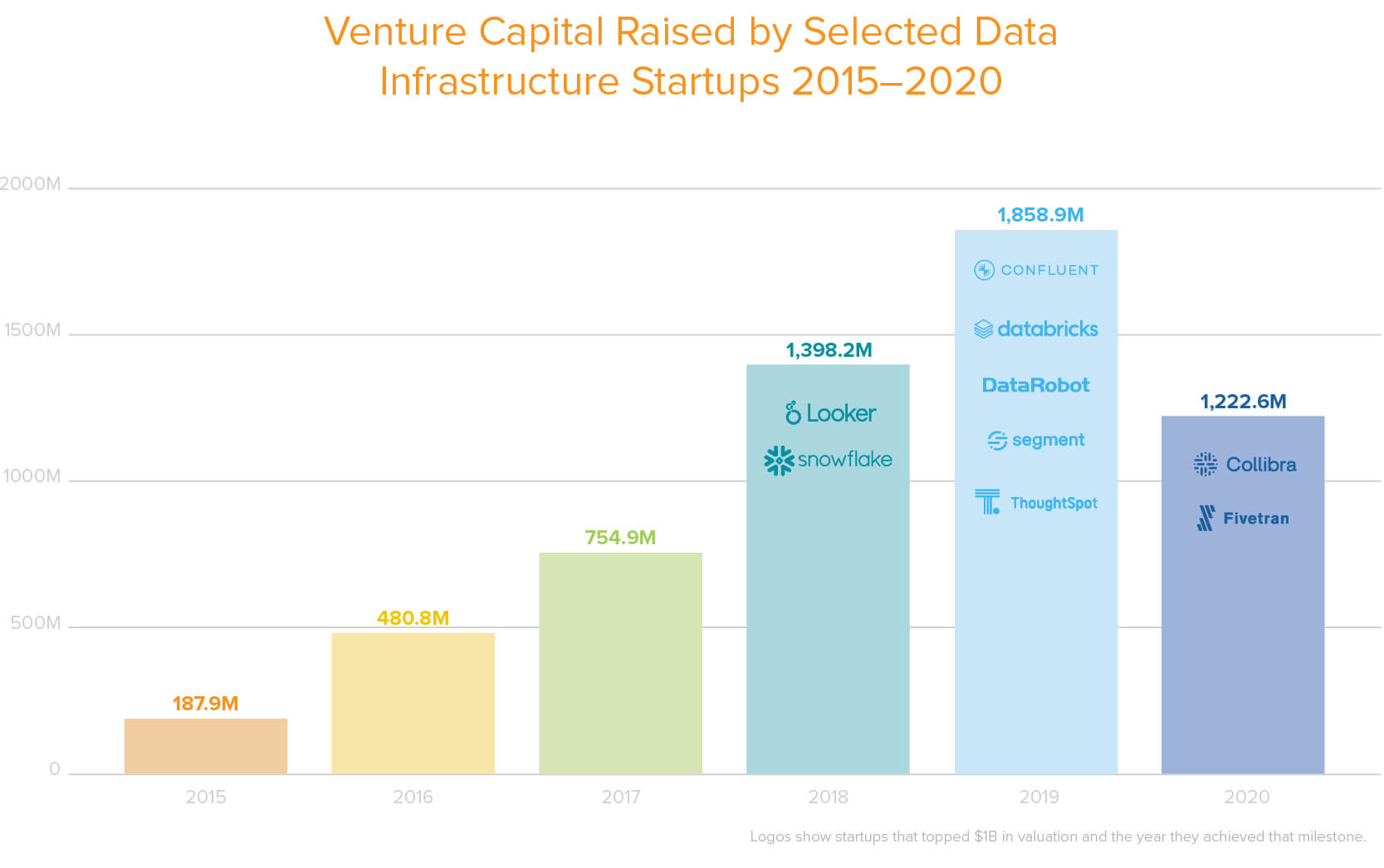
Massive Growth of the Data Infrastructure Market
One of the primary motivations for this report is the furious growth data infrastructure has undergone over the last few years. According to Gartner, data infrastructure spending hit a record high of $66 billion in 2019, representing 24% – and growing – of all infrastructure software spend. The top 30 data infrastructure startups have raised over $8 billion of venture capital in the last 5 years at an aggregate value of $35 billion, per Pitchbook.
Venture capital raised by select data infrastructure startups 2015-2020
The race towards data is also reflected in the job market. Data analysts, data engineers, and machine learning engineers topped Linkedin’s list of fastest-growing roles in 2019. Sixty percent of the Fortune 1000 employ Chief Data Officers according to NewVantage Partners, up from only 12% in 2012, and these companies substantially outperform their peers in McKinsey’s growth and profitability studies.
Most importantly, data (and data systems) are contributing directly to business results – not only in Silicon Valley tech companies but also in traditional industry.

A Unified Data Infrastructure Architecture
Due to the energy, resources, and growth of the data infrastructure market, the tools and best practices for data infrastructure are also evolving incredibly quickly. So much so, it’s difficult to get a cohesive view of how all the pieces fit together. And that’s what we set out to provide some insight into.
We asked practitioners from leading data organizations: (a) what their internal technology stacks looked like, and (b) whether it would differ if they were to build a new one from scratch.
The result of these discussions was the following reference architecture diagram:
Unified Architecture for Data Infrastructure
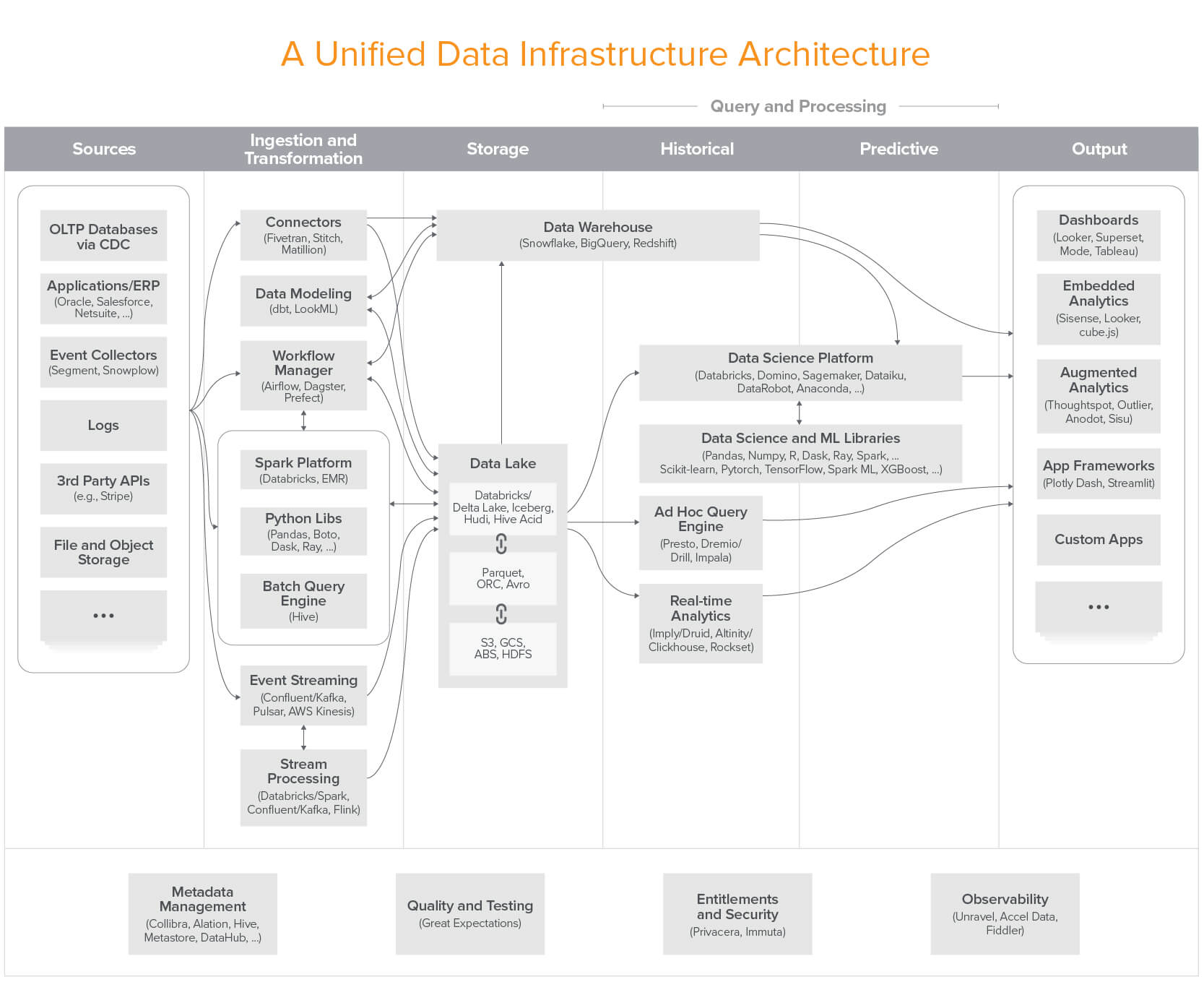
Note: Excludes transactional systems (OLTP), log processing, and SaaS analytics apps. Click here for a high-res version.
The columns of the diagram are defined as follows:
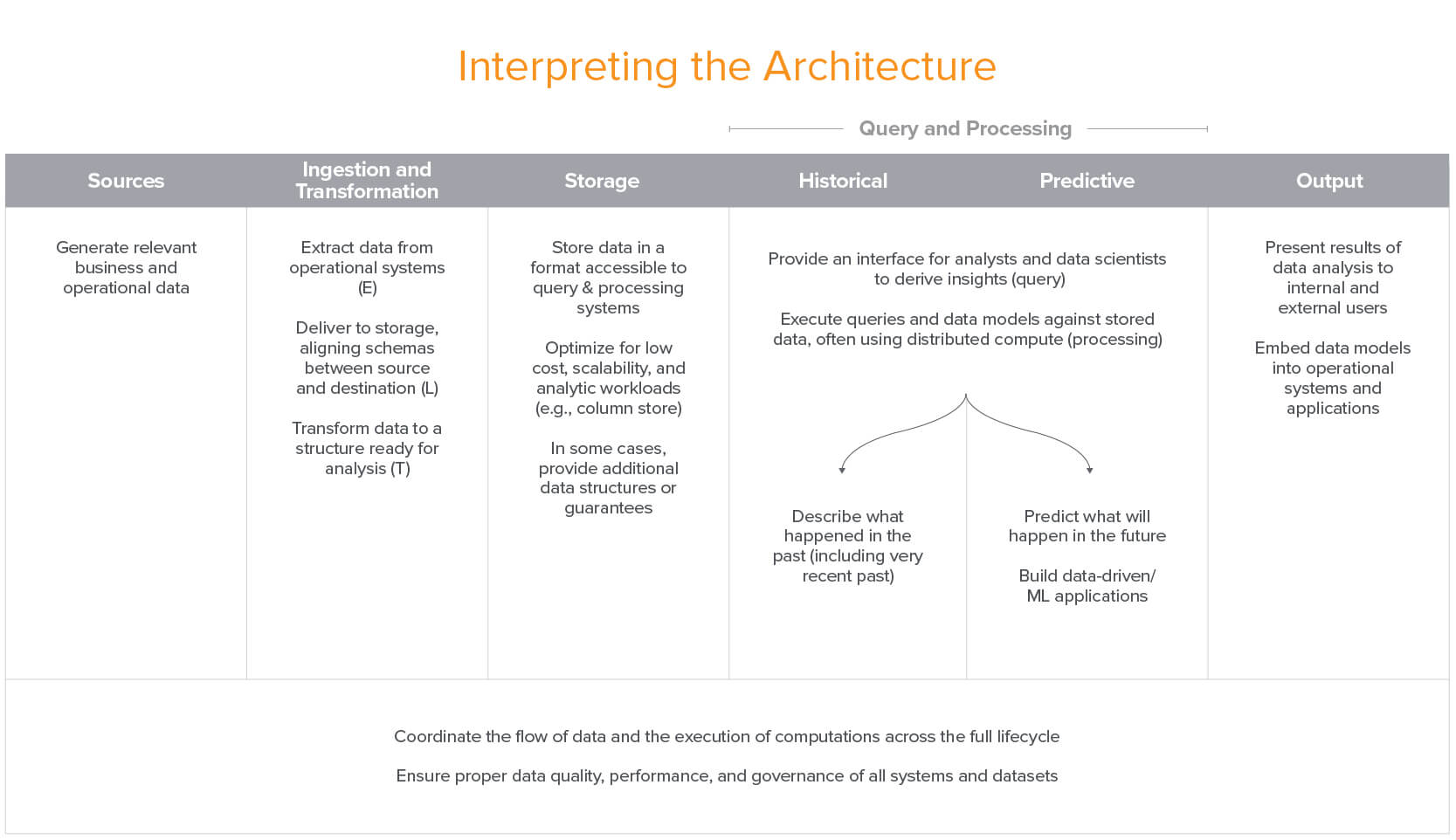
There is a lot going on in this architecture – far more than you’d find in most production systems. It’s an attempt to provide a full picture of a unified architecture across all use cases. And while the most sophisticated users may have something approaching this, most do not.
The rest of this post is focused on providing more clarity on this architecture and how it is most commonly realized in practice.
Analytics, AI/ ML, and the Great Convergence?
Data infrastructure serves two purposes at a high level: to help business leaders make better decisions through the use of data (analytic use cases) and to build data intelligence into customer-facing applications, including via machine learning (operational use cases).
Two parallel ecosystems have grown up around these broad use cases. The data warehouse forms the foundation of the analytics ecosystem. Most data warehouses store data in a structured format and are designed to quickly and easily generate insights from core business metrics, usually with SQL (although Python is growing in popularity). The data lake is the backbone of the operational ecosystem. By storing data in raw form, it delivers the flexibility, scale, and performance required for bespoke applications and more advanced data processing needs. Data lakes operate on a wide range of languages including Java/Scala, Python, R, and SQL.
Each of these technologies has religious adherents, and building around one or the other turns out to have a significant impact on the rest of the stack (more on this later). But what’s really interesting is that modern data warehouses and data lakes are starting to resemble one another – both offering commodity storage, native horizontal scaling, semi-structured data types, ACID transactions, interactive SQL queries, and so on.
The key question going forward: are data warehouses and data lakes are on a path toward convergence? That is, are they becoming interchangeable in the stack? Some experts believe this is taking place and driving simplification of the technology and vendor landscape. Others believe parallel ecosystems will persist due to differences in languages, use cases, or other factors.
Architectural Shifts
Data infrastructure is subject to the broad architectural shifts happening across the software industry including the move to cloud, open source, SaaS business models, and so on. However, in addition to those, there are a number of shifts that are unique to data infrastructure. They are driving the architecture forward and often destabilizing markets (like ETL tooling) in the process.

Emerging Capabilities
A set of new data capabilities are also emerging that necessitate a new set of tools and core systems. Many of these trends are creating new technology categories – and markets – from scratch.

Blueprints for Building Modern Data Infrastructure
To make the architecture as actionable as possible, we asked experts to codify a set of common “blueprints” – implementation guides for data organizations based on size, sophistication, and target use cases and applications.
We’ll provide a high-level overview of three common blueprints here. We start with the blueprint for modern business intelligence, which focuses on cloud-native data warehouses and analytics use cases. In the second blueprint, we look at multimodal data processing, covering both analytic and operational use cases built around the data lake. In the final blueprint, we zoom into operational systems and the emerging components of the AI and ML stack.
Three common blueprints

Blueprint 1: Modern Business Intelligence
Cloud-native business intelligence for companies of all sizes – easy to use, inexpensive to get started, and more scalable than past data warehouse patterns
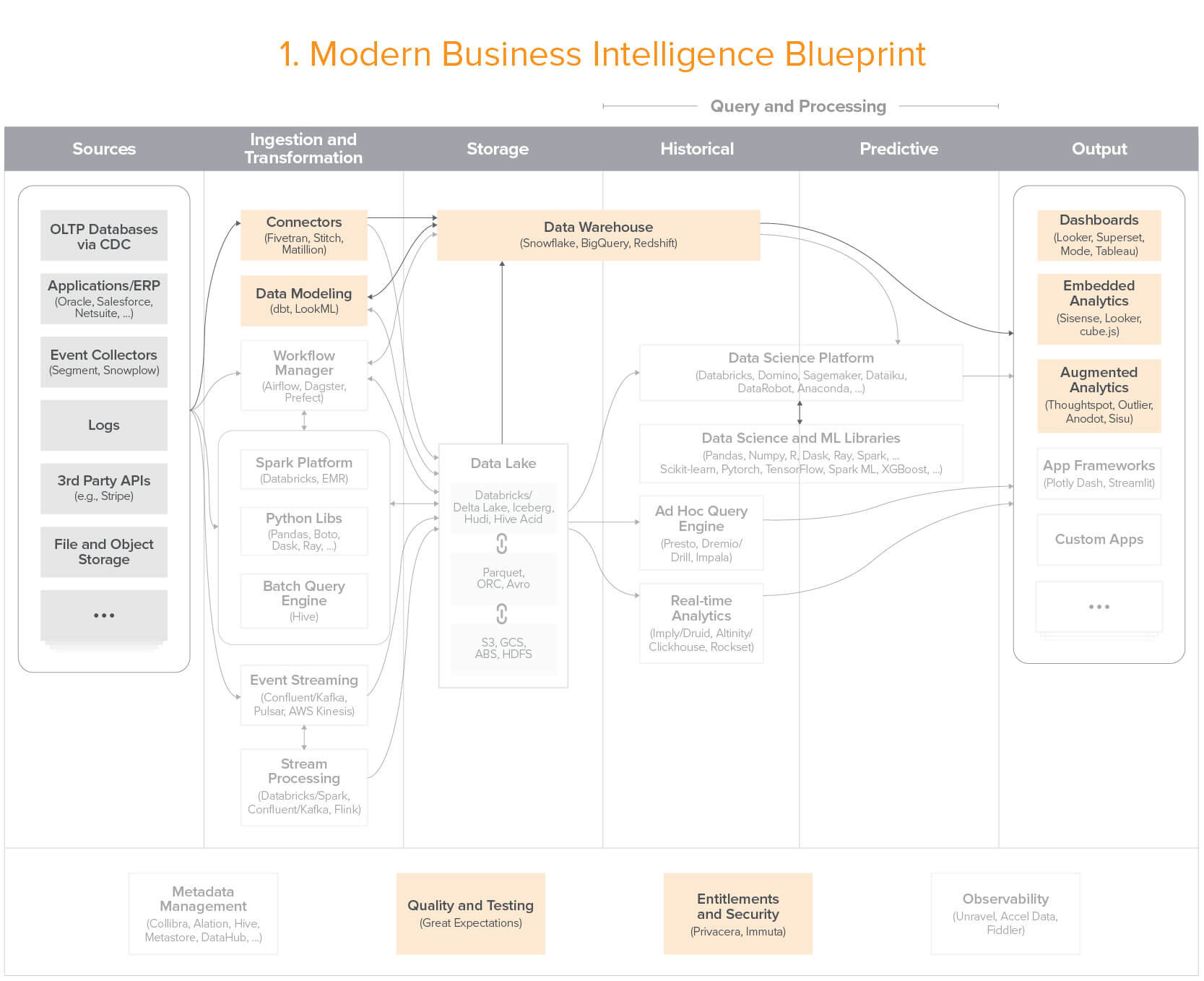
Click here for a high-res version
This is increasingly the default option for companies with relatively small data teams and budgets. Enterprises are also increasingly migrating from legacy data warehouses to this blueprint – taking advantage of cloud flexibility and scale.
Core use cases include reporting, dashboards, and ad-hoc analysis, primarily using SQL (and some Python) to analyze structured data.
Strengths of this pattern include low up-front investment, speed and ease of getting started, and wide availability of talent. This blueprint is less appropriate for teams that have more complex data needs – including extensive data science, machine learning, or streaming/ low latency applications.
Blueprint 2: Multimodal Data Processing
Evolved data lakes supporting both analytic and operational and use cases – also known as modern infrastructure for Hadoop refugees
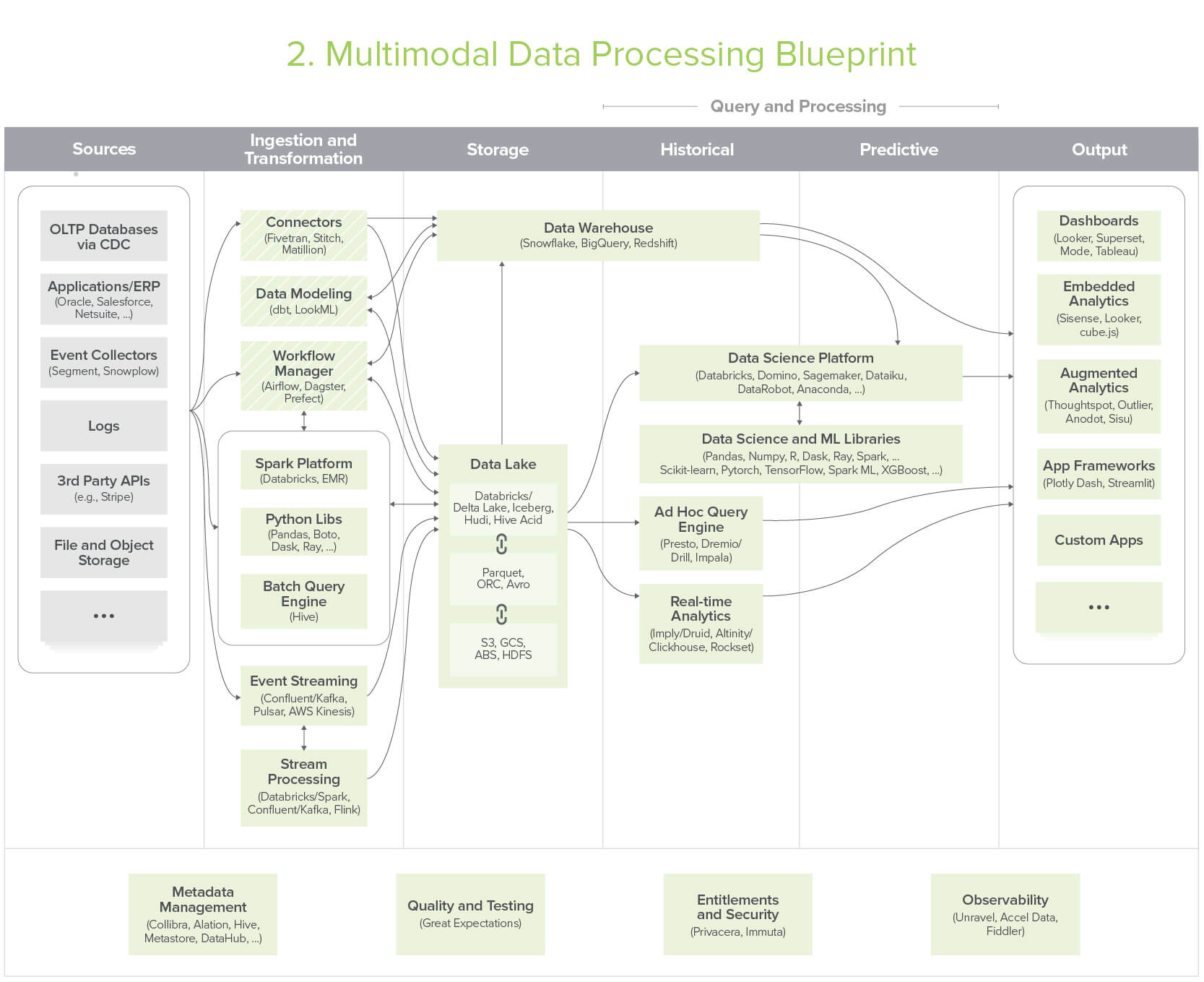
Click here for a high-res version
This pattern is found most often in large enterprises and tech companies with sophisticated, complex data needs.
Use cases include both business intelligence and more advanced functionality – including operational AI/ ML, streaming/ latency-sensitive analytics, large-scale data transformations, and processing of diverse data types (including text, images, and video) – using an array of languages (Java/Scala, Python, SQL).
Strengths of this pattern include the flexibility to support diverse applications, tooling, user-defined functions, and deployment contexts – and it holds a cost advantage for large datasets. This blueprint is less appropriate for companies that just want to get up and running or have smaller data teams – maintaining it requires significant time, money, and expertise.
Blueprint 3: Artificial Intelligence and Machine Learning
An all-new, work-in-progress stack to support robust development, testing, and operation of machine learning models
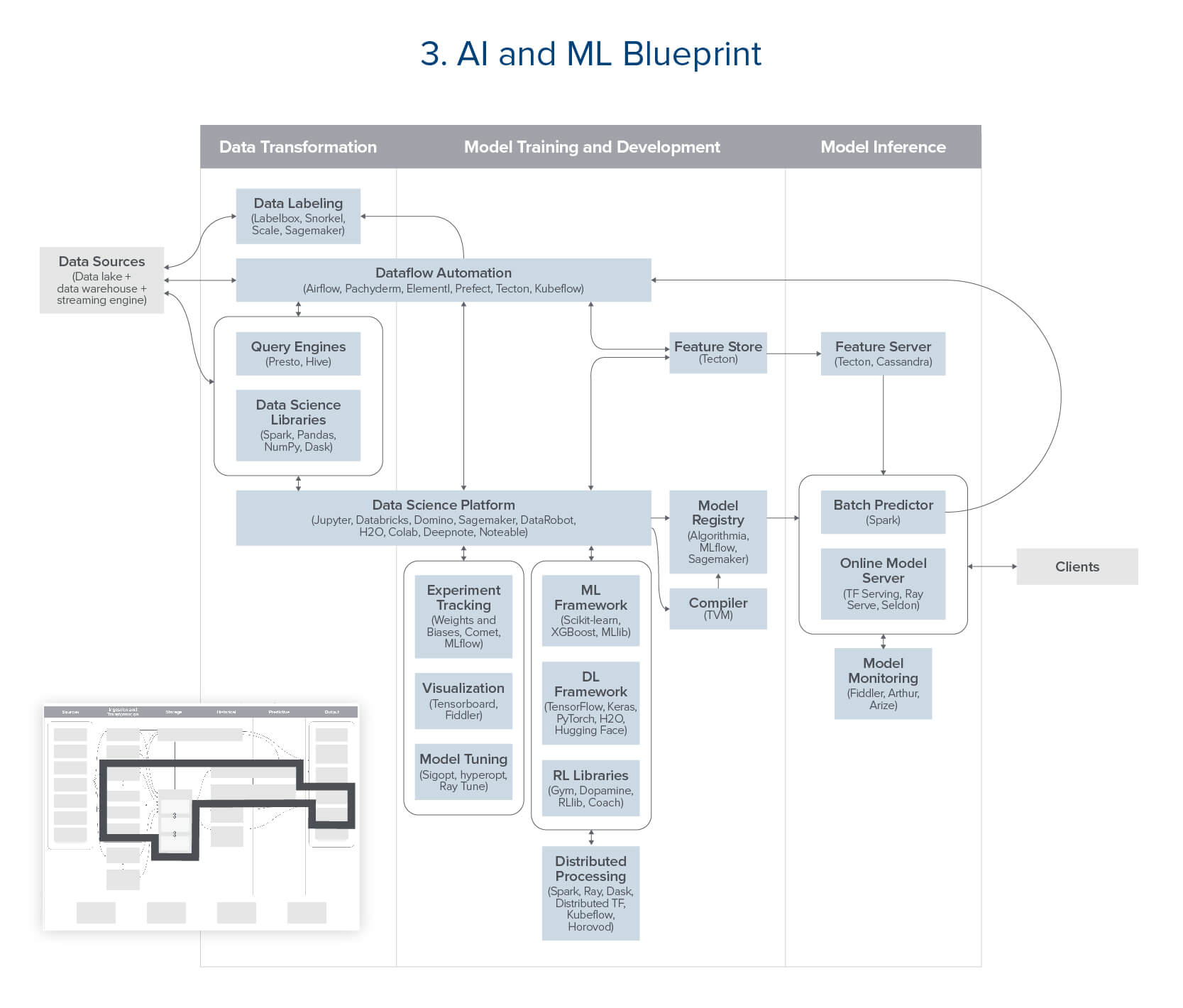
Click here for a high-res version
Most companies doing machine learning already use some subset of the technologies in this pattern. Heavy ML shops often implement the full blueprint, even relying on in-house development for new tools.
Core use cases focus on data-powered capabilities for both internal and customer-facing applications – run either online (i.e., in response to user input) or in batch mode.
The strength of this approach – as opposed to pre-packaged ML solutions – is full control over the development process, generating greater value for users and building AI/ ML as a core, long-term capability. This blueprint is less appropriate for companies that are only testing ML, using it for lower-scale, internal use cases, or opting to rely on vendors – doing machine learning at scale is among the most challenging data problems today.
Looking ahead
Data infrastructure is undergoing rapid, fundamental changes at an architectural level. Building out a modern data stack involves a diverse and ever-proliferating set of choices. And making the right choices is more important now than ever, as we continue to shift from software based purely on code to systems that combine code and data to deliver value. Effective data capabilities are now table stakes for companies across all sectors – and winning at data can deliver durable competitive advantage.
We hope this post can act as a guidepost to help data organizations understand the current state of the art, implement an architecture that best fits the needs of their businesses, and plan for the future amid continued evolution in this space.


