As we look back at 2020 and forward to 2021, we round up our top stories on AI in business, in breakthroughs, in practice. Be sure to subscribe to our enterprise newsletter for monthly updates across all the areas we cover.
TABLE OF CONTENTS
Building AI Businesses
TABLE OF CONTENTS
Much like databases became a core part of software back in the 1980s, we have entered a new era of “AI/ML inside” software. So, what will the business models look like and do the economics (and ways we have of measuring existing software businesses) apply when AI/ML is inside?
The New Business of AI (and How It’s Different from Traditional Software)
The big idea: AI represents a fundamentally new type of business, one that may have lower margins than traditional software businesses. Not to mention a loooong tail of edge cases that makes scaling these businesses challenging. Businesses building software with AI/ML have a bright future, but success begins with understanding how building an AI business is different from traditional software (and managing expectations for others accordingly).
The key questions: Are AI businesses based on data models intrinsically different from software based on code? Or as the market matures, and as the GTM playbook and tooling advance, will AI businesses come to resemble software businesses?
Taming the Tail: Adventures in AI Economics
The big idea: The long tail of edge cases in AI businesses is directly correlated to the complexity of the problem being solved — and the amount of effort needed to tackle it. There are, however, ways to treat the long tail as a first-order concern and build for it. In this followup to “The New Business of AI,” we interviewed dozens of leading AI/ML teams to roundup hard-earned industry secrets for “taming the long tail” of AI. The advice includes: choosing the right problems to work on, narrowing and optimizing global long tails, and emerging techniques for addressing local long tails.
The key questions: The economics of addressing the long tail are directly related to the cost of cloud compute, but how is the cloud cost curve changing? And what does it mean for how we address the long tail of edge cases in AI businesses?
a16z Podcast: Reining in Complexity: Future of AI/ML
The big idea: AI models and data are fluid and complex — more like metaphysics than like typical data management or engineering. “There is no such thing as ‘data’, there’s just frozen models,” argues Anaconda cofounder and CEO Peter Wang. Or perhaps those with physics backgrounds can better appreciate the mind-bending challenges of reining in the natural world, and therefore “get” the unique challenges of AI/ML development, observes a16z general partner Martin Casado. But this is not just a philosophical debate! There are real implications for the margins, organizational structures, and building of AI/ML businesses… especially as we’re in a tricky time of transition, where customers don’t even know what they’re asking for, yet are looking for AI/ML to help and know it’s the future.
The key questions: How does Conway’s Law apply to data organizations? Where does value now accrue in the software value chain?
The Long-Tail Problem and Autonomous Markets
The big idea: AI businesses have a “long tail problem” because they model the complexity of the real world. And the problem is compounded by the nature of neural networks, which are excellent interpolators, but terrible extrapolators. As a result, building AI systems is a problem of coordinating large-scale and widespread data-collection efforts to model the edge cases. Currently, the approach to data collection has been centralized, top-down, and dominated by tech giants… what would it take to approach that data collection bottom up rather than top down?
The key questions: If crypto offers an opportunity for decentralized data collection, how might that give AI startups an edge?
Tooling for Operational AI/ML
With AI/ML inside more software, data is as important as code to how our software functions. Bespoke internal efforts have given way into a set of enterprise-grade data tools. How do these tools come together, and how are they evolving?
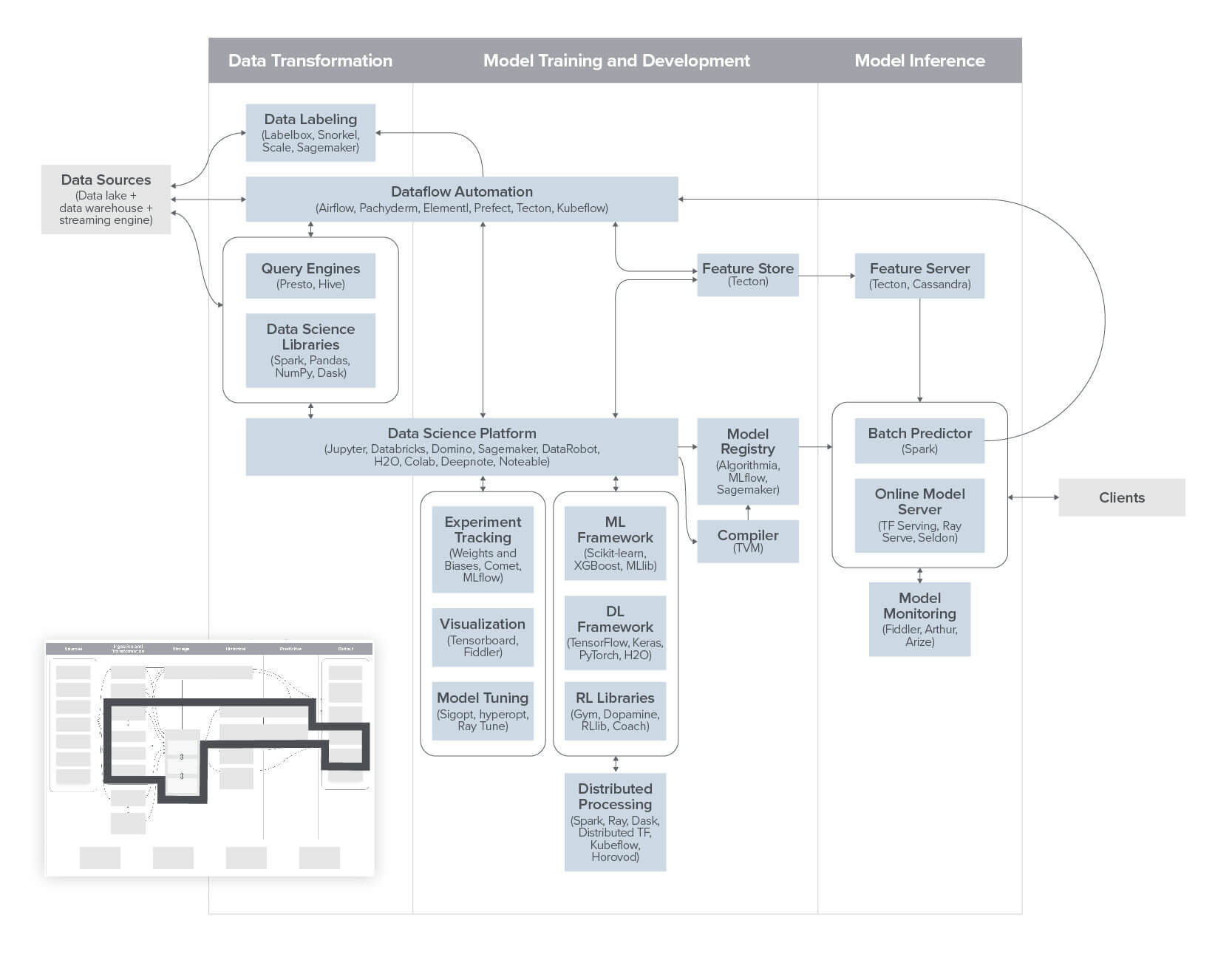
As AI replaces and supplements traditional programming, the rise of a data development toolchain as comprehensive as the software development toolchain is perhaps the most underrated and significant trend in enterprise. -Ben HorowitzThe Emerging Blueprint for Operational ML/AI
The big idea: High-end data science is becoming available to more players, thanks to an explosion of tools for running operational AI/ML reliably in production. These are the systems that run the models that run the business (such as when Lyft or Uber sets the price on a ride). Open source libraries and methodologies have also matured the toolkit and lowered the barrier of entry. In this post, we provide a model architecture for an AI/ML stack — from data transformation to model training, development, and inference.
The key questions: How will incumbents with existing data stacks based on legacy technology adapt?
a16z Podcasts: The Evolution of Data Architectures and The Great Data Debate
The big idea: Data alone is not valuable; it takes a set of tools and systems to collect, process, store, and serve said data. Traditionally, data tools have been architected in two separate, but parallel, ecosystems — data lakes have handled AI/ML, while data warehouses have provided the basis for analytics and BI. But the technical capabilities of data lakes and data warehouses are now converging, enabling new design patterns (e.g., data “lakehouses”) for data infrastructure, where a single, central point of storage can handle both traditional analytic workloads and operational ML/AI. These sets of conversations with leading founders and builders of data infrastructure technologies — dbt, Fivetran, Noteable, Snowflake — as well as with Databricks — explore the past, present, and future of data architectures.
The key questions: Are the separate tools (and teams) that run AI/ML and analytics heading for a great convergence… or will they remain distinct stacks (and markets)?
AI in the News
GPT-3 Beyond the Hype
What happened: In May, GPT-3, the pre-trained machine learning model that’s optimized to do a variety of natural-language processing tasks, was announced in a paper. In July, OpenAI (the R&D company behind GPT-3) released limited, private access to its API, which includes some of the technical achievements behind GPT-3 as well as other models. It was soon followed by a slew of examples and demos of what’s possible with large language models. In September, OpenAI licensed GPT-3 technology to Microsoft.
Why it matters: GPT-3 allows those using it to sidestep some (though not all) of the economic costs of training data and building AI businesses. This makes natural language processing (NLP) one of the most promising areas of AI R&D. NLP is following a well-worn arc of computer science, argues a16z operating partner Frank Chen: a fundamental data/algorithm breakthrough leads to very creative startups or products, but these breakthroughs take a few years to disseminate everywhere, since the future is unevenly distributed. In 2017, we saw the first transformer models trained on large language data sets; this year, we had GPT-3. Then come the startups, followed by techniques to get state-of-the-art NLP inside all software.
The key questions: What are the implications of GPT-3 for startups, incumbents, and the future of “AI-as-a-service”? Where are we on the path to artificial general intelligence, and how do we even know (if not with a Turing Test)? What are the broader questions, considerations, and implications for future jobs?
Regulating AI
What happened: The White House Office of Management and Budget, the OMB, and the Office of Science and Technology Policy, the OSTP, issued a draft memorandum with a set of 10 broadly defined principles for the “stewardship of AI applications.” The policy gave federal agencies 180 days to submit explanations for how their proposed regulations satisfied these principles.
Why it matters: The U.S. is the leader in AI, but other nations, most notably China, are investing heavily in AI, too.
The key question: Is AI the new innovation space race? U.S. policy leaders want to improve trust and limit regulatory overreach in the space. But what does “regulating” AI even mean?
Nvidia + Arm Merger
What happened: Nvidia announced its intent to acquire Arm. Nvidia makes GPUs, the type of compute most often used for ML; Arm makes system-on-chips inside billions of devices with an architecture that optimizes for low energy and low cost.
Why it matters: This represents the culmination of three big tech trends in the last decade of computing: cloud native, mobile first, and machine learning.
The key questions: If value is always moving up the stack — and the divisions between hardware, software, firmware, applications, etc. don’t remain stable for a very long time — who are the players that are changing the game here? And what if it’s the entire gameboard that’s changed?
Spotlight: AI in Bio
AI has promising applications for some of the most important open problems in bio. For instance, better and more sophisticated models can tie together disparate data sets to improve drug discovery and clinical trials; new ML techniques have the potential to improve our predictions, modeling, and simulation in everything from how a cell works to how a global pandemic will unfold; and AI/ML could eventually even help us map and reverse-engineer neuro-complexity to better understand diseases like Alzheimer’s. So, what were this year’s big research breakthroughs and its implications for bio and healthcare?
Solving Baumol’s Cost Disease, in Healthcare
The big idea: Baumol’s Cost Disease arguably explains why services that depend on specialized labor, like healthcare and education, get more expensive, while goods, such as socks and electronics, get cheaper. And unlike in other areas where software has penetrated to drive costs down by turning services into goods, it’s been slow to do so in healthcare.
The key question: Could AI finally bring a dramatic cost savings and allow human workers to focus on higher order care and more?
16 Minutes: AlphaFold! Protein Folding, Beyond the Hype
What happened: This month, Google DeepMind’s AlphaFold system outperformed 100 teams across 20 countries in the biannual challenge to predict the 3-D structures of proteins from amino acid sequences alone.
Why it matters: Proteins define and power all living things, but the astronomical number of possible structures for proteins — and difficulty of figuring these out (whether experimentally or computationally) — has made it one of the grand challenges in biology. This is the first year that deep learning system outperformed other approaches, with accuracy comparable to (and even faster than) lab experiments.
The key questions: Is this the “ ImageNet” moment for AI in bio? Will AlphaFold be like GPT-3 or TensorFlow in practice? What does it mean for the future of drug discovery and other applications?
a16z Journal Club: Finding new antibiotics with ML
What happened: A deep neural network was trained to predict antibiotics and, after looking at one billion compounds, discovered antibiotics with structures that were totally unique amongst known antibiotics.
Why it matters: The study demonstrates that AI can be really useful in lead compound identification, by scanning across a huge set of potential candidates and then escalating the most promising for hands-on validation by scientists. By bringing the cost of discovery down, it opens the door for startups and academic labs to go after use cases that may have been cost-prohibitive before.
The key questions: Where else in drug discovery and development is there the potential to apply the combination of deep learning neural nets for identification with human validation?
—
