It’s hard to understand new software infrastructure technologies without using them. At least, that’s what the a16z infrastructure team has found— and because so many of us started our careers as programmers, we’re often learning by doing. This has particularly been the case with the generative AI wave that has come so fast, and so spectacularly, that good documentation often lags code by months. So to better understand the field ourselves, we’ve been building projects around large language models (LLMs), large image models, vector databases, and the like.
In doing so, we’ve noticed that because all of this is so new, and changing so fast, there really aren’t good frameworks for getting started quickly. Every project requires a bunch of boilerplate code and integration. Frankly, it’s a pain. So, we set out to create a very simple “getting started with AI” template for those who want to play around with the core technologies, but not have to think too much about the long tail of ancillary concerns like auth, hosting, and tool selection.
You can fork and deploy the template here. And we’d love to hear your thoughts and feedback to make the template even better.
The components
Many of us are JavaScript/TypeScript enthusiasts, so we chose the JavaScript stack as our starting point. Although, this framework can easily be modified to support other languages, and we plan to do this shortly.
Here’s a brief overview of the getting-started stack we put together with longtime collaborator and open source enthusiast Tim Qian. The goal is to highlight the simplest path from pulling code on GitHub to a running generative AI app (both image and text). It’s designed to be easily extended to more sophisticated architectures and projects:
- Auth: Clerk
- App logic: Next.js
- Vector database: Pinecone / Supabase pgvector
- LLM orchestration: Langchain.js
- Image model: Replicate
- Text model: OpenAI
- Deployment: Fly.io
For a more detailed overview of the emerging LLM stack, check out our post titled “Emerging Architectures for LLM Applications”.
Models and inference
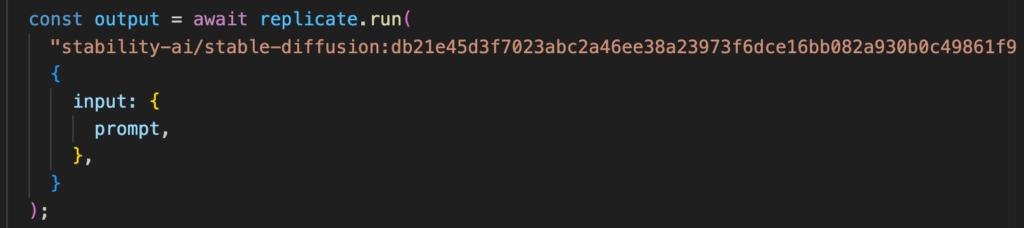
Model hosting is a pain, and largely an orthogonal problem to building an AI app. So we built ours using OpenAI for text and Replicate for image inference. Replicate also provides text-based models (check out how easy it is to run Vicuna), so you can use it in place of OpenAI if desired.
 Authentication
Authentication
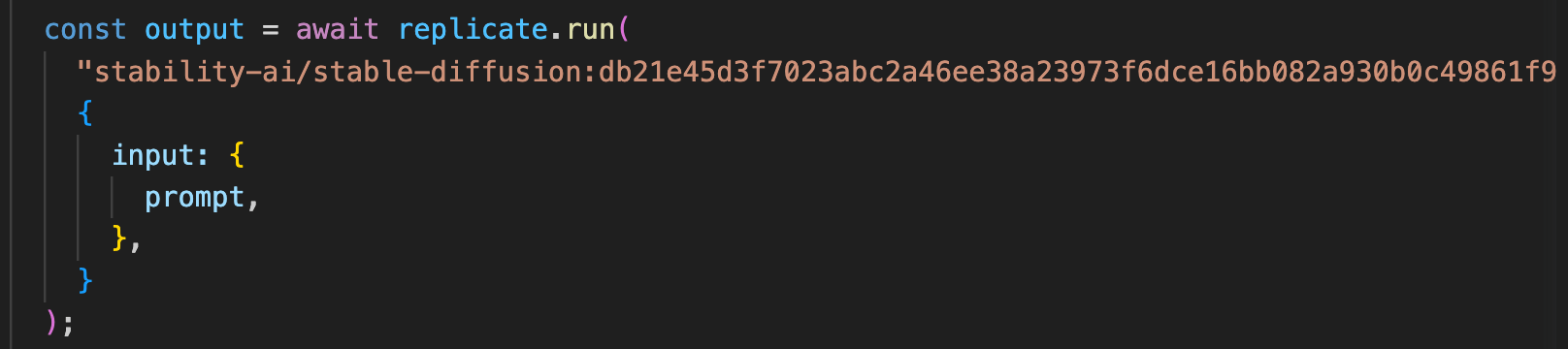
For a starter framework, we normally wouldn’t bother to include auth. But, in this case, the models are so powerful and so general that they are the target of large, organized efforts designed to obtain free usage. Developers often learn this the hard way when a surprise $10,000 bill shows up from their model provider. That’s why we choose to include Clerk, which does the heavy lifting on bot detection, and of course provides full auth support if you end up building a more sophisticated app.
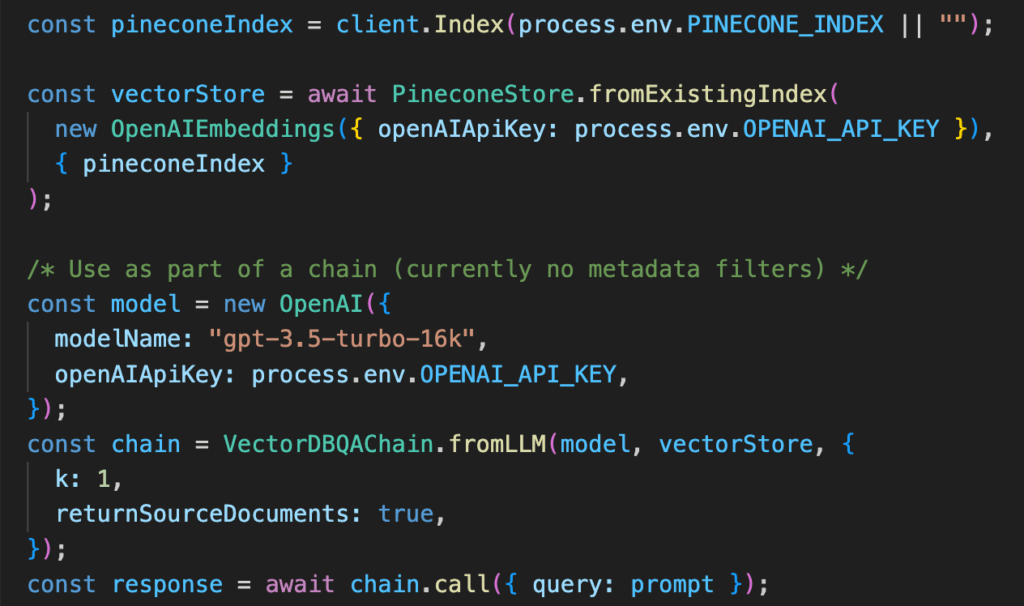
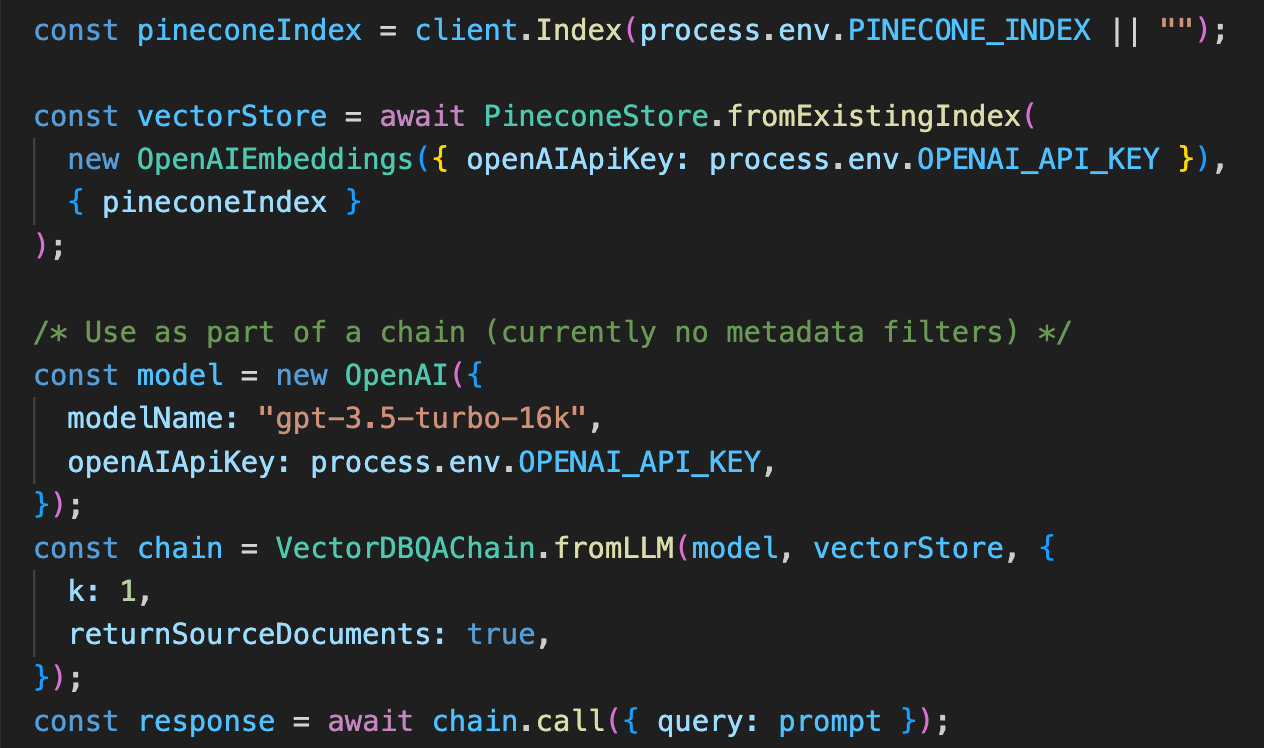
 Vector database
Vector database
LLMs require a solid long-term memory to preserve state and work around the context window; this is handled by a vector database. Currently, Pinecone is the most mature and popular vector store with the generative AI crowd. That said, we want to provide support for all use cases and preferences, so we also included support for pg-vector from Supabase in the repo.
 Deployment
Deployment
For deployment we use Fly.io because it’s multi-region, simple to manage, and provides a very general compute environment (anything that runs in a container). Over time, many AI projects end up using multiple languages, and/or having non-trivial functionality in the back end, so Fly.io is a good compromise between a JavaScript-native hosting environment like Vercel or Netlify and a traditional cloud. That said, the code easily supports other hosting environments if that’s the route you want to go. Fly.io will also soon be offering GPUs for cases where you want to host your own models.
Roadmap
Although we think this first iteration is a good starting point, we’re in the process of fleshing out the stack with more options. Here’s a glimpse of our roadmap:
- An interactive CLI for create-ai-stack, where developers can choose their own project scaffold and dependencies
- Transactional databases for advanced use cases (e.g., retaining questions in Q&A, user preferences, etc.)
- More options for vector databases and deployment platforms
- A lightweight fine-tuning step for open source models
We’d love for you to open PRs for bug fixes, feature requests, and feedback. We are excited to contribute back to the open source community, and we believe the ecosystem always wins.
We extend our gratitude to the following open source projects that were instrumental in the creation of our AI Getting Started stack. These indispensable tools have simplified intricate tasks, making them easier to handle. It is through their tireless work and invaluable contributions that the JavaScript ecosystem continues to flourish and thrive!


